BIRCH 聚类
什么是 BIRCH 聚类?
- 一种用于大规模数据集的聚类算法。它通过构建聚类特征树(CF-tree)来有效地进行聚类,同时对内存使用进行了优化。BIRCH 特别适合于数据集无法全部装入内存的情况,因为它可以在磁盘和内存之间高效地移动数据
![]()
- 为给定数据构建称为聚类特征树 (CFT) 的树。数据本质上是有损压缩到一组聚类特征节点(CF 节点)。CF 节点有许多子集群,称为聚类特征子集群(CF 子集群),这些位于非终端 CF 节点中的 CF 子集群可以将 CF 节点作为子节点
1
2
3
4
5
6
7>>> from sklearn.cluster import Birch
>>> X = [[0, 1], [0.3, 1], [-0.3, 1], [0, -1], [0.3, -1], [-0.3, -1]]
>>> brc = Birch(n_clusters=None)
>>> brc.fit(X)
Birch(n_clusters=None)
>>> brc.predict(X)
array([0, 0, 0, 1, 1, 1])

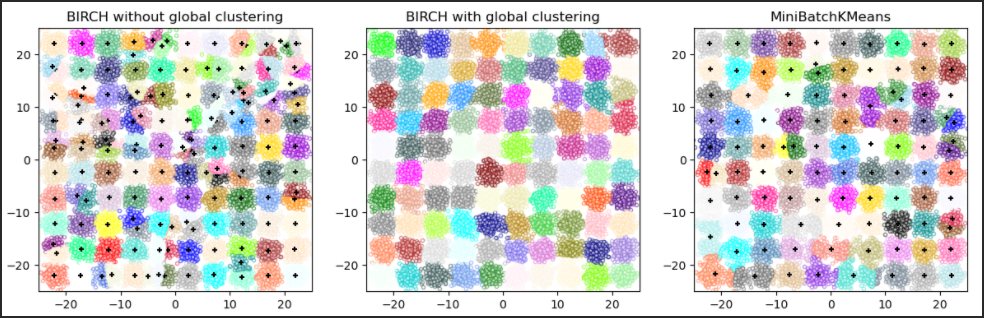
BIRCH 与 MiniBatchKMeans 的差异?
![]()
- BIRCH 不能很好地扩展到高维数据。根据经验,如果 大于 20,通常最好使用 MiniBatchKMeans
- 如果需要减少数据实例的数量,或者如果需要大量子集群作为预处理步骤或其他方式,BIRCH 比 MiniBatchKMeans 更有用