XGBoost-eXtreme_Gradient_Boosting
什么是 XGBoost(eXtreme Gradient Boosting)?
- XGBoost 是一种优化的分布式梯度提升库,全称为 eXtreme Gradient Boosting。它是基于决策树的集成机器学习算法,使用梯度提升框架和正则化项来控制模型复杂度和防止过拟合。XGBoost 在处理大规模数据时表现出色,是目前最快最好的开源 boosting tree 工具包之一
![]()
观察增益 gain, alpha 和 gamma 越大,增益越小?
- XGBoost 寻找分割点的标准是最大化 gain,考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,XGBoost 实现了一种近似的算法。
- 大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中计算 Gain 按最大值找出最佳的分割点。它的计算公式分为四项,可以由正则化 (regularization) 项参数调整 (lamda 为叶子权重平方和的系数,gama 为叶子数量)
![]()
- 第一项是假设分割的左孩子的权重分数,第二项为右孩子,第三项为不分割总体分数,最后一项为引入一个节点的复杂度损失。
- 由公式可知,gama 越大 gain 越小,lamda 越大,gain 可能小也可能大。
- 原问题是 alpha 而不是 lambda, 这里 paper 上没有提到,XGBoost 实现上有这个参数。上面是我从 paper 上理解的答案,下面是搜索到的
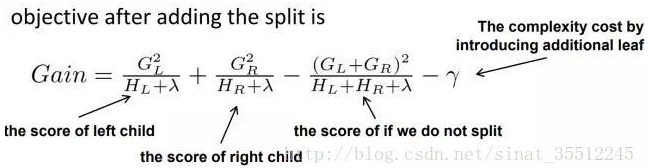
为什么 XGBoost(eXtreme Gradient Boosting) 要用泰勒展开,优势在哪里?
- XGBoost 使用了一阶和二阶偏导,二阶导数有利于梯度下降的更快更准。使用泰勒展开取得二阶倒数形式,可以在不选定损失函数具体形式的情况下用于算法优化分析
- 本质上也就把损失函数的选取和模型算法优化 / 参数选择分开了。这种去耦合增加了 XGBoost 的适用性
XGBoost(eXtreme Gradient Boosting) 怎幺处理缺失值?
- xgboost 处理缺失值的方法和其他树模型不同。xgboost 把缺失值当做稀疏矩阵来对待,本身的在节点分裂时不考虑的缺失值的数值。缺失值数据会被分到左子树和右子树分别计算损失,选择较优的那一个。如果训练中没有数据缺失,预测时出现了数据缺失,那么默认被分类到右子树
- 这样的处理方法固然巧妙,但也有风险:假设了训练数据和预测数据的分布相同,比如缺失值的分布也相同,不过直觉上应该影响不是很大
XGBoost(eXtreme Gradient Boosting) 怎么给特征评分?
- 在训练的过程中,通过 Gini 指数选择分离点的特征,一个特征被选中的次数越多,那么该特征评分越高
XGBoost(eXtreme Gradient Boosting) 如何寻找最优特征?是又放回还是无放回的呢?
- XGBoost 在训练的过程中给出各个特征的评分,从而表明每个特征对模型训练的重要性
- XGBoost 利用梯度优化模型算法,样本是不放回的 (想象一个样本连续重复抽出,梯度来回踏步会不会高兴)。但 XGBoost 支持子采样,也就是每轮计算可以不使用全部样本
LightGBM (Light Gradient Boosting Machine) 与 XGBoost(eXtreme Gradient Boosting)
- lightgbm: 基于 Histogram 的决策树算法;Leaf-wise 的叶子生长策略;Cache 命中率优化;直接支持类别特征(categorical Feature)
- xgboost: 预排序;Level-wise 的层级生长策略;特征对梯度的访问是一种随机访问