transformer:Attention Is All You Need
为了解决 RNN 在序列数据上感受野不足和无法并行训练的问题的问题,Transformer 被提出。Transformer 由且仅由 self-Attenion 和 Feed Forward Neural Network 组成,训练时一次输入所有时间步,构建所有时间步之间的注意力,不用考虑方向,不考虑长度
什么是 transformer ?
![]()
- RNN:相关算法只能从左向右依次计算或者从右向左依次计算,时间片 t 的计算依赖时间片 t-1,限制模型能力;并且对于长程依赖问题,LSTM 虽然能缓解,但是不能解决
- Transformer:抛弃了传统的 CNN 和 RNN,整个网络结构完全是由 Attention 机制组成。更准确地讲,Transformer 由且仅由 self-Attenion 和 Feed Forward Neural Network 组成,训练时一次输入所有时间步,构建所有时间步之间的注意力,不用考虑方向,不考虑长度
Transformer 的数据流过程?
![Drawing 2023-05-06 15.00.05.excalidraw]()
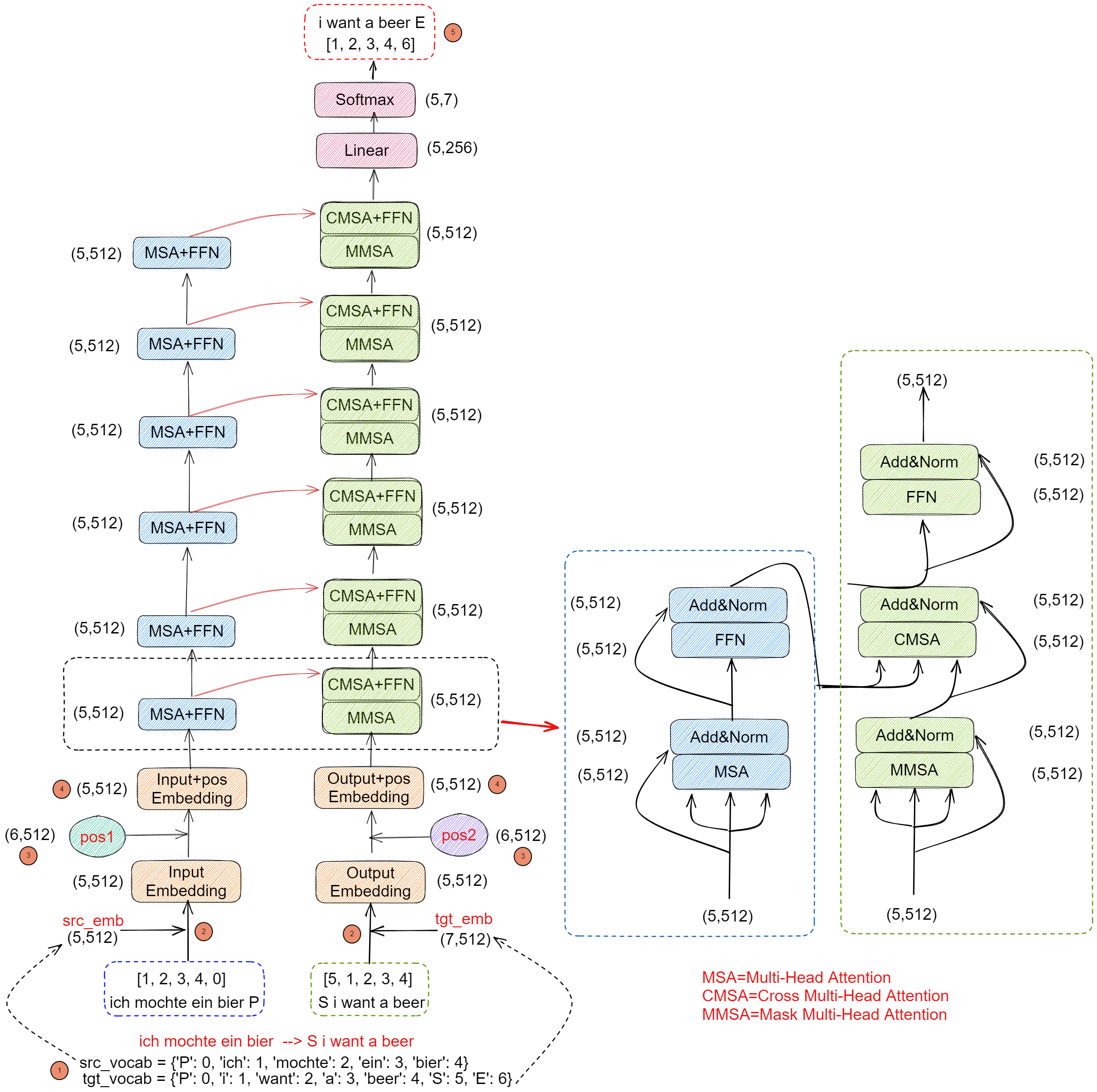
- 假设有一个翻译任务需要学习,将阿拉伯语 (ich mochte ein bier) 翻译成英语 (S i want a beer),其在 transformer 的数据流向如上图
- 制作源语言词库 src_vocab、目标语言词库 tgt_vocab:对要翻译的句子进行分词,假设只包含这两句话时,两个词库制作如图。其中 P 表示 padding,用于补充那些长度不够 5 的句子,S 表示开始,E 表示结束。实际使用时,src_vocab 和 tgt_vocab 的长度通常不一样
- 获得输入的 embedding:根据源语言词库 src_vocab、目标语言词库 tgt_vocab 的长度,分别生成 encoder 输入 embedding 查询表 src_emb (5,512)、decoder 输入 embedding 查询表 tgt_emb (7,512),根据 encoder 输入 (1,5) 构建输入 embedding (5,512),根据 decoder 输入 (1,5) 构建输入 embedding (5,512)
- 生成位置 embedding:根据 encoder 、decoder 的输入长度生成 N+1 的位置 embedding 查询表 pos 1、pos2,encoder+1 是为了表示 padding 的位置,decoder +1 是为了表示 start 的位置。位置 embedding 只要确定 N 的数量,其生成的 embedding 唯一,这里 encoder 、decoder 的输入都是 5,所以其位置 embedding 都是 (6,512)
- 生成最终输入 embedding:输入 embedding + 位置 embedding 即可,直接对应位置相加即可
- 生成标签:decoder 解码时理论上是输入前一时刻的输出,比如 t 时刻 decoder 输出是 i,那么 t+1 decoder 就是 i。但是实际上 transformer 使用 Teacher Forcing 训练,直接拿 GT 的下一时刻作为标签即可,所以 t 时刻 decoder 输入 i 时,期望其输出 want,当输入是
S i want a beer时,对应标签是i want a beer E
transformer 的网络结构?
![transformer-20230408151650]()
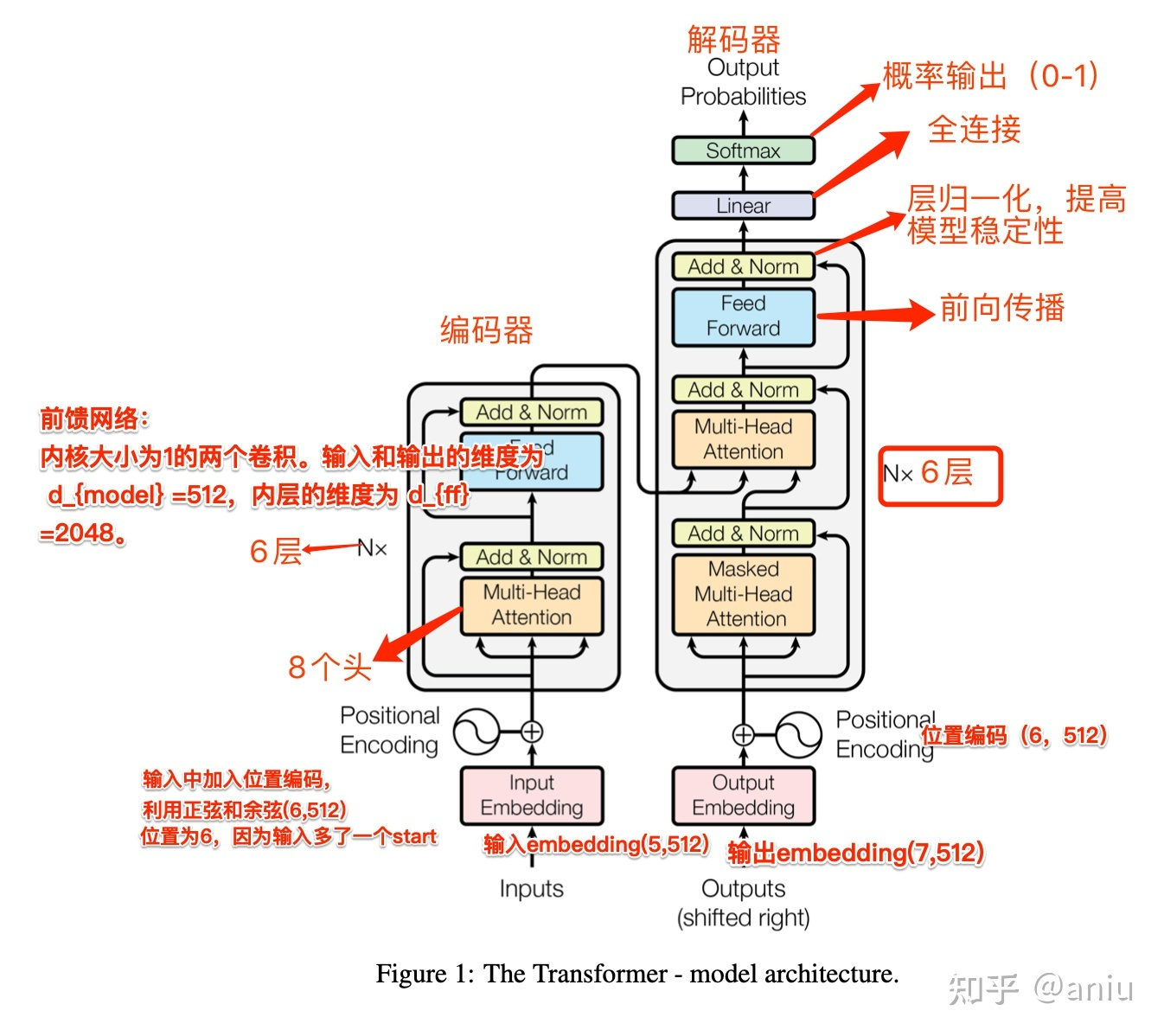
- Encoder:由 N (N=6) 个完全相同的 layer 堆叠而成,每层有两个子层。第一层是 MSA (multi-head self-attention) 机制,第二层是一个简单的、位置全连接的 FFN (Feed Forward Neural Network) 前馈神经网络。在两个子层的每一层后采用残差连接,接着进行 layer normalization,即每个子层的输出是
- Decoder:由 N (N=6) 个完全相同的 layer 堆叠而成,除了每个编码器层中的两个子层之外,解码器还插入第三个子层,该子层对编码器堆栈的输出执行 multi-head attention 操作,与 encoder 相似,在每个子层的后面使用了残差连接,之后采用了 layer normalization。修改了 decoder stack 中的 self-attention 子层,以防止当前位置信息中被添加进后续的位置信息。这种掩码与偏移一个位置的输出 embedding 相结合,确保对第 i 个位置的预测只能依赖小于 i 的已知输出
transformer 的 Positional Encoding(位置编码)?
![transformer-20230408151516]()
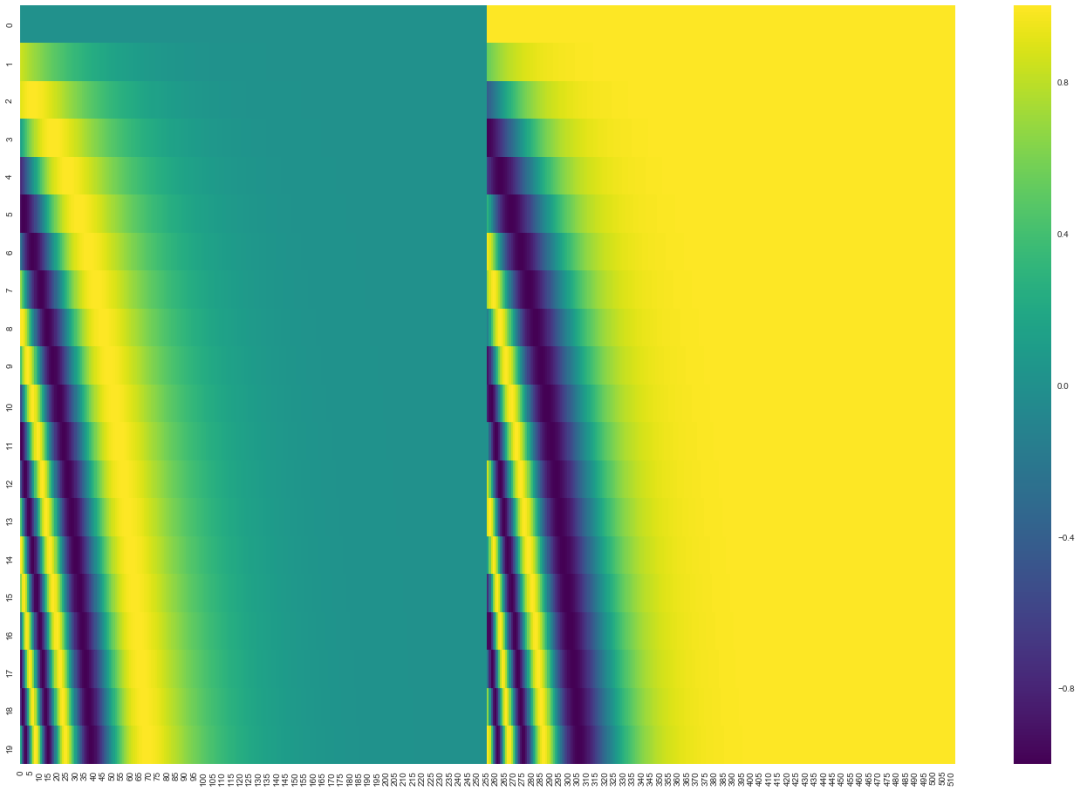
- 下图是 20 字 (行) 的位置编码实例,词嵌入大小为 512 (列)。你可以看到它从中间分裂成两半。这是因为左半部分的值由一个函数 (使用正弦) 生成,而右半部分由另一个函数 (使用余弦) 生成。然后将它们拼在一起而得到每一个位置编码向量
- 在没有 Position embedding 的 Transformer 模型并不能捕捉序列的顺序,交换单词位置后 attention map 的对应位置数值也会进行交换,并不会产生数值变化,即没有词序信息。所以这时候想要将词序信息加入到模型中
- 现在的 Transformer 架构还没有提取序列顺序的信息,这个信息对于序列而言非常重要,如果缺失了这个信息,可能我们的结果就是:所有词语都对了,但是无法组成有意义的语句,通过在 encoder 和 decoder 堆栈底部的输入嵌入中添加 “Positional Encoding (位置编码)”
- 位置编码 embedding 和输入 embedding 都是 (x,512),可以进行相加,其中输入 embedding 通过 embedding Layer 实现,而位置编码 embedding 通过三角函数获得以下公式实现。其中 pos 表示 token 的位置,设 token 的数量是 L,则 , 为向量的某一维度,
1
2
3
4
5
6
7
8
9#-> 根据源语言库表长度及隐向量大小构建每个单词的Embedding
self.src_emb = nn.Embedding(5, 512) # [1,5]-->(1,5,512)
#-> 创建位置Embedding
#首先创建每个位置关于隐向量长度的查询表,创建源语言库表长度+1的表格,1表示start符号的位置Embedding-->(6,512)
postion_embedding_init = get_sinusoid_encoding_table(5 + 1, 512)
# from_pretrained表示加载创建好的Embedding,freeze只加载不训练
self.pos_emb = nn.Embedding.from_pretrained(postion_embedding_init,freeze=True)
# 单词的Embedding+单词的位置的Embedding = Encoder输入
enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(torch.LongTensor([[1,2,3,4,0]])) # (1,5,512)+ (1,5,512)=(1,5,512)
additive attention、dot-product (multi-plicative) attention 的区别?
![Drawing 2023-03-31 21.00.04.excalidraw]()
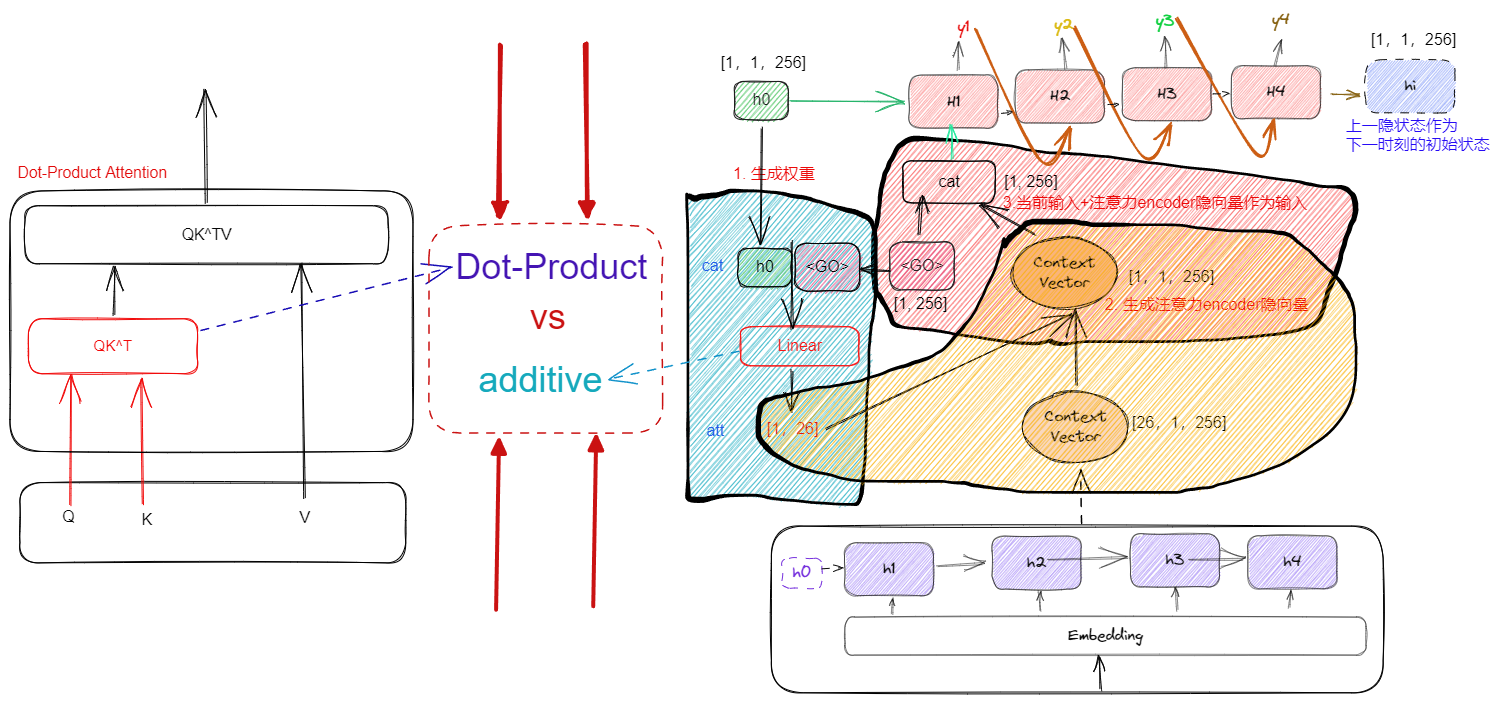
- additive attention:原始的 seq2seq 加注意力机制就是使用这个 additive attention,假设 C 是 encoder 编码得到的向量,解码时不是直接将这个向量输入到所有时刻,而是先经过注意力加权,加权的得到是 [x,Ca],然后连接 Linear 得到 decoder 的输入。由于 Linear 是线性转换,可以认为是加性加权
- Dot-Product Attention:设一个句子的长度为 S,单词 embedding 空间的维度为 D,那么一个句子就会被编码为一个大小为 S×D 的矩阵。使用三个大小为 D×d 的权重矩阵 Wq, Wk, Wv 与之相乘,会得到为三个大小为 S×d 的编码矩阵 Q, K, V, Q 代表着需要编码的词的信息, K 代表着句子中其它词的信息,相乘后得到句子中其它词的权重值; V 代表着每个位置单词蕴含的语义信息
- 加型注意力机制和点乘注意力机制有着相同的计算复杂度,但点乘注意力机制运算可以使用高度优化的并行矩阵乘法代码,会更快也更节省空间
transformer 注意力的构建?
![]()
- Attention 机制:transformer 使用 Scaled Dot-Product Attention 构建注意力,它通过 1 个 query 和 1 组 key-value 对映射到一个输出,其中 Q 代表着需要编码的词的信息, K 代表着句子中其它词的信息,相乘后得到句子中其它词的权重值; V 代表着每个位置单词蕴含的语义信息,在被加权求和后作为待编码词的编码
- Multi-Head Attention (MHA):设一个句子的长度为 S,单词 embedding 空间的维度为 D,那么一个句子就会被编码为一个大小为 S×D 的矩阵。使用三个大小为 D×d 的 Linear 权重与之相乘,会得到为三个大小为 S×d 的编码矩阵 Q, K, V,所谓多头注意力机制,就是将 n 个这样得到的编码进行拼接,得到大小为 S×[d,…, d] (其中 d 的个数为 n ) 的矩阵。多头注意力的引入既丰富了注意力,也降低了构建注意力的成本
- encoder-decoder Attention:transformer 的 1 个 block 包含 1 个 encoder 和 1 个 decoder,两部分除了各自构建 Multi-Head Attention 外,还在 encoder 与 decoder 之间构建注意力。构建时,以 encoder 输出作为 KV 和 Q (gt 序列) 一起输入到 decoder 构建,注意:KV 的序列长度和 Q 的序列长度不一定相等
- 对比
Seq2Seq过程:Q 包含待生成的句子相关信息,相当于解码器隐藏层状态 h;K,V 则来自编码器,与编码器输出的 C 类似
transformer 注意力的构建的数据流过程?
![Drawing 2023-05-06 22.35.49.excalidraw]()
- Step 1: 产生注意力矩阵,大小为 (5,5),表示输入的 5 个 token 之间的注意力。如果是 MMSA,这一步还会增加一个 Mask 的过程,用于屏蔽前一时刻后面时刻,比如 decoder 构建 i 的注意力时,不能让 i 感知到后一时刻的 want。所以 Mask 是一个上三角都是 1,下三角都是 0 的 5x5 矩阵,用于乘上 Q^K 之后的注意力矩阵
- Step 2:使用 softmax 归一化注意力矩阵
- Step 3: 得到加权后的特征
- Step 4: 残差连接得到最后输出
- 以上步骤是单头注意力的构建过程,如果是多头,先对隐向量表示进行分组,然后各组之间构建单头注意力,最后合并结果输出
transformer 的 (Position-wise feed-forward networks, FFN) 部分?
- 基于位置的前馈网络,是两个 1 D 卷积,主要对特征进行变换,过程是 (1,5,512)->(1,2048,5)->(1,512,5)->(1,5,512),最后使用 LayerNorm 和残差连接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
"""
attention 结构中的 FeedForward 组件, 由2个1x1的卷积形成
"""
super(PoswiseFeedForwardNet, self).__init__()
##内核大小为1的两个卷积。输入和输出的维度为 d_{model} =512,内层的维度为 d_{ff} =2048。
# conv1和conv2卷积模型初始化, 输入的channel变化, d_model-->d_ff -->d_model
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
# 层归一化,模型更加稳定
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, inputs):
"""
输出的形状应该是不变的,和输入的形状相同
:param inputs: torch.Size([1, 5, 512])
:return: 返回维度是[1, 5, 512],
"""
residual = inputs # [1, 5, 512]
# torch.Size([1, 512, 5])->torch.Size([1, 512, 5]) -> torch.Size([1, 2048, 5])
output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))
# [1, 2048, 5] -> .Size([1, 512, 5])->torch.Size([1, 5, 512])
output = self.conv2(output).transpose(1, 2)
# 残差部分和层归一化 [1, 5, 512]+torch.Size([1, 5, 512])->torch.Size([1, 5, 512])
new_output = self.layer_norm(output + residual)
return new_output
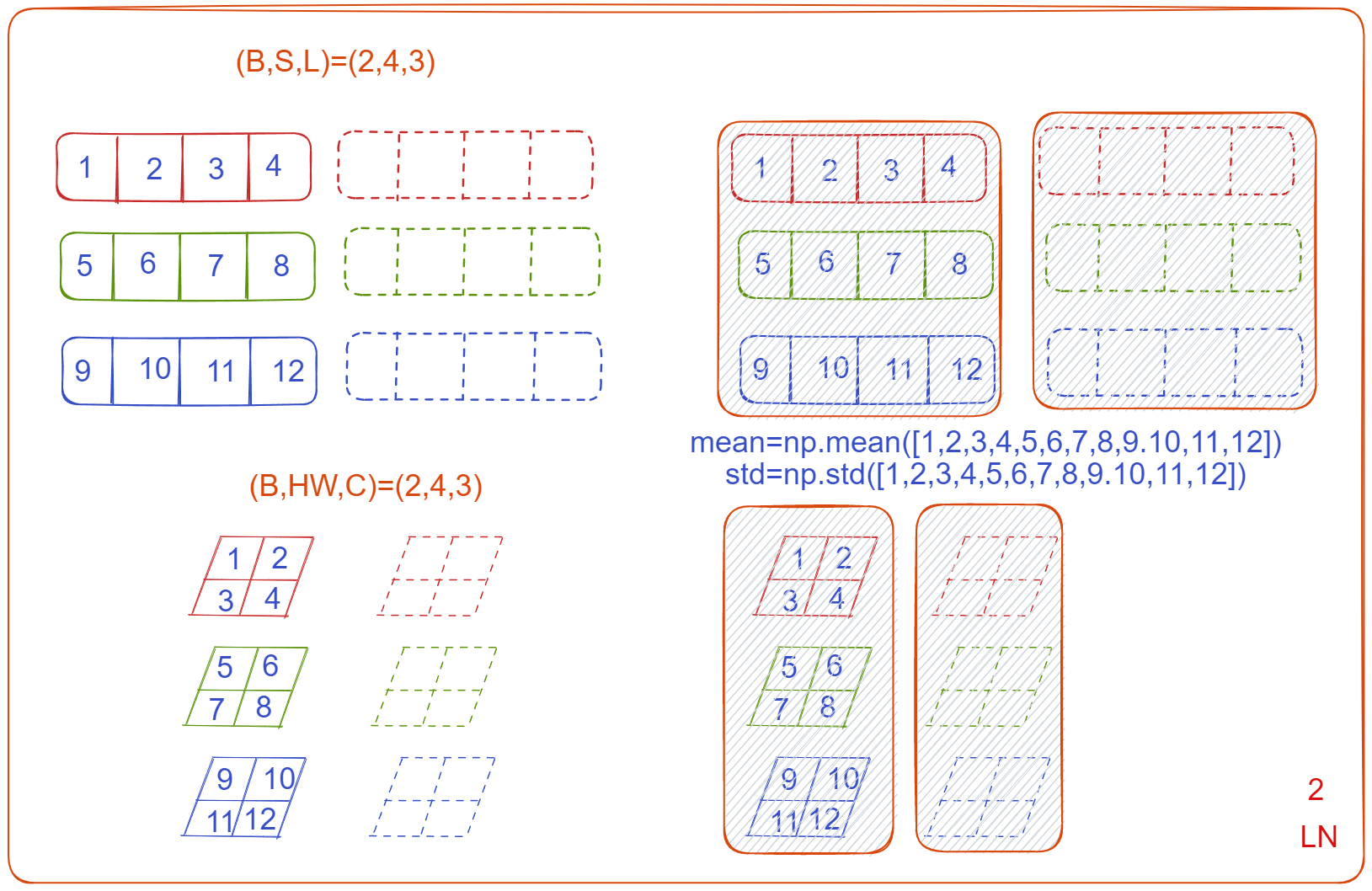
transformer 的 Layer normalization?
![Drawing 2023-05-05 16.14.36.excalidraw]()
- 这里区别于 BN,BN 沿着每个 C (通道数量) 进行做归一化,针对不同样本的同一特征做操作,而 Layer normalization 是沿 ** 每个 N (时间步) 进行归一化
1
2
3
4
5
6
7
8
9
10
11
12class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
# 统计每个样本所有维度的值,求均值和方差
# 相当于变成[bsz*max_len, hidden_dim], 然后再转回来
mean = x.mean(-1, keepdim=True) # mean: [bsz, max_len, 1]
std = x.std(-1, keepdim=True) # std: [bsz, max_len, 1]
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
transformer 的 Mask 过程?
- Mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask
- padding mask:在所有的 scaled dot-product attention 里面用到,因为每个批次输入序列长度是不一样的也就是说,为了对齐在较短的序列后面填充 0,后续没必要在这些位置构建注意力,所以需要屏蔽。具体的做法是,在这些位置的值加上一个非常大的负数 (负无穷),经过 softmax,这些位置的概率就会接近 0
- sequence mask:只有在 decoder 的 self-attention 里面用到,其目的就是为了在预测未来数据时把这些未来的数据屏蔽掉,防止数据泄露。如果我们非要去串行执行 training,seq mask 其实就不需要了。具体做法是产生一个上三角矩阵,上三角的值全为 1,下三角的值全是 0,对角线也是 0,当 计算完成后,使用该矩阵的某一行去盖住 label,使得 softmax 的值趋向 0 如预测第一个词时,decoder 输入是 <S>,后续需要盖住,直接乘上矩阵第一行即可
transformer 如何训练?
- transformer 训练一次输入 2 个张量,encoder 输入和 decoder 输入,其中 encoder 输入是待执行自注意力的序列,输出 k、v,decoder 输入 gt 序列,中途产生 q,用于与 k、v 构建交叉注意力,最终输出下一个序列,这也是模型输出
- decoder 输入输出:以翻译 “我爱中国” 为例,encoder 输入是 “我爱中国” 的 embedding,decoder 输入是 "<s> I love “,标签是"I love china”,注意:这是一次性输入 "<s> I love"3 个序列,也是一次性输出 "I love china"3 个序列
- decoder 的 Mask:decoder 输入不能让前面的序列看到后面的序列,比如构建 I 的注意力时,不能让他看见 love (因为这是让他预测的,不能直接给答案),所以构建注意力时,需要使用 Mask 矩阵过滤 QK^T 后的矩阵,decoder 根据 mask 将对应位置的值设置为无穷小,这样在计算 softmax 时,会使其失去作用(趋近于 0),进而在与 v 相乘时,也就忽略了 v 中对应的 “love” 和 “you” 的部分
- transformer 并行训练:训练不像 RNN 训练时,必须拿到前一序列的预测结果,再预测下一个序列,因此可以被并行训训练
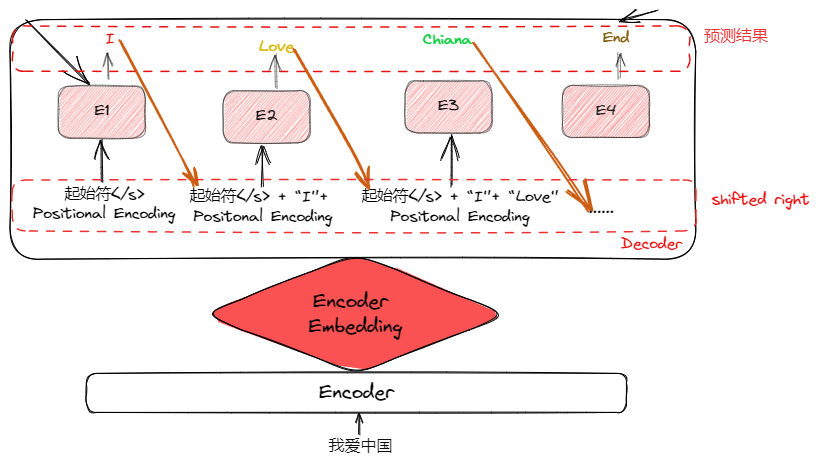
transformer 如何预测?
![Drawing 2023-03-31 23.21.57.excalidraw]()
- transformer 推理一次输入 2 个张量,encoder 输入和 decoder 输入,其中 encoder 输入是待执行自注意力的序列,输出 k、v,decoder 输入 gt 序列,中途产生 q,用于与 k、v 构建交叉注意力,最终输出下一个序列,这也是模型输出
- Decoder 输入输出:以翻译 “我爱中国” 为例,encoder 输入是 “我爱中国” 的 embedding,
- decoder 首先输入是 "<s>",得到输出 O1 (可能等于 love) 后,将 "O1" 再次输入 decoder,输出 O2 (可能等于 china),一直以此循环,知道模型输出结束符
- Shifted Right:当前时刻输出作为下一时刻 decoder 的输入的过程
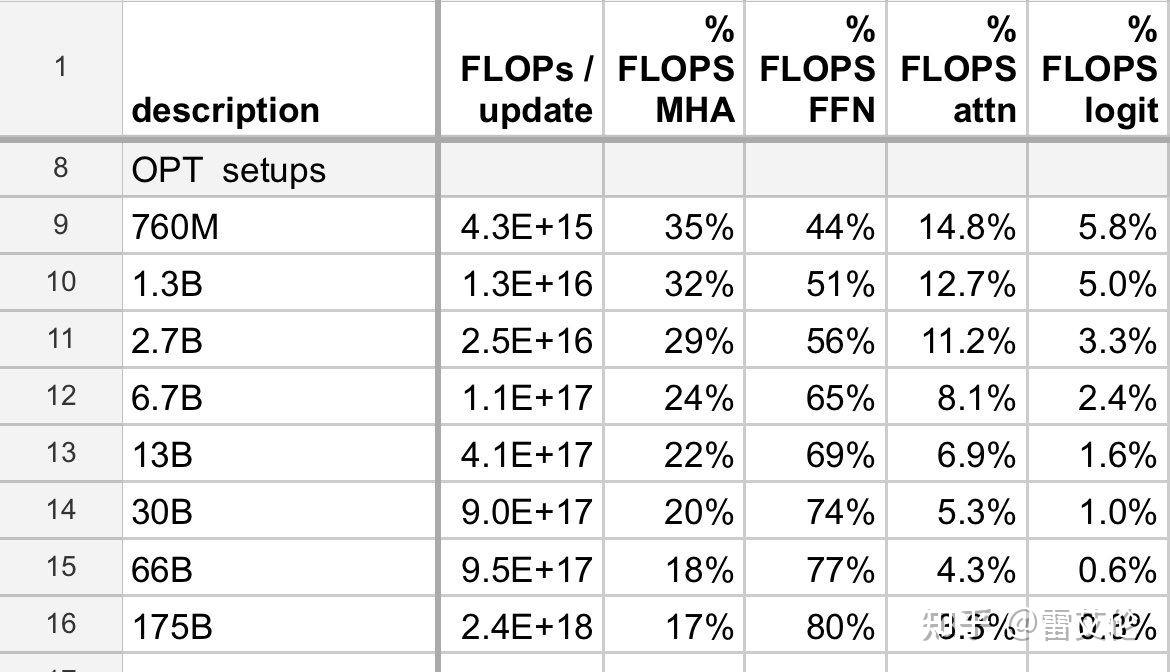
Transformer 各部分耗时比较?
![]()
- 当模型大了后,真正消耗算力(FLOPS)的,还是 MLP(FFN),自注意力(attn)和多头(MHA)只占小部分
Transformer 的并行性体现在哪里?
- RNN 之所以不支持并行化是因为它天生是个时序结构,t 时刻依赖 t-1 时刻的输出,而 t-1 时刻又依赖 t-2 时刻,如此循环往前
- Encoder 训练、推理并行:在构建 multi-head 隐向量注意力时,有对隐向量进行分组,在分组内构建全局注意力,分组之间不影响,所以分组之间的注意力可以并行构建
- Decoder 训练并行、推理不并行:训练阶段的 Decoder,如果使用 teacher force 训练方式,不用获取上一时刻输出即可训练,此时可以进行并行化,但是在测试阶段,因为我们没有正确的目标语句,t 时刻的输入必然依赖 t-1 时刻的输出,这时跟之前的 seq2seq 就没什么区别了。
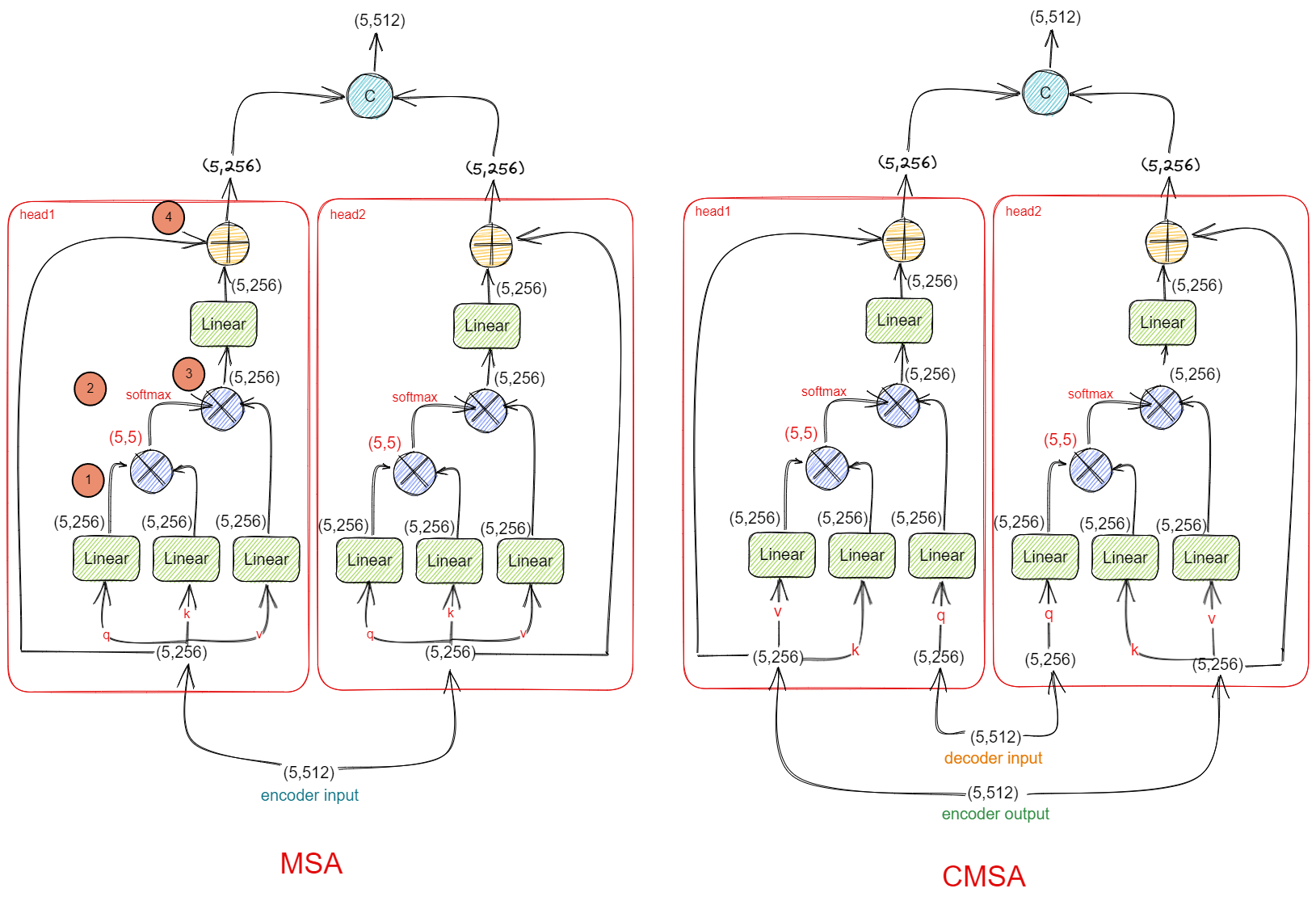
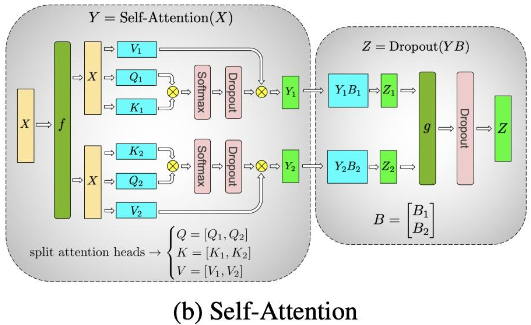
Transformer 的 MHA 如何实现并行计算的?
![]()
- 在构建 multi-head 隐向量注意力时,有对隐向量进行分组,在分组内构建全局注意力,分组之间不影响,所以分组之间的注意力可以并行构建
MHA 的时间复杂度计算?
- MHA 的计算过程是 Q (b, n, l) 与 K (b, m, l) 做矩阵点乘,得到注意力矩阵 (b, n, m),对于矩阵的每个位置,需要做 l 次乘法,所以时间复杂度是
Transformer 的注意力矩阵含义?
- 以 Pytorch 为例,输入到 transformer 的序列有两个,分别是 src、tgt,其中 src 可以是 (S, E) 或 (N, S, E),tgt 是 (T, E) 或 (N, T, E),,其中 S 是源序列长度、T 是目标序列长度、N 是 batch size、E 是特征长度
- 假设是 src (S, E) 与 tgt (T, E) 构建矩阵时,则其注意力矩阵大小是 (T, S); 假设是 src (N, S, E) 与 tgt (N, T, E) 构建矩阵时,构建注意力时,取出某个 batch 计算,N 个 batch 得到注意力矩阵是 (N, T, E)
- 总结:1) 注意力矩阵是目标序列与源序列之间的关系,目标序列与源序列长度可以不相等;2) 多个 batch size 构建注意力时,只在某个 batch 内构建注意力,不涉及跨 batch;3) 从目标序列来看,输入 (N, T, E),输出也是 (N, T, E),相当于拿 Q 去查询得到定长的输出
Transformer 为什么 Q K 使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
- 这里的 Q、K 使用不同权重矩阵生成的意思是,当 encoder 输入 QKV 时,Q=K=V,在计算 QK 前,需要先经过权重矩阵计算,所以问题是为什么不直接进行 QK 计算注意力矩阵
- 说法 1:使用 Q、K 不相同可以保证在不同空间进行投影,增强了表达能力,提高了泛化能力。如果 QK 相等,那么 QK 计算得到的矩阵是对称矩阵,这样 self-attention 就退化成一个 point-wise 线性映射,对于注意力上的表现力不够强
- 说法 2:BETR 证明即使 Q=K,也不影响结果
Transformer 在 QK 之后,为什么要进行归一化?
- 在输入数量较大时,softmax 将几乎全部的概率分布都分配给了最大值对应的标签。也就是说极大的点积值将整个 softmax 推向梯度平缓区,使得收敛困难,梯度消失为 0,造成参数更新困难
Transformer 在 QK 之后,softmax 对哪一维度进行计算?含义是什么?
- 对最后一维计算 softmax 值,对某个 Q 上的序列来说,表示所有 K 上序列对其的注意力,累加在一起等于 1
Transformer 进行 MHA 时,每个 head 的 token 的隐变量长度变为 L/n_head?
- Transformer 的多头注意力看上去是借鉴了 CNN 中同一卷积层内使用多个卷积核的思想,原文中使用了 8 个 head,在同一 “multi-head attention” 层中,输入均为 “KQV”,同时进行注意力的计算,彼此之前参数不共享,最终将结果拼接起来,这样可以允许模型在不同的表示子空间里学习到相关的信息
- 总结:希望每个注意力头,只关注最终输出序列中一个子空间,互相独立。其核心思想在于,抽取到更加丰富的特征信息
为什么在进行 softmax 之前需要对 attention 进行 scaled?
- 在输入数量较大时,softmax 将几乎全部的概率分布都分配给了最大值对应的标签。也就是说极大的点积值将整个 softmax 推向梯度平缓区,使得收敛困难,梯度消失为 0,造成参数更新困难
Transformer 在哪里做了权重共享,为什么可以做权重共享?好处是什么?
- Encoder 和 Decoder 间的 Embedding 层权重共享:源语言和目标语言是不一样的,但它们可以共用一张大词表,对于两种语言中共同出现的词(比如:数字,标点等等)可以得到更好的表示,而且对于 Encoder 和 Decoder,嵌入时都只有对应语言的 embedding 会被激活,因此是可以共用一张词表做权重共享的
- Decoder 中 Embedding 层和 FC 层权重共享:Embedding 层参数维度是:(v, d),FC 层参数维度是:(d, v),其中 v 是词表大小,d 是 embedding 维度,转置后直接共用
如何将 trasformer 应用到计算机视觉?
- 身心兼备:所谓 “身心兼备”,就是使用 trasformer 的结果,将计算机视觉问题转为序列学习问题。对于一张图片,每 4x4 相邻的像素为一个 Patch,然后在 channel 方向展平(flatten)。假设输入的是 RGB 三通道图片,那么每个 patch 就有 4x4=16 个像素,然后每个像素有 R、G、B 三个值所以展平后是 16x3=48,所以通过 Patch Partition 后图像 shape 由 [H, W, 3] 变成了 [H/4, W/4, 48],如 vit、SETR、DETR 等
- 只取灵魂:所谓 “只取灵魂”,就是只使用自注意力机制,不使用 trasformer 结构,如 OCRNet
Transformer 、RNN、CNN 网络的区别?
![]()
- 复杂度:self-attention layer 用常数次 O (1) 的操作连接所有位置,而 recurrent layer 需要 O (n) 顺序操作。在计算复杂度方面,当序列长度 N 小于表示维度 D 时,self-attention layers 比 recurrent layers 更快。为了提高包含很长序列的任务的计算性能,可以仅在以输出位置为中心,半径为 r 的的领域内使用 self-attention
- 并行化:Transformer 可以并行训练,RNN 必须挨个时间步训练
参考:
- Transformer (一)–论文翻译:Attention Is All You Need 中文版_transformer 论文翻译_吕秀才的博客 - CSDN 博客
- additive attention 与 dot-product attention - 知乎
- Transformer 的模型和代码解析 - 知乎
- 为什么 Transformer 要用 LayerNorm? - 知乎
- 机器学习 - 31-Transformer 详解以及我的三个疑惑和解答_transformer 不收敛_迷雾总会解的博客 - CSDN 博客
- 1 分钟 | 聊聊 Transformer 的并行化 - 知乎
- https://blog.csdn.net/qq_42599237/article/details/123383691
- https://zhuanlan.zhihu.com/p/97451231
- transformer 为什么有利于并行计算? - 知乎
- transformer 中为什么使用不同的 K 和 Q, 为什么不能使用同一个值? - 知乎
- 在测试或者预测时,Transformer 里 decoder 为什么还需要 seq mask? - 知乎
- transformer 中 multi-head attention 中每个 head 为什么要进行降维? - 知乎
- 如何理解 Transformer 论文中的 positional encoding,和三角函数有什么关系? - 知乎
- Bert/Transformer 被忽视的细节(或许可以用来做面试题) - 知乎