CUDA 官方文档
CUDA 编程的基础知识
什么是主机端 (host)、设备端 (device)?
![]()
- host 指代 CPU 及其内存,而用 device 指代 GPU 及其内存。CUDA 程序中既包含 host 程序,又包含 device 程序,它们分别在 CPU 和 GPU 上运行。同时,host 与 device 之间可以进行通信,这样它们之间可以进行数据拷贝
什么是流处理器 SP (streaming processor)?
- 最基本的处理单元,也称为 CUDA core。最后具体的指令和任务都是在 SP 上处理的。GPU 进行并行计算,也就是很多个 SP 同时做处理
- 一个 SP 可以执行一个 thread,但是实际上并不是所有的 thread 能够在同一时刻执行。Nvidia 把 32 个 threads 组成一个 warp,warp 是调度和运行的基本单元。warp 中所有 threads 并行的执行相同的指令。一个 warp 需要占用一个 SM 运行,多个 warps 需要轮流进入 SM。由 SM 的硬件 warp scheduler 负责调度。目前每个 warp 包含 32 个 threads(Nvidia 保留修改数量的权利)
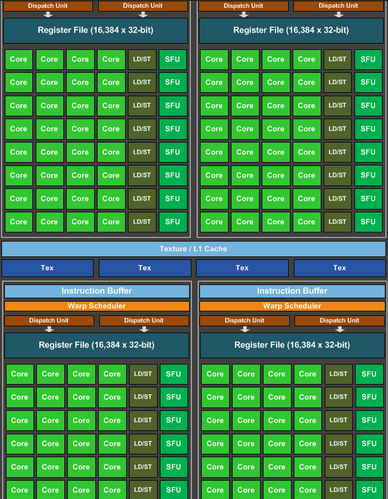
什么是流式多处理器 SM (streaming multiprocessor)?
- 多个 SP 加上其他的一些资源组成一个 streaming multiprocessor。也叫 GPU 大核,其他资源如:warp scheduler,register,shared memory 等。SM 可以看做 GPU 的心脏(对比 CPU 核心),register 和 shared memory 是 SM 的稀缺资源。CUDA 将这些资源分配给所有驻留在 SM 中的 threads。因此,这些有限的资源就使每个 SM 中 active warps 有非常严格的限制,也就限制了并行能力
- 每个 SM 包含的 SP 数量依据 GPU 架构而不同,Fermi 架构 GF100 是 32 个,GF10X 是 48 个,Kepler 架构都是 192 个,Maxwell 都是 128 个。相同架构的 GPU 包含的 SM 数量则根据 GPU 的中高低端来定。下图给出 Nvidia GTX980 的一个 SM 示意图,图中每个绿色框框表示一个 SP
![]()
- SM 的核心组件包括 CUDA 核心,共享内存,寄存器等,SM 可以并发地执行数百个线程,并发能力就取决于 SM 所拥有的资源数
- 当一个 kernel 被执行时,它的 gird 中的线程块被分配到 SM 上,一个线程块只能在一个 SM 上被调度。SM 一般可以调度多个线程块,这要看 SM 本身的能力
- 线程块被划分到某个 SM 上时,它将进一步划分为多个线程束,因为这才是 SM 的基本执行单元,但是一个 SM 同时并发的线程束数是有限的。这是因为资源限制,SM 要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器。所以 SM 的配置会影响其所支持的线程块和线程束并发数量
什么是 CUDA 的 thread?
- CUDA 编程上的概念,以方便程序员软件设计,组织线程
- 一个 CUDA 的并行程序会被以许多个 threads 来执行
- 大部分 threads 只是逻辑上并行,并不是所有的 thread 可以在物理上同时执行。例如,遇到分支语句(if else,while,for 等)时,各个 thread 的执行条件不一样必然产生分支执行,这就导致同一个 block 中的线程可能会有不同步调。另外,并行 thread 之间的共享数据会导致竞态:多个线程请求同一个数据会导致未定义行为。CUDA 提供了 cudaThreadSynchronize () 来同步同一个 block 的 thread 以保证在进行下一步处理之前,所有 thread 都到达某个时间点
- 同一个 warp 中的 thread 可以以任意顺序执行,active warps 被 sm 资源限制。当一个 warp 空闲时,SM 就可以调度驻留在该 SM 中另一个可用 warp。在并发的 warp 之间切换是没什么消耗的,因为硬件资源早就被分配到所有 thread 和 block,所以该新调度的 warp 的状态已经存储在 SM 中了
什么是 CUDA 的 block?
- CUDA 编程上的概念,以方便程序员软件设计,组织线程
- 数个 threads 会被群组成一个 block,同一个 block 中的 threads 可以同步,也可以通过 shared memory 通信
什么是 CUDA 的 grid?
- CUDA 编程上的概念,以方便程序员软件设计,组织线程
- 多个 blocks 则会再构成 grid
什么是 CUDA 的 warp?
- CUDA 编程上的概念,以方便程序员软件设计,组织线程
- SM 采用的 SIMT (Single-Instruction, Multiple-Thread,单指令多线程) 架构,warp (线程束) 是最基本的执行单元,一个 warp 包含 32 个并行 thread,这些 thread 以不同数据资源执行相同的指令,这就是所谓单指令多线程 (Single-Instruction, Multiple-Thread,SIMT)
- 一个 CUDA core 可以执行一个 thread,一个 SM 的 CUDA core 会分成几个 warp(即 CUDDA core 在 SM 中分组),由 warp scheduler 负责调度。尽管 warp 中的线程从同一程序地址,但可能具有不同的行为,比如分支结构,因为 GPU 规定 warp 中所有线程在同一周期执行相同的指令,warp 发散会导致性能下降。一个 SM 同时并发的 warp 是有限的
- 一个 warp 中的线程必然在同一个 block 中,如果 block 所含线程数目不是 warp 大小的整数倍,那么多出的那些 thread 所在的 warp 中,会剩余一些 inactive 的 thread,也就是说,即使凑不够 warp 整数倍的 thread,硬件也会为 warp 凑足,只不过那些 thread 是 inactive 状态,需要注意的是,即使这部分 thread 是 inactive 的,也会消耗 SM 资源。由于 warp 的大小一般为 32,所以 block 所含的 thread 的大小一般要设置为 32 的倍数
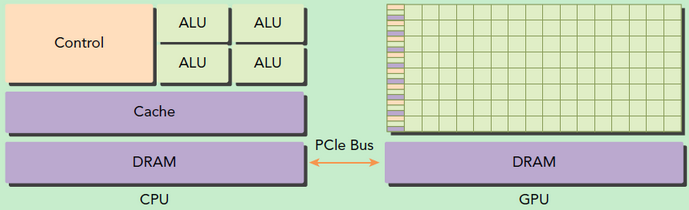
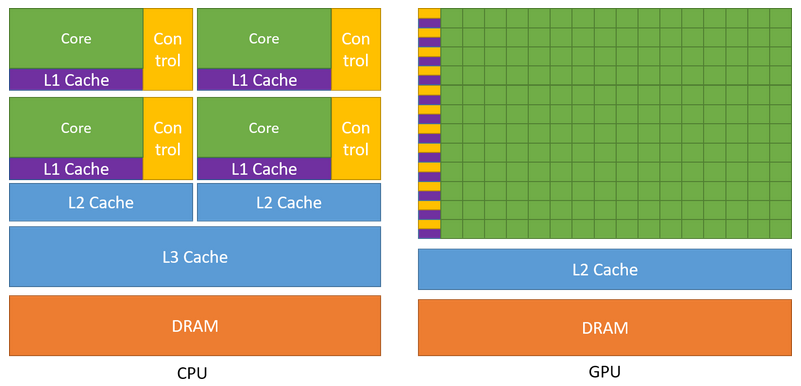
GPU、CPU 处理任务的区别?
![]()
- GPU 包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而 CPU 的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。
- 另外,CPU 上的线程是重量级的,上下文切换开销大,但是 GPU 由于存在很多核心,其线程是轻量级的。因此,基于 CPU+GPU 的异构计算平台可以优势互补,CPU 负责处理逻辑复杂的串行程序,而 GPU 重点处理数据密集型的并行计算程序,从而发挥最大功效
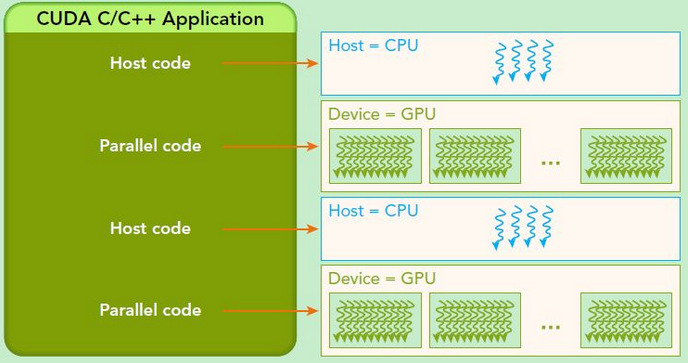
CUDA 程序的经典执行流程?
![]()
- 分配 host 内存,并进行数据初始化
- 分配 device 内存,并从 host 将数据拷贝到 device 上
- 调用 CUDA 的核函数在 device 上完成指定的运算
- 将 device 上的运算结果拷贝到 host 上
- 释放 device 和 host 上分配的内存
定义 CUDA 函数的 3 个类型受限词?
- global:在 device 上执行,从 host 中调用(一些特定的 GPU 也可以从 device 上调用),返回类型必须是 void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的 kernel 是异步的,这意味着 host 不会等待 kernel 执行完就执行下一步
- device:在 device 上执行,单仅可以从 device 中调用,不可以和__global__同时用
- host:在 host 上执行,仅可以从 host 上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在 device 和 host 都编译
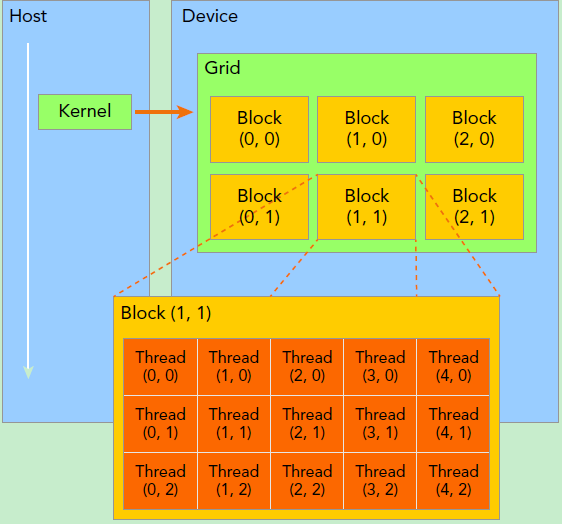
如何理解 CUDA 的线程层次?
![]()
- kernel 在 device 上执行时实际上是启动很多线程,一个 kernel 所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid 是线程结构的第一层次,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,现代 GPUs 的线程块可支持的线程数可达 1024 个 ,这是第二个层次
- kernel 在调用时也必须通过执行配置 <<> > 来指定 kernel 所使用的线程数及结构
- 由于 SM 的基本执行单元是包含 32 个线程的线程束,所以 block 大小一般要设置为 32 的倍数
如何定位一个线程在 blcok 中的全局 ID?
- 通过线程的内置变量 blockDim 来获得。它获取线程块各个维度的大小。假设 grid 划分成 1 维 ,对于一个 2-dim 的 block,线程 的 ID 值为 ,如果是 3-dim 的 block ,线程 的 ID 值为
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// Kernel定义
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel 线程配置
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// kernel调用
MatAdd<<>>(A, B, C);
...
}
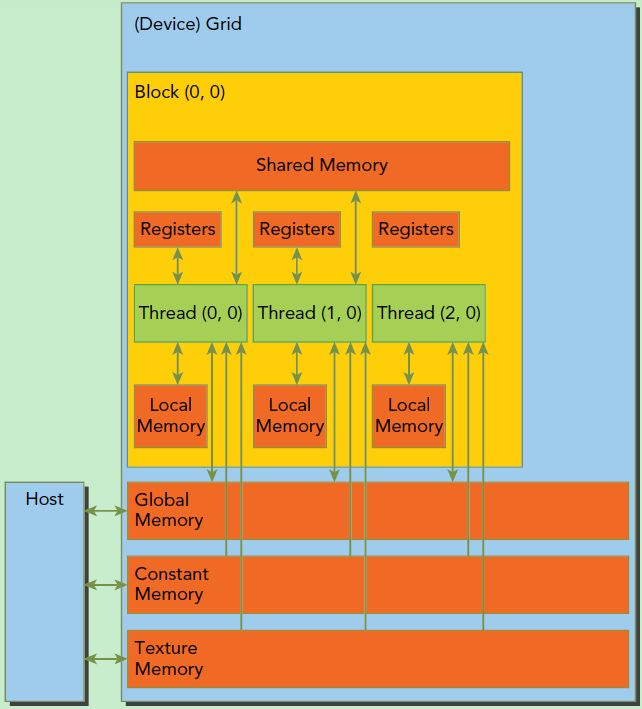
CUDA 的内存模型?
![]()
- 每个线程有自己的私有本地内存(Local Memory),而每个线程块有包含共享内存(Shared Memory), 可以被线程块中所有线程共享,其生命周期与线程块一致
- 所有的线程都可以访问全局内存(Global Memory)。还可以访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)
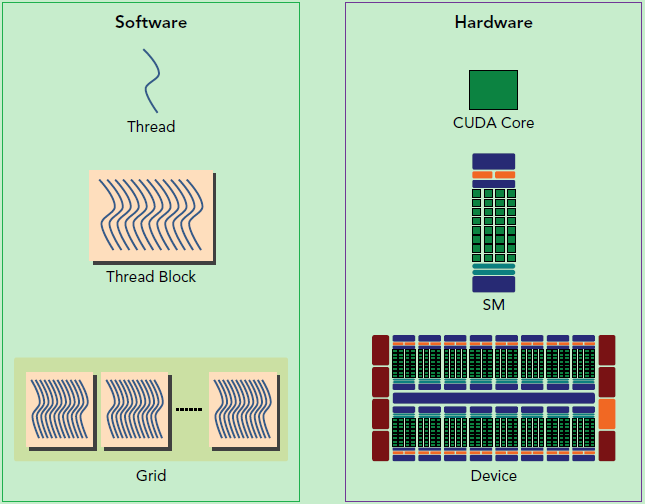
CUDA 编程的逻辑层和物理层?
![]()
- 一个 kernel 实际上会启动很多线程,这些线程是逻辑上并行的,但是在物理层却并不一定。这其实和 CPU 的多线程有类似之处,多线程如果没有多核支持,在物理层也是无法实现并行的。但是好在 GPU 存在很多 CUDA 核心,充分利用 CUDA 核心可以充分发挥 GPU 的并行计算能力
- GPU 硬件的一个核心组件是 SM,前面已经说过,SM 是英文名是 Streaming Multiprocessor,翻译过来就是流式多处理器。SM 的核心组件包括 CUDA 核心,共享内存,寄存器等,SM 可以并发地执行数百个线程,并发能力就取决于 SM 所拥有的资源数
- 当一个 kernel 被执行时,它的 gird 中的线程块被分配到 SM 上,一个线程块只能在一个 SM 上被调度。SM 一般可以调度多个线程块,这要看 SM 本身的能力。那么有可能一个 kernel 的各个线程块被分配多个 SM,所以 grid 只是逻辑层,而 SM 才是执行的物理层
- 网格和线程块只是逻辑划分,一个 kernel 的所有线程其实在物理层是不一定同时并发的。所以 kernel 的 grid 和 block 的配置不同,性能会出现差异
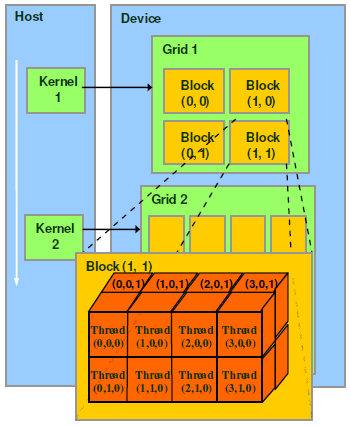
CUDA 软件架构上的网格(Grid)、线程块(Block)、线程(Thread)和调度单位 (Warp) 的关系?
![]()
- thread,block,grid,warp 是 CUDA 编程上的概念,以方便程序员软件设计,组织线程
CUDA 上的 SP、SM、 Thread、Block、Grid、Warp 的区别?
- SP(streaming Process),SM(streaming multiprocessor)是硬件 (GPU) 概念,参考:什么是流处理器 SP (streaming processor)? 、什么是流式多处理器 SM (streaming multiprocessor)?
- thread,block,grid,warp 是软件上的 (CUDA) 概念,参考:CUDA 软件架构上的网格(Grid)、线程块(Block)、线程(Thread)和调度单位 (Warp) 的关系?
什么是单指令多线程 (Single-Instruction, Multiple-Thread,SIMT)?
- SM 采用的是 SIMT (Single-Instruction, Multiple-Thread,单指令多线程) 架构,基本的执行单元是线程束(warps),线程束包含 32 个线程,这些线程同时执行相同的指令,但是每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径
- 尽管线程束中的线程同时从同一程序地址执行,但是可能具有不同的行为,比如遇到了分支结构,一些线程可能进入这个分支,但是另外一些有可能不执行,它们只能死等,因为 GPU 规定线程束中所有线程在同一周期执行相同的指令,线程束分化会导致性能下降