AlexNet:ImageNet classification with deep convolutional neural networks
卷积神经网络从这里开始开始火起来,主要内容包括:(1) 使用 relu 训练网络;(2) 使用 LRN 层;(3) 使用数据增强;(4) 使用 dropout;(5) 使用重叠池化
什么是 AlexNet?
![AlexNet-20230408135804]()
- AlexNet 是由 Alex Krizhevsky 提出的首个应用于图像分类的深层卷积神经网络
- AlexNet 和 LeNet 很像,基础模块均是:卷积 + 激活 + 下采样,但是 AlexNet 更深
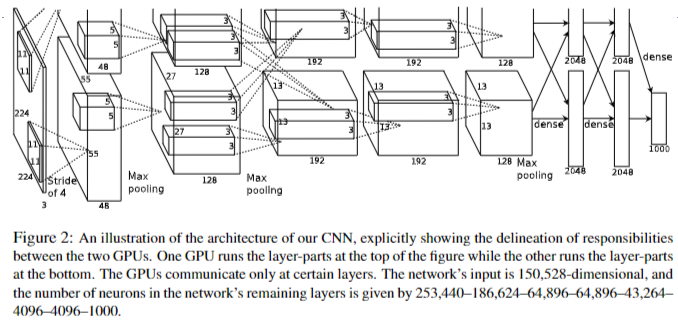
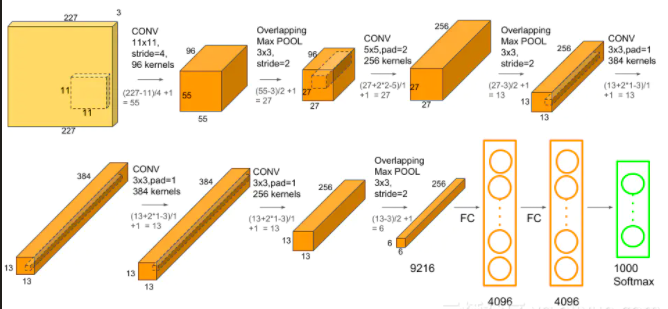
AlexNet 的网络结构?
![]()
- 训练阶段: 每张训练图片 256x256,然后我们随机裁剪出 224x224 大小的图片,作为 CNN 的输入进行训练
- 测试阶段: 输入 256x256 大小的图片,我们从图片的 5 个指定的方位 (上下左右 + 中间) 进行裁剪出 5 张 224x224 大小的图片,然后水平镜像一下再裁剪 5 张,这样总共有 10 张;然后我们把这 10 张裁剪图片分别送入已经训练好的 CNN 中,分别预测结果,最后用这 10 个结果的平均作为最后的输出
- 8 个学习层,包括 5 个卷积层和 3 个全连接层,其余层为 局部响应归一化 (Local Response Normalization,LRN) 层,池化层,softmax 输出层
AlexNet 的损失函数?
- AlexNet 输入是图片 (c,h,w),输出是 1000,表示该图片的分类结果
- AlexNet 使用交叉熵损失 (CrossEntropyLoss) 计算损失
Alexnet 中为什么选择使用 relu 作为激活函数,而不是 tanh?
- tanh 是饱和激活函数,而 Relu 是非饱和的,饱和激活函数更难训练网络,非饱和函数可以让梯度传播到更深层的网络中
- 在同等训练效果下,使用 relu 比 tanh 训练更快
![AlexNet-20230408135806]()
Alexnet 如何使用多 GPU 进行训练?
![AlexNet-20230408135804]()
- 将每层一半的内核(或神经元)分别放在 2 个 GPU 上
- 第三层从第二层的 2 个 GPU 获取输入,而第四层从第三层的各自 GPU 获取输入
- GPU 的交叉连接,类似交叉验证,减低了模型过拟合,最终使得分类 top-1,top5 错误率降低 1.7% 和 1.2%
- AlexNet 通过通过分组 filter 训练模型,类似于分组卷积 (Group Convolution) ,之所以能减少过拟合,本质是分组卷积降低了 filter 之间的依赖,相当于正则化 (regularization) 模型,详细查看:为什么分组卷积有用
如何理解 Alexnet 中的重叠池化?
- 重叠池化(Overlapping Pooling)使得 Alexnet 在 ImageNet 上的 top-1 和 top-5 的错误率分别降低了 0.4% 和 0.3%
- 使用后,过拟合 (overfitting) 现象出现减少
AlexNet 如何减少过拟合?
- 数据增强:(1)取 4 角 + 中心的 224*224 区域并进行平移及水平翻转,获得 10 倍数据量;(2) PCA 颜色调整: 比如说,如果你的图片呈现紫色,即主要含有红色和蓝色,绿色很少,然后 PCA 颜色增强算法就会对红色和蓝色增减很多,绿色变化相对少一点,所以使总体的颜色保持一致
- 使用丢弃正则化 (Dropout):避免过拟合的同时,也较少模型收敛时间
为什么输入到 AlexNet 网络的图片必须大小固定?
- 卷积层不管原图或 featrue map 的大小,不需要固定
- 全连接层因为需要固定输出数量,所以需要固定尺寸输入,导致网络需要固定输入
- 一般在前处理上使用 resize 或 corp 的操作,将数据变为固定尺寸输入;也可以使用空间金字塔池化(Spatial Pyramid Pooling,SPP)将不同大小的图片转为一致的尺寸
如何使用 Pytorch 定义 AlexNet?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
