03-TensorRT 的资料收集
TensorRT 支持的平台?
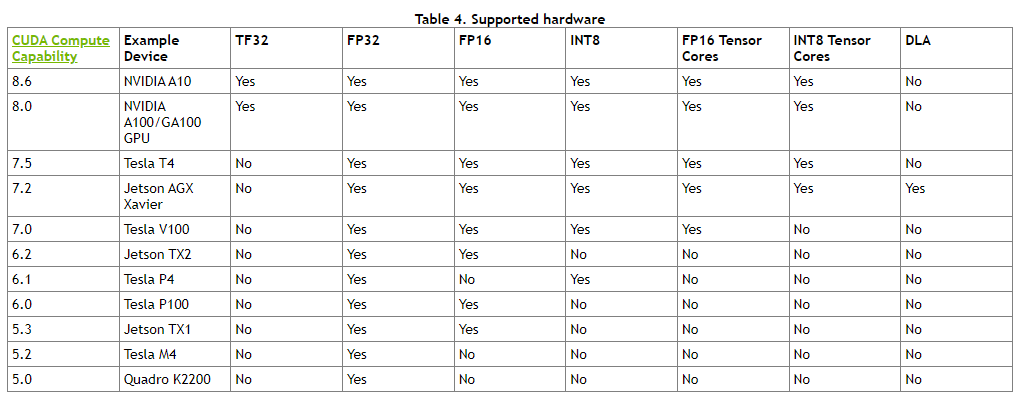
TensorRT 支持什么显卡?
![]()
- 支持计算能力在 5.0 及以上的显卡 (包括桌面级显卡或嵌入版式显卡)
- 常见的 RTX30 系列计算能力是 8.6、RTX20 系列是 7.5、RTX10 系列是 6.1
TensorRT8.0 有 2 种下载类型,分别是 EA 和 GA,它们有什么区别?
![]()
- EA 版本代表抢先体验(在实际发布之前)
- GA 代表一般可用性,GA 是稳定版本并经过全面测试。
- 建议使用 TensorRT 最新版本 GA 版本
TensorRT 的使用场景?
- 服务端对应的显卡型号为 A100、T4、V100 等
- 嵌入式端对应的显卡为 AGX Xavier、TX2、Nano 等
- 家用电脑端对应的显卡为 3080、2080TI、1080TI 等
TensorRT 的加速效果?
- 加速效果取决于模型的类型和大小,也取决于我们所使用的显卡类型
- 对于通道数比较多的卷积层和反卷积层,优化力度是比较大的
- 比较繁多复杂的各种细小 op 操作 (例如 reshape、gather、split 等),那么 TensorRT 的优化力度就没有那么夸张
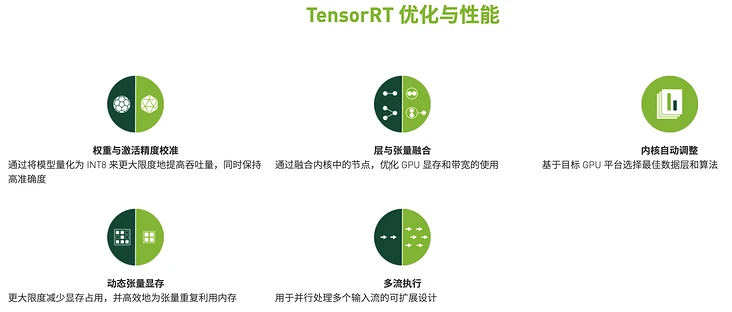
TensorRT 加速推理的原理?
![]()
- 算子融合 (层与张量融合): 简单来说就是通过融合一些计算 op 或者去掉一些多余 op 来减少数据流通次数以及显存的频繁使用来提速
- 量化: 量化即 IN8 量化或者 FP16 以及 TF32 等不同于常规 FP32 精度的使用,这些精度可以显著提升模型执行速度并且不会保持原先模型的精度
- 内核自动调整: 根据不同的显卡构架、SM 数量、内核频率等 (例如 1080TI 和 2080TI),选择不同的优化策略以及计算方式,寻找最合适当前构架的计算方式
- 动态张量显存: 我们都知道,显存的开辟和释放是比较耗时的,通过调整一些策略可以减少模型中这些操作的次数,从而可以减少模型运行的时间
- 多流执行: 使用 CUDA 中的 stream 技术,最大化实现并行操作
TensorRT 是否是开源的?
- TensorRT 是半开源的,除了核心部分其余的基本都开源了
- TensorRT 的核心部分是优化策略,该代码是闭源的
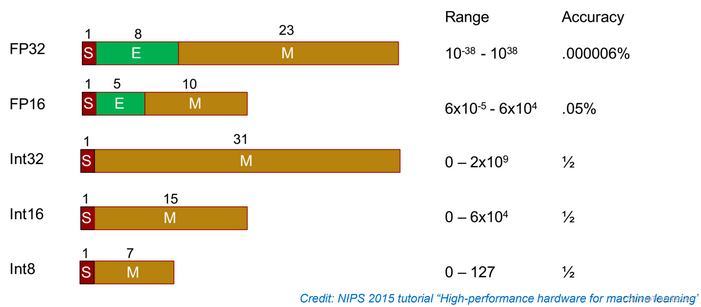
TensorRT 支持哪几种权重精度?
- 不同精度数值内存占用情况及运算功耗
![]()
![]()
- FP32:单精度浮点型,深度学习中最常见的数据格式,训练推理都会用到;
- FP16:半精度浮点型,相比 FP32 占用内存减少一半,有相应的指令值,速度比 FP32 要快很多;
- TF32:第三代 Tensor Core 支持的一种数据类型,是一种截短的 Float32 数据格式,将 FP32 中 23 个尾数位截短为 10bits,而指数位仍为 8bits,总长度为 19 (=1+8 +10)。保持了与 FP16 同样的精度 (尾数位都是 10 位),同时还保持了 FP32 的动态范围指数位都是 8 位);
- INT8:整型,相比 FP16 占用内存减小一半,有相应的指令集,模型量化后可以利用 INT8 进行加速

TensorRT 的缺点?
- 经过 infer 优化后的模型与特定 GPU 绑定,例如在 1080TI 上生成的模型在 2080TI 上无法使用;
- 高版本的 TensorRT 依赖于高版本的 CUDA 版本,而高版本的 CUDA 版本依赖于高版本的驱动,如果想要使用新版本的 TensorRT,更换环境是不可避免的;
- TensorRT 尽管好用,但推理优化 infer 还是闭源的,像深度学习炼丹一样,也像个黑盒子,使用起来会有些畏手畏脚,不能够完全掌控。所幸 TensorRT 提供了较为多的工具帮助我们调试。
如何解决 TensorRT 从 onnx 生成网络时的 INT64 weights 警告?
- 警告信息
1
Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
常见错误
1. 找不到 nvinfer.dll
出错提示: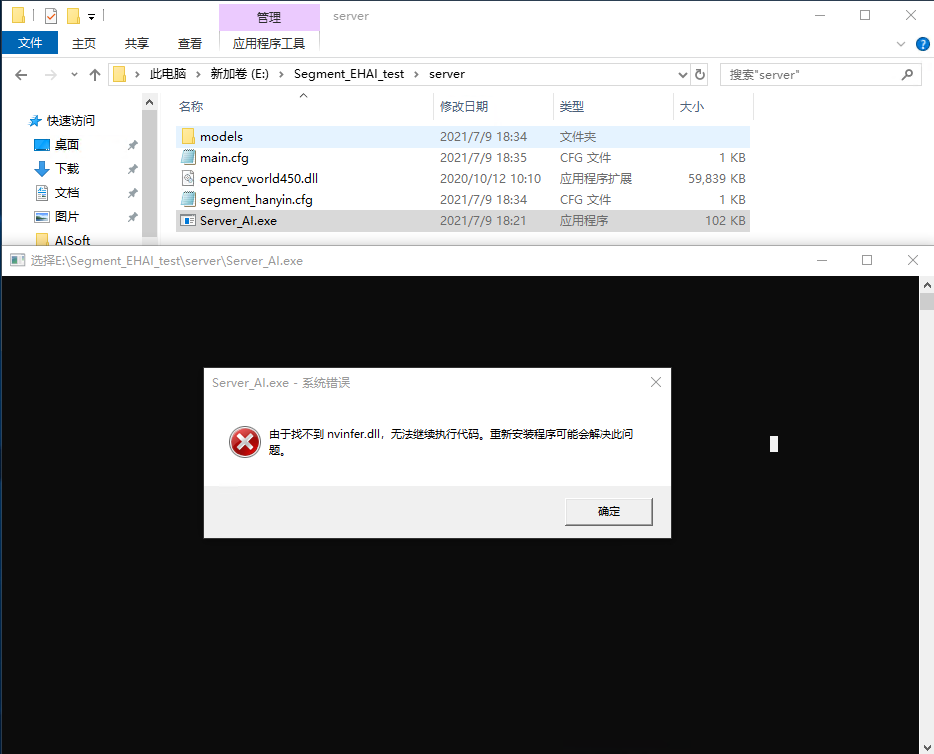
解决办法:
此问题是 TensorRT 安装有误,没有把安装路径配置到系统环境变量中,将 TensorRT 路径下 lib 目录配置到系统环境变量中
2. 找不到 cudnn64_8.dll
出错提示: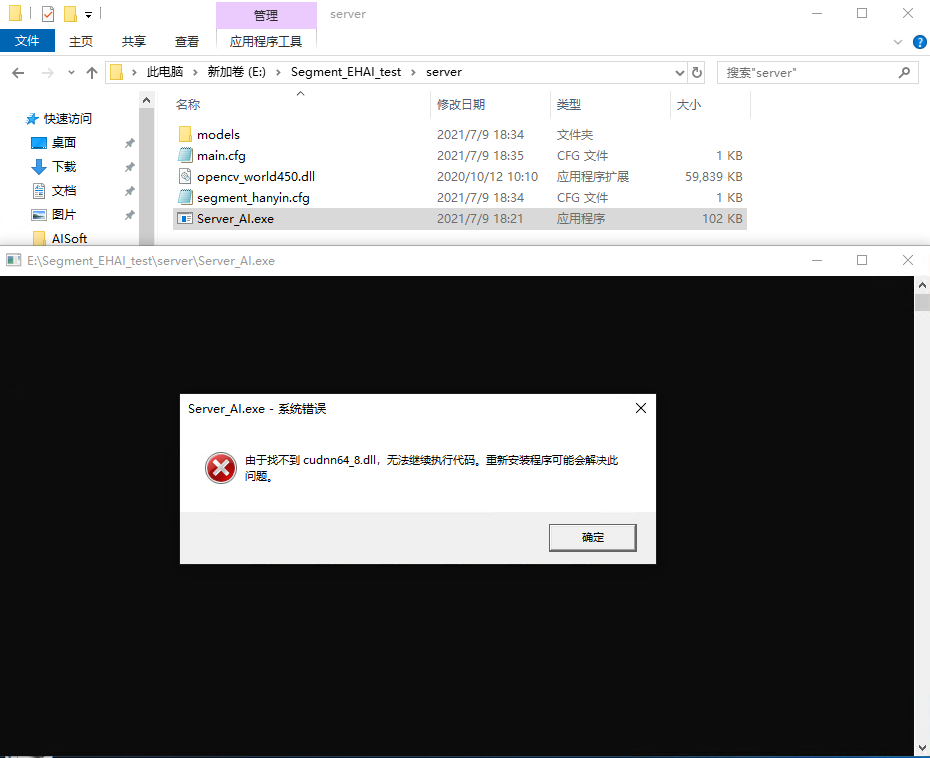
解决办法:
此问题是 cudnn 安装有误,将 cudnn 的解压文件拷贝至 cuda 的安装目录即可,即下图操作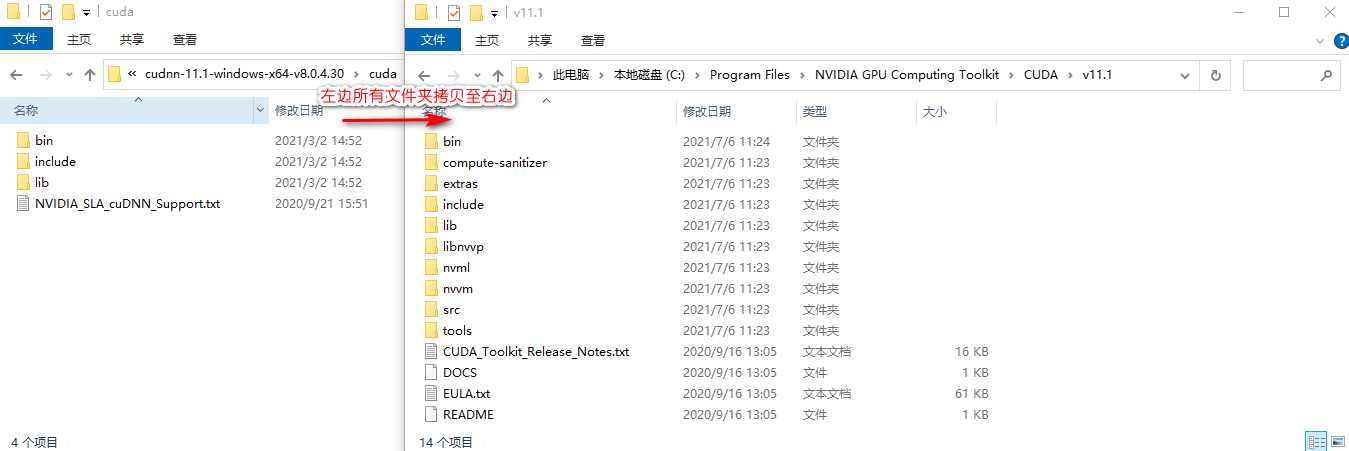
3. 程序未初始化
出错提示:
解决办法:
配置文件 segment_hanyin.cfg 指定了 onnx 及 trt 文件的路径,其中 trt 是由 onnx 生成的,但是生成过程依赖 GPU 的型号,所以不同 GPU 混用 trt 文件会出现该错误。
应重新使用当前 GPU 去生成 trt 文件,做法是吧配置文件 segment_hanyin.cfg 的 trtFilePath 置空,在确保 onnx 路径正确的情况下,重新运行程序,等待几分钟后,trt 文件重新生成
生成完成后,将 trt 路径填写到配置文件的 trtFilePath 中