大模型参数设置
在使用 transformer 类模型预测时,是逐位输出 token,输出完整的回答的过程,是 transformer 的解码策略。
目前已有的解码策略如下:假设词库大小是 N,预测 token 数量是 T,假设使用 BeamSearch,束宽为 K
| 解码策略 | 设置 | 描述 | 复杂度 | 优缺点 |
|---|---|---|---|---|
| 暴力遍历 | - | 每个单步时都做 N 次预测,直到遇到停止 token 或者达到最大预测长度 | N*N*T | 全局最优,但是复杂度极高 |
| 贪婪搜索 greedy_search | Num_beams=1, do_sample=False | 每个单步时选择最大概率的 token,并作为下次预测的输入,直到遇到停止 token 或者达到最大预测长度 | N*T | 局部最优,搜索空间唯一,每次生成结果一样 |
| 随机贪婪搜索 sample | Num_beams=1, do_sample=True | 每个单步时会根据模型输出的概率进行采用,而不是选条件概率最高的词,增加多样性 | N*T | 局部最优,结果多样化 |
| 贪婪柱搜索 beam_search | Num_beams>1, do_sample=False | 每个单步时会会选择 K 个 “概率链” 最大的输出 | N*T*K | 局部最优,比贪婪搜索空间更大 |
| 采样柱搜索 beam_sample | Num_beams>1, do_sample=True | 每个单步时会会选择 K 个 “概率链” 较大的输出,并且增加多样性 | N*T*K | 局部最优,比贪婪搜索空间更大,结果多样化 |
不同的解码方式参数,组成了 LLMs 的 “调用参数”,注意这些参数不是直接修改模型参数,而是通过影响模型预测 “后处理” 实现影响模型输出,以下例子可以说明这个观点
1 | import torch |
[‘Hugging Face Company is one of the largest and most recognizable brands in the industry. The company has’, ‘Hugging Face Company is one of the largest and most recognizable brands in the industry. The company is’]
深入代码内部,发现设置的参数确实是在函数输出后起作用的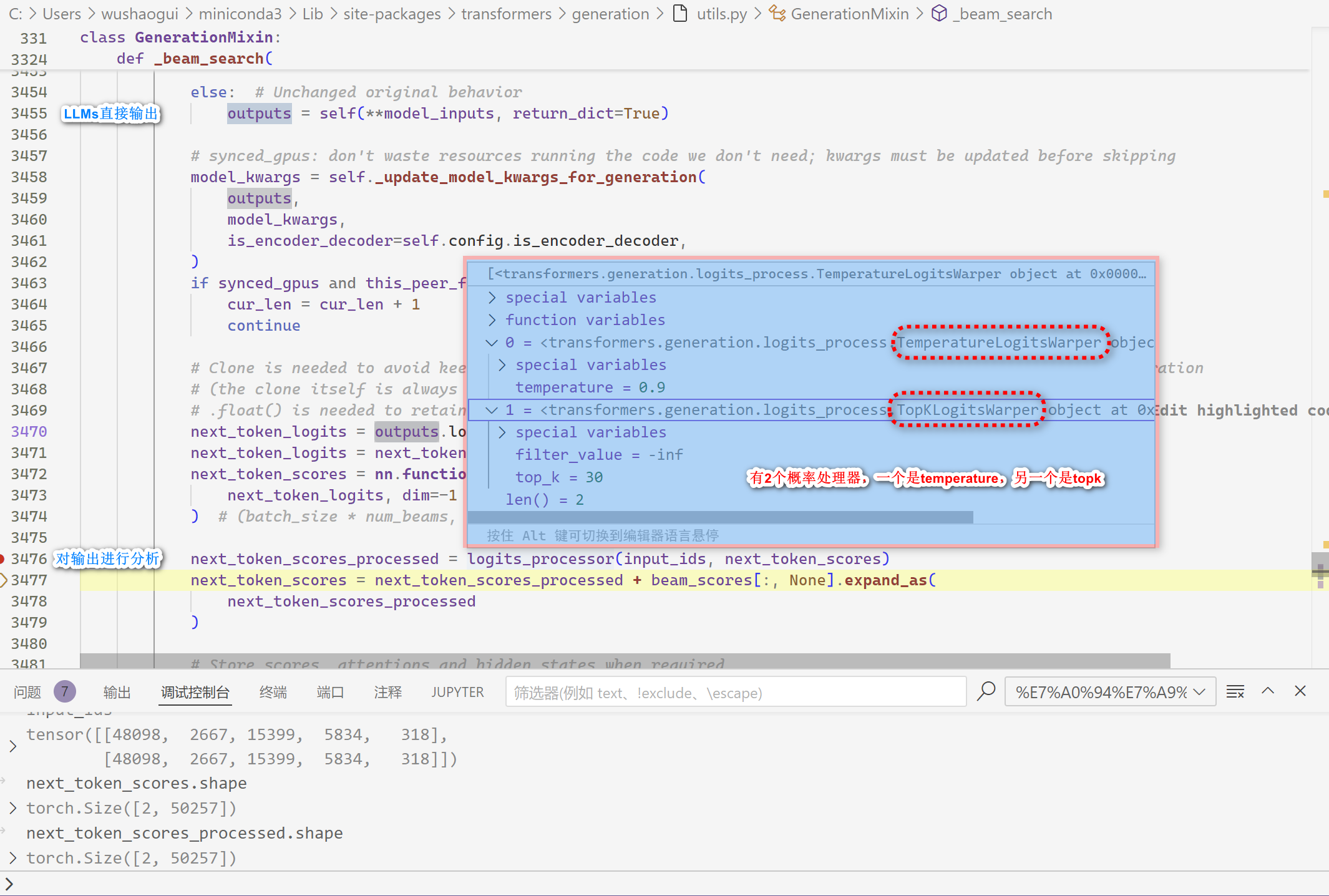
继续分析,类似 temperature、top_k 的内部实现如下: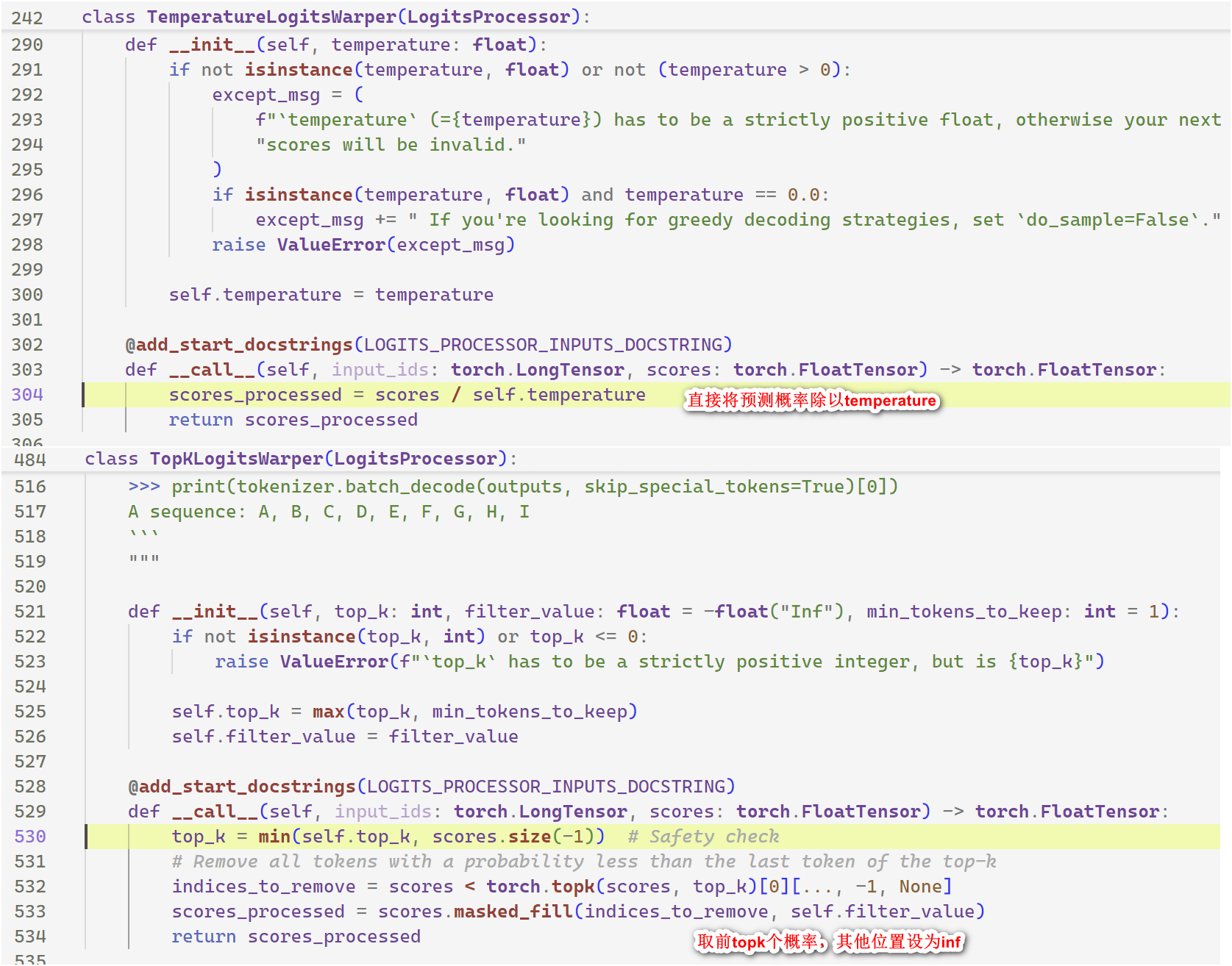
不同框架调用 LLMs 提供可修改的参数不一样,这是因为不同框架采样不同的后处理方式,但是一般来说,包含以下参数:
| 参数 | 推荐值 | 简介 | 定义 |
|---|---|---|---|
| temperature | 0.95 | 这个值越大生成内容越随机,多样性更好 | 这个参数控制着生成的随机性。较高的温度值会增加文本的多样性和创造性,但可能会牺牲一些准确性或连贯性。具体地,temperature 会调整概率输出的 softmax 概率分布,如果 temperature 的值为 1,则没有任何调整;如果其值比 1 大,则会生成更加随机的文本;如果其值比 1 小,则生成的文本更加保守。 |
| top_p | 0.95 | 单步累计采用阈值,越大越多 token 会被考虑 | 如果累计概率已经超过 0.95,剩下的 token 不会被考虑例如有下面的 token 及其概率,a: 0.9, b: 0.03, c: 0.03, d: 0.015,e… 。则只会采用用 abc,因为已经是 0.96 超过了 0.95 |
| top_k | 50 | 单步采用 token 的数量,越大采用 token 会越多 | 单步中最多考虑的 token 数量 |
| max_length | 512 | 最大采样长度 | 模型生成的文本最大长度,超过的话会做截断,512 是参考值,这个依赖于实际情况自己设置 |
| num_beams | 1 | beam 搜索数量,越大文本质量越高 | 想象一棵树,这个树在每一层的叶子节点数量都是 num_beams 个,正常模型推理时设置成 1 就行啦;num_beams=20 表示在每一步时,模型会保留 20 个最有可能的候选序列,保留方式是累计概率乘积。这有助于生成更加精确和高质量的文本。 |
| do_sample | False | 是否概率采样 token 得到结果 | 当设置为 False 时,模型在生成文本时不会随机采样,而是选择最可能的下一个词。这使得生成的文本更加确定和一致。 |
| num_beam_groups | 1 | 分成 num_beam_groups 组进行搜索 | 这个参数与束搜索相关。它将搜索的束分为不同的组,每个组内部进行搜索。这可以增加文本的多样性。Num_beam_groups 包含 num_beams |
| num_return_sequences | 1 | 有多少条返回的结果 | 推理的话设成 1 就好了 |
| output_scores | True | 调试实验时用到 | 设为 True 时模型在生成文本的每一步都会输出每个词的分数(或概率),这有助于了解模型是如何在不同选项中做出选择的。 |
| repetition_penalty | 1 | 重复惩罚值,越大越不会生成重复 token | 默认值为 1.0,其中较高的值意味着更强的惩罚,生成的文本中将出现更少的重复。如果取值为 0,则没有惩罚,生成的文本可能包含大量重复的内容。 |
| max_new_tokens | 256 | 模型生成的最大新词数 | 在这里设置为 256,意味着每次生成的文本最多包含 256 个新词。 |
| diversity_penalty | 1.5 | 当使用多束搜索时,这个参数惩罚那些在不同束中过于相似的词,以提高生成文本的多样性。 | 设置为 1.5 意味着对相似性施加较大的惩罚。如果在同一个 step 中某个 beam 生成的词和其他 beam 有相同的,那么就减去这个值作为惩罚,仅在 num_beam_groups 启用时这个值才有效 |
| length_penalty | 1 | beam search 分数会受到生成序列长度的惩罚 | length_penalty=0.0:无惩罚、length_penalty<0.0:鼓励模型生成长句子、length_penalty>0.0:鼓励模型生成短句子 |
| eos_token_id | - | 指定搜索时的结束 token | 有时可以提升模型性能,例如同时指定 |
| bad_words_ids | - | 禁止生成的 token | 帮助解决伦理安全、种族歧视等问题 |
| prefix_allowed_tokens_fn | - | 约束模型只能在给定的 tokens 里生成 token | 帮助特定功能的模型提升性能 |
以下通过设置不同参数,观察 LLMs 不同搜索策略的效果
1 | # 贪婪搜索 |
[‘Hugging Face Company is a company that has been around for over 20 years. We have been in’]
1 | # 随机贪婪搜索 |
[‘Hugging Face Company is a full-service independent contractor that specializes in building and operating public access public’, ‘Hugging Face Company is out of business. For many years their headquarters have been called The New Haven’]
1 | # 贪婪柱搜索 |
[‘Hugging Face Company is a company that specializes in the production of high-quality, high-quality’]
1 | # 采样柱搜索 |
[‘Hugging Face Company is a small, small business that has been in business for over 50 years.’, ‘Hugging Face Company is a small, small business that has been in business for over a decade.’]
1 | # 多组柱搜索搜索 |
[‘Hugging Face Company is a company that has been around for over 20 years. We have been in’, ‘Hugging Face Company is a small, independent, non-profit organization that provides free, confidential,’]