堆叠算法 - Stacking
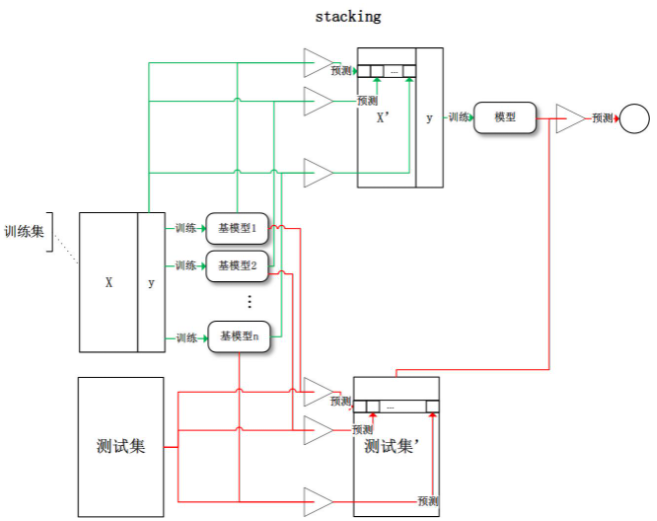
Stacking 就是堆叠模型,在 N 个类别的建模中,可能先建立 K<N 个类别的模型,然后根据前一模型输出叠加多层解决其他类别,类似分层解决 “易分 -> 难分” 的问题
什么是堆叠算法 (Stacking)?
![]()
- Stacking 将前一轮学习之后的输出 / 标签组织变换后作为下一轮学习的输入 / 特征,然后再次训练
- 叠加概括是一种结合估计器以减少其偏差的方法 [W1992] [HTF]。更确切地说,每个单独的估计器的预测被堆叠在一起,并作为最终估计器的输入来计算预测值。这个最终估计器是通过交叉验证训练出来的
在 sklearn 中,堆叠泛化如何应用于分类任务?
- 叠加归纳包括叠加单个估计器的输出,并使用分类器来计算最终预测。叠加允许利用每个单独的估计器的力量,将其输出作为最终估计器的输入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22>>> from sklearn.datasets import load_iris
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.svm import LinearSVC
>>> from sklearn.linear_model import LogisticRegression
>>> from sklearn.preprocessing import StandardScaler
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.ensemble import StackingClassifier
>>> X, y = load_iris(return_X_y=True)
>>> estimators = [
... ('rf', RandomForestClassifier(n_estimators=10, random_state=42)),
... ('svr', make_pipeline(StandardScaler(),
... LinearSVC(random_state=42)))
... ]
>>> clf = StackingClassifier(
... estimators=estimators, final_estimator=LogisticRegression()
... )
>>> from sklearn.model_selection import train_test_split
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, stratify=y, random_state=42
... )
>>> clf.fit(X_train, y_train).score(X_test, y_test)
0.9...
在 sklearn 中,堆叠泛化如何应用于回归任务?
- 叠加概括包括叠加单个估计器的输出,并使用一个回归器来计算最终的预测结果。叠加允许利用每个估计器的力量,将其输出作为最终估计器的输入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21>>> from sklearn.datasets import load_diabetes
>>> from sklearn.linear_model import RidgeCV
>>> from sklearn.svm import LinearSVR
>>> from sklearn.ensemble import RandomForestRegressor
>>> from sklearn.ensemble import StackingRegressor
>>> X, y = load_diabetes(return_X_y=True)
>>> estimators = [
... ('lr', RidgeCV()),
... ('svr', LinearSVR(random_state=42))
... ]
>>> reg = StackingRegressor(
... estimators=estimators,
... final_estimator=RandomForestRegressor(n_estimators=10,
... random_state=42)
... )
>>> from sklearn.model_selection import train_test_split
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, random_state=42
... )
>>> reg.fit(X_train, y_train).score(X_test, y_test)
0.3...