Pose Attention:Multi-Context Attention for Human Pose Estimation
Pose Attention 是一个基于 hourglass 改进的网络,主要创新是同时结合了整体注意力和肢体部分注意力,整体注意力针对的是整体人体的全局一致性,部分注意力针对不同身体部分的详细描述。因此,能够处理从局部显著区域到全局语义空间的不同粒度内容,同时引入条件随机场 (CRF) 来进行空间相关建模,而不是使用全局 Softmax
什么是 Pose Attention ?
![]()
- Pose Attention 是一个基于 hourglass 改进的网络,主要创新是同时结合了整体注意力和肢体部分注意力,整体注意力针对的是整体人体的全局一致性,部分注意力针对不同身体部分的详细描述。因此,能够处理从局部显著区域到全局语义空间的不同粒度内容,同时引入条件随机场 (CRF) 来进行空间相关建模,而不是使用全局 Softmax
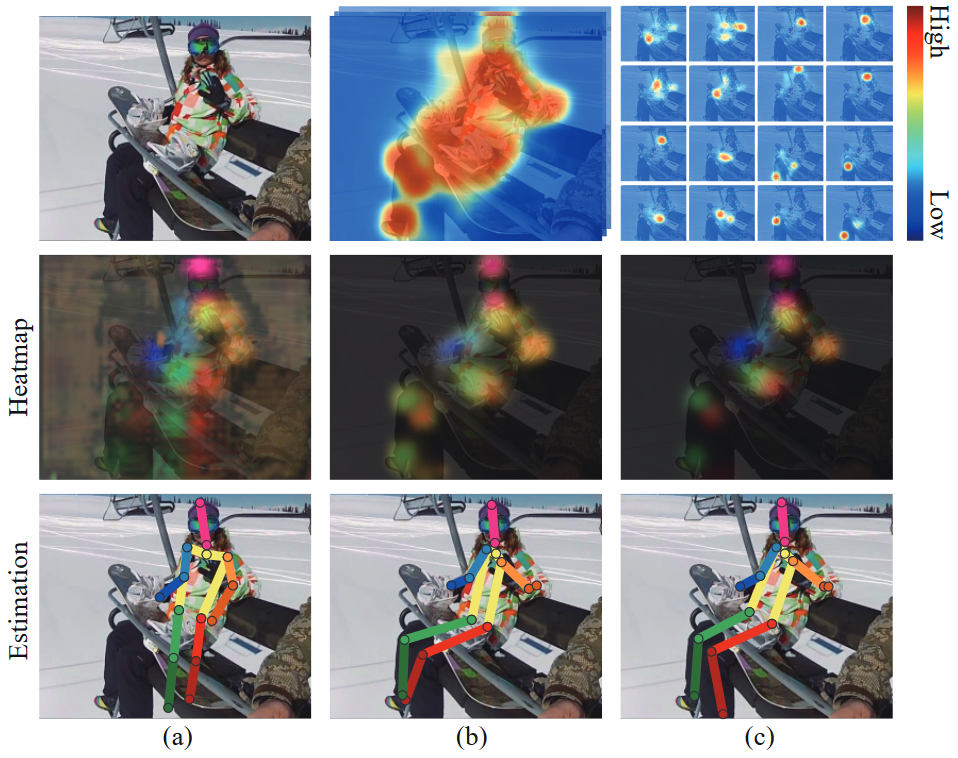
- 上图第一行分别是,输入图片、整体注意力图、部分注意力图;第二行是关节点位置的 heatmaps,不同颜色对应不同的关节点;第三行是预测的姿态可视化结果,(a) 由于背景复杂和自遮挡问题,ConvNets 可能得到错误的估计结果,(b) 视觉注意力图对人体关节点的空间关系进行建模,鲁棒性好,© 关节点注意力图解决重复计算问题 (double counting problem),进一步提高关节点估计结果
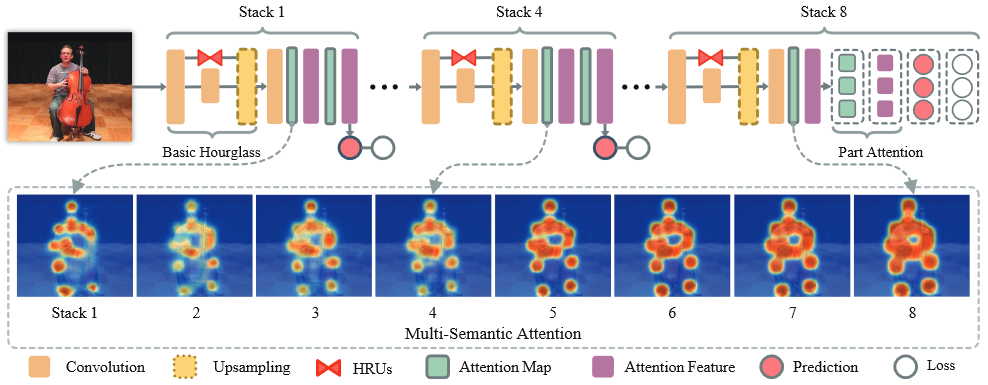
Pose Attention 的网络结构?
![]()
- 由 8-stack hourglass 网络的基本结构组成,各 hourglass stack 分别得到多分辨率注意力图,将多语义注意力图应用到各 hourglass
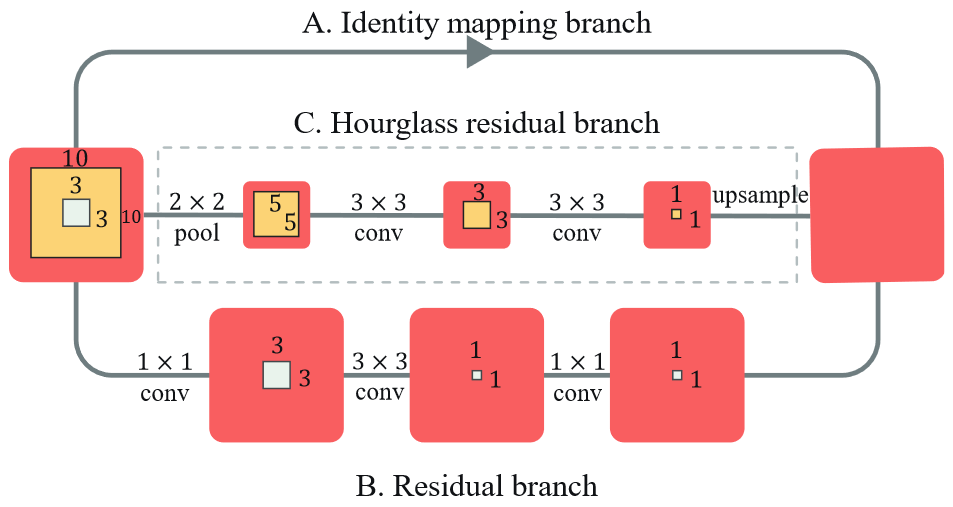
Pose Attention 的沙漏残差单元 (Hourglass Residual Units, HRUs)?
![]()
- 包括三个分支:(A) 恒等映射 (identity mapping) 分支; (B) 残差分支;© hourglass residual 分支。卷积残差分支和 hourglass residual 分支输入的接受野分别为 3 x 3、10 x 10
- 三个分支具有不同的接受野和分辨率,相加作为 HRU 的输出. HRU 单元增加了网络接受野,同时保持高分辨率信息
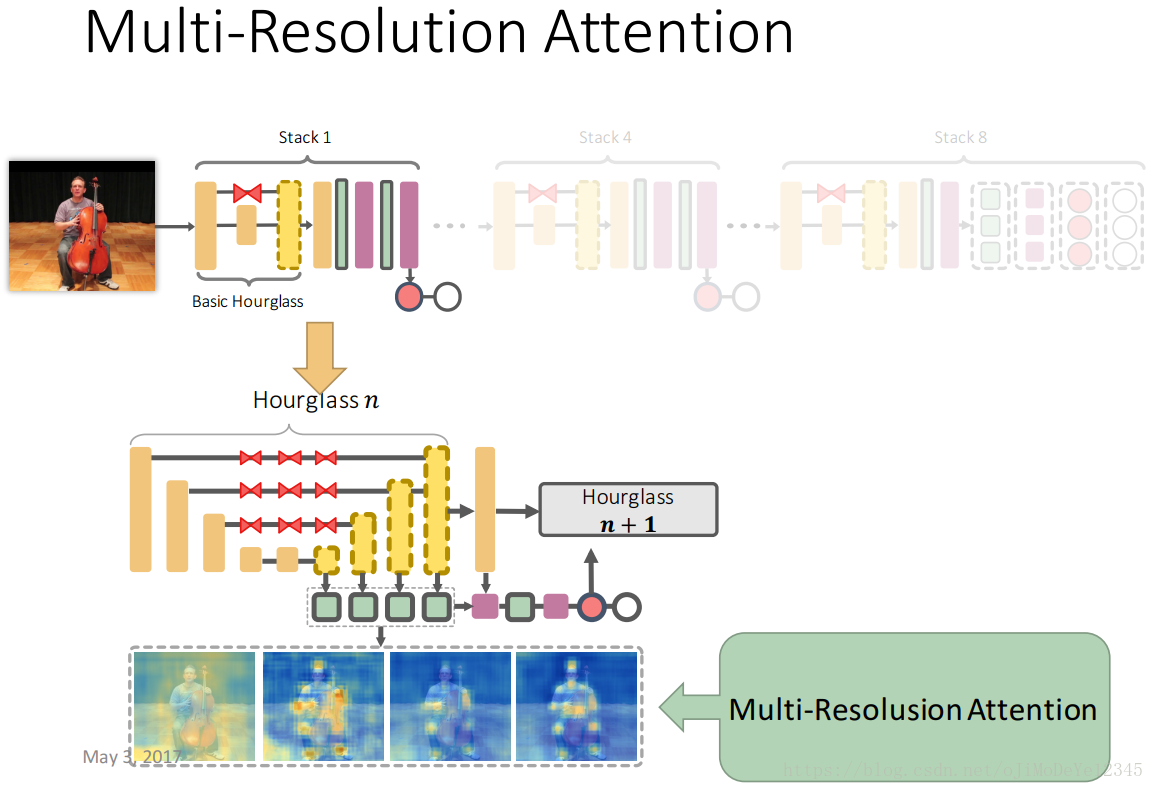
Pose Attention 的多分辨率注意力 (Multi-Resolution Attention)?
![]()
- 上图是各 hourglass stage 内部的不同尺度的特征得到多分辨率注意力图,分辨率越高其注意力越精细
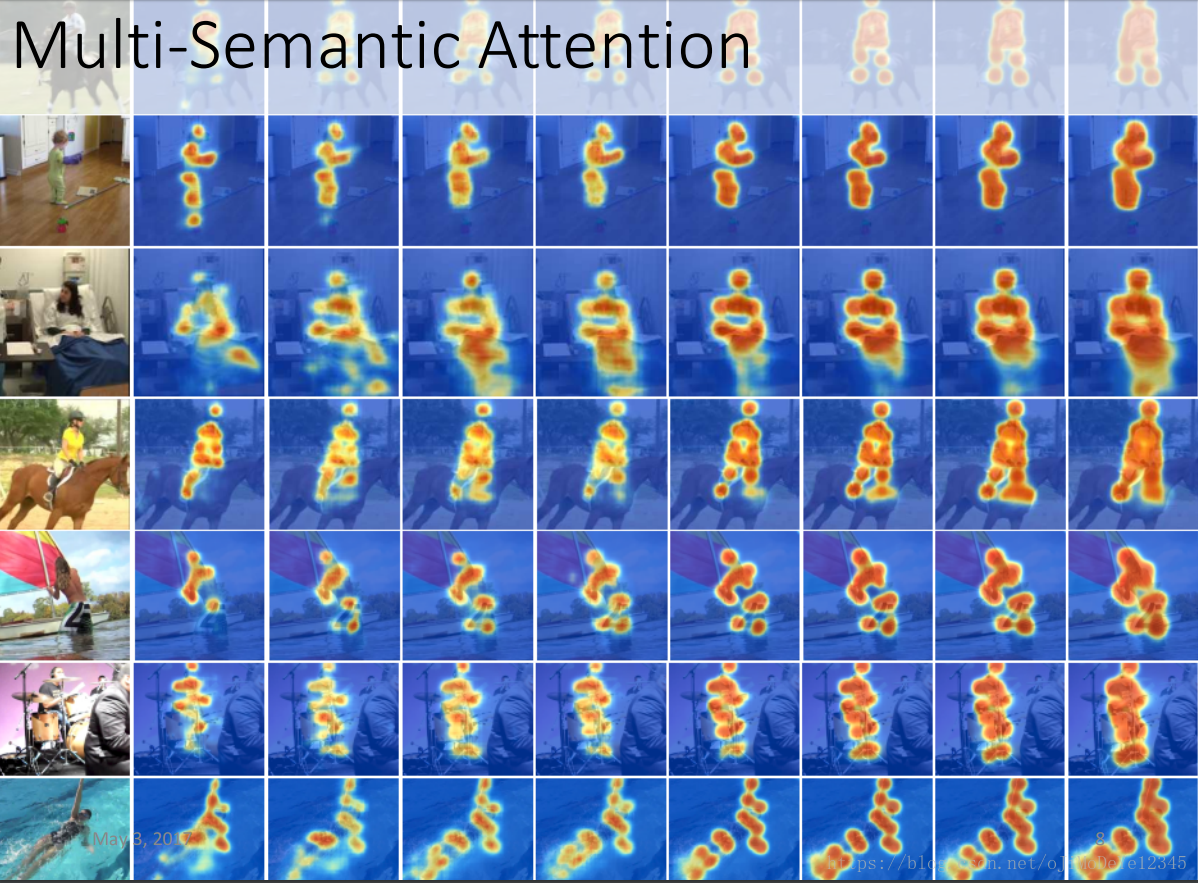
Pose Attention 的多语义注意力 (Multi-Semantics Attention)?
![]()
- 上图是 8 个 stage 的注意力图,可以看出不同的 stack 具有不同的语义,底层 stacks 对应局部特征,高层 stacks 对应全局特征。因此,不同 stacks 生成的注意力图编码着不同的语义
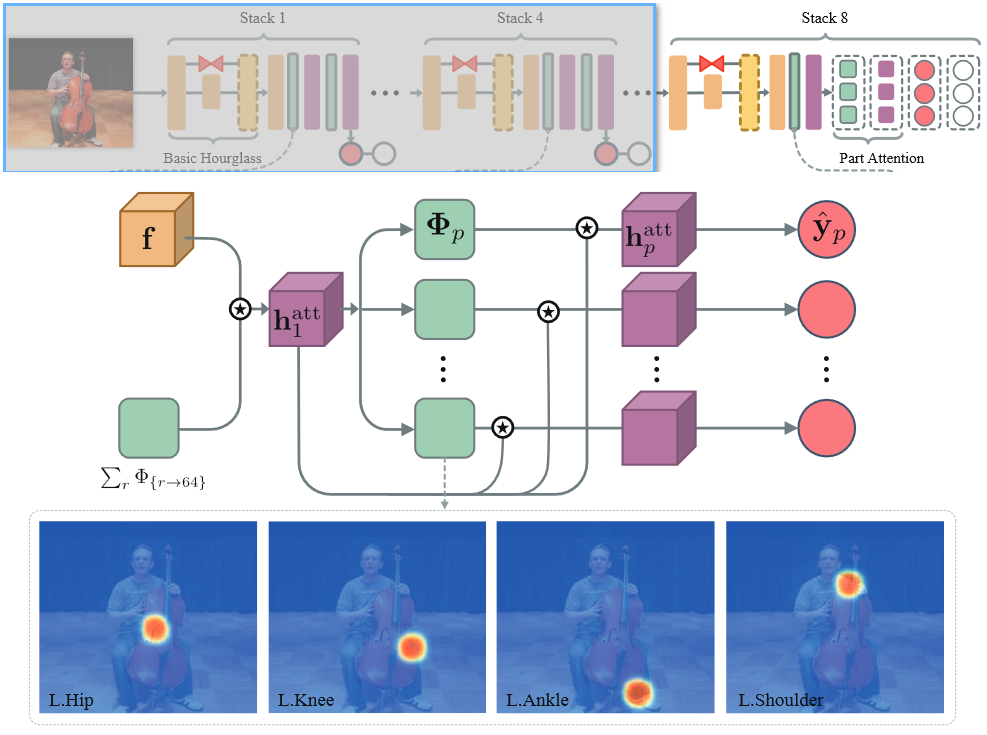
Pose Attention 的分层注意力机制 (Hierarchical Attention Mechanism)?
![]()
- 底层 stacks (stack1 - stack4),采用两个整体注意力图 和 来对整体人体进行编码
- 高层 stacks (stack5 - stack8),设计分层的 coarse-to-fine 注意力机制对局部关节点进行缩放处理
- f 是 Figure5 中 hourglass stack 的最后一层的输出特征,Φ 上采样的注意力图, 是 hourglass stack 输出特征和注意力模型得到的注意力图,是注意力图结合各关节点注意力模型得到的 refined 后注意力图特征
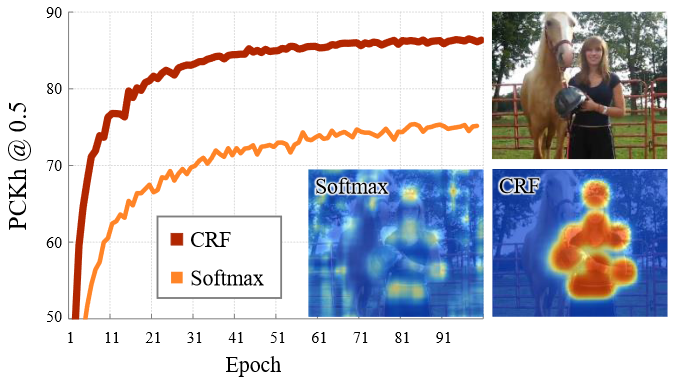
Pose Attention 恢复关键点预测使用 CRF 和 softmax 的区别?
![]()
- 随着训练的进展,Pose Attention 比较验证集上的准确率,即 PCKh 为 0.5。与 Softmax 注意力模型相比,CRF 注意力模型收敛更快,验证精度更高。将这两种模型生成的注意力图可视化,观察到 CRF 模型生成的注意图比 Softmax 模型更加清晰,因为 CRF 模型对人体各部位的空间相关性建模能力更强
参考: