DiffusionAutoencoders:Toward a Meaningful and Decodable Representation
训练一个 Semantic 高级语义编码器,在训练 DDIM 时作为条件输入,通过控制高级语义信息的不同位置,控制图片生成效果
(图片)+ 高级语义 -> 噪声 + 高级语义 -> 条件图片,条件图片
什么是 DiffusionAutoencoders ?
![]()
- 扩散模型是否也能像 GAN 一样拥有一个富有语义信息的 latent space,使得我们能够轻松进行平滑插值,并在此基础上保持强大的重建能力呢?,本文将通过设计一种特殊的 conditional DDIM 实现表征的可解码性
- 原始 DDPM 基于一个高斯随机噪声重建图像,这里的随机噪声可以看作是图像的低级特征,如此无法通过修改低级特征控制图像部分区域的变化,所以在 DDIM 中引入高级语义特征参与训练,最终通过控制高级语义特征,实现对图像的控制
- 上述是 DiffusionAutoencoders 在真实图片上的属性修改和插值情况,可见图像朝做既定控制,平滑地过渡到目标图片

DiffusionAutoencoders 的网络结构?
![]()
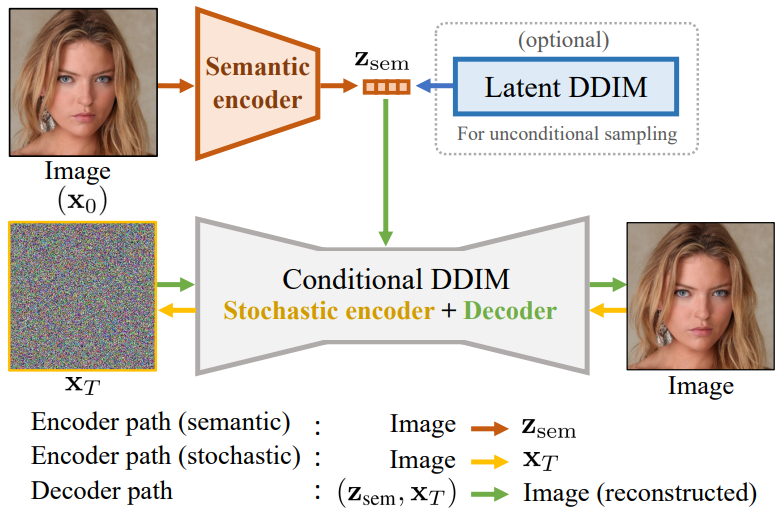
- Diffusion Autoencoders 是一个特殊的 Conditional DDIM 模型,由 semantic encoder、stochastic encoder 和 decoder 组成
- semantic encoder:负责提取图片的高级语义信息
- Stochastic encoder:通过输入图片 + 图片高级语义信息,逐步加躁,类似 DDPM 的扩散过程
- Decoder:通过输入噪声 + 图片高级语义信息,逐步去躁,类似 DDPM 的去躁过程
- Diffusion Autoencoders 首先训练 semantic encoder 和 decoder,直到收敛。然后,固定 semantic encoder 的,训练 latent DDIM
DiffusionAutoencoders 的 semantic encoder?
- 将输入图像编码为高级语义特征,其中包含丰富的语义信息可以帮助 去噪和预测输出图像,这个 semantic encoder 与 UNet decoder 的前半部分共享相同的架构。后续实验证明使用蕴含信息丰富的 为条件输入的 DDIM 可以更有效的去噪
DiffusionAutoencoders 的 stochastic encoder?
- conditional DDIM 过程还可用于反向生成噪声图像,即通过 rDDIM 将输入图像 编码为随机图像 ,然后以 为初始值,DDIM 可以重建 ,加躁过程和 DDPM 类
- 通过使用 semantic encoder 和 stochastic encoder ,Diffusion Autoencoders 可以捕获输入图像的高级语义信息和详尽细节信息,同时还为下游任务提供高级表征
DiffusionAutoencoders 的 Decoder?
- 为了能够从 Diffusion Autoencoders 中采样生成新图像,需要一种额外的机制来采样 ,论文设计一个 latent DDIM 来拟合
- 优化的目标函数如下,其中 ,
DiffusionAutoencoders 的高级语义特征和低级随机变化?
![]()
- 实验证明了 Diffusion Autoencoders 的高级语义主要在 中捕获,细节特征在 中捕获。首先从输入图像 计算 semantic subcode,然后多次采样 stochastic subcode ,再解码 得到
- 看图可知,在固定 的情况下(每一行),stochastic subcode 仅影响较小的细节(例如头发和皮肤、眼睛或嘴巴),但不会改变全局外观,而改变 (每一列),则会得到完全不同的人

DiffusionAutoencoders 的高级语义特征插值特点?
![]()
- 理想的 latent space 可以通过简单线性变化来表示图像中的语义变化。例如,沿着连接两个 latent code 的直线移动,则应该在相应的两个图像之间出现平滑变化
- 首先将两个输入图像编码为 ,然后解码 ,其中 , 实现线性插值, 使用球面线性插值
- 如图所示,对 StyleGAN、DDIM 和 Diffusion Autoencoders 的 latent code 进行线性插值实验,发现 DDIM 不能平滑插值, StyleGAN 的插值结果很平滑,但两个端点与输入图像不相似。Diffusion Autoencoders 则可以平滑插值,而且两个端点几乎完全匹配真实的输入图像

DiffusionAutoencoders 的属性操控能力?
![]()
- Diffusion Autoencoders 通过属性分类器的权重向量来确定属性方向向量,然后使用简单的线性操作来验证 latent code 的性能
- 与基于 GAN 的属性操作相比,Diffusion Autoencoders 生成图像更真实,同时能够保留与属性操作无关的细节。与传统 Diffusion 方法通过复杂的编辑技术实现属性修改相比,Diffusion Autoencoders 只需要简单的修改 latent code 即可

DiffusionAutoencoders 的快速去躁过程?
![]()
- Diffusion Autoencoders 能够以比 DDIM 更少的步骤更准确地预测

DiffusionAutoencoders 的类别引导采样?
- 先训练一个目标类 c 分类器 ,然后使用 rejection sampling 进行类条件采样,即从 latent DDIM 中采样 并以概率 接受该样本
参考: