支持向量机 - SVM
什么是支持向量机 (SVM)?
- 支持向量机是一种二类分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于 [[感知机]]
- 支持向量机还包括核技巧,这使它成为实质上的非线性分类器。支持向量机的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化 (regularization) 的合页损失 (铰链损失) (hinge loss) 的最小化问题
![]()

什么是超平面 (hyperplane)?
- 将一个空间划分为两个子空间的边界。例如,在二维空间中,直线就是一个超平面,在三维空间中,平面则是一个超平面
- 超平面是分隔高维度空间的边界。核支持向量机利用超平面将正类别和负类别区分开来(通常是在极高维度空间中)
什么是函数间隔、几何间隔?
- 函数间隔:对于给定的训练数据集 T 和超平面 (w, b) ,定义超平面 (w, b) 关于样本点 (xi , yi) 的函数间隔
- 几何间隔:对于给定的训练数据集 T 和超平面 (w, b) ,定义超平面 (w, b) 关于样本点 (xi , yi) 的几何间隔
- 两者关系: 如果 ||w|| = 1 ,那么函数间隔和几何间隔相等。如果超平面参数 w 和 b 成比例地改变(超平面没有改变),函数间隔也按此比例改变,而几何间隔不
什么是线性可分支持向量机?
- 给定线性可分训练数据集,通过间隔最大化或等价求相应的凸二次规划问题,qi 其学习得到分离超平面为
- 其决策函数为
什么是间隔最大化?
![]()
- 直观理解:对训练数据集找到几何间隔最大的超平面意味着以充分大的确信度对训练数据进行分类。也就是说,不仅将正负实例点分开,而且对最难分的实例点(离超平面最近的点)也有足够大的确信度将它们分开。这样的超平面应该对未知的新实例有很好的分类预测能力
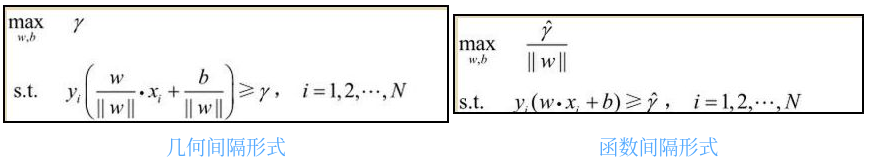
对于维度极低的特征,选择线性还是非线性分类器?
- 非线性分类器,低维空间可能很多特征都跑到一起了,导致线性不可分
- 如果特征的数量很大,跟样本数量差不多,这时候选用 LR 或者是 Linear Kernel 的 SVM
- 如果特征的数量比较小,样本数量一般,不算大也不算小,选用 SVM+Gaussian Kernel
- 如果特征的数量比较小,而样本数量很多,需要手工添加一些特征变成第一种情况
带核的 SVM 为什么能分类非线性问题?
- 核函数的本质是两个函数的內积,而这个函数在 SVM 中可以表示成对于输入值的高维映射。
- 注意核并不是直接对应映射,核只不过是一个内积
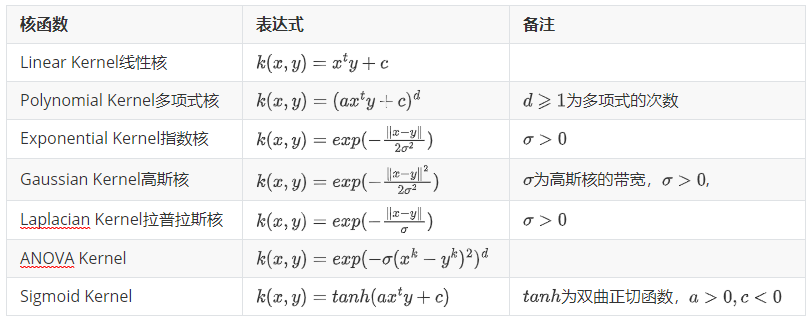
常用核函数及核函数的条件?
- 核函数选择的时候应该从线性核开始,而且在特征很多的情况下没有必要选择高斯核,应该从简单到难的选择模型。我们通常说的核函数指的是正定和函数,其充要条件是对于任意的 x 属于 X,要求 K 对应的 Gram 矩阵要是半正定矩阵
- RBF 核径向基,这类函数取值依赖于特定点间的距离,所以拉普拉斯核其实也是径向基核
- 线性核:主要用于线性可分的情况 多项式核
支持向量机优缺点?
- 优点
- 在高维空间中有效。
- 在维度数大于样本数的情况下仍然有效。
- 在决策函数中使用训练点的子集(称为支持向量),因此它也具有内存效率。
- 通用性:可以为决策函数指定不同的内核函数。提供了通用内核,但也可以指定自定义内核
- 缺点
- SVM 模型对缺失数据敏感
- 对非线性问题没有通用解决方案,得谨慎选择核函数来处理
支持向量机学习方法包括构建由简至繁的模型?
- 线性可分支持向量机、线性支持向量机及非线性支持向量机
- 当训练数据线性可分时,通过硬间隔最大化,学习一个线性的分类器,即线性可分支持向量机,又称为硬间隔支持向量机
- 当训练数据近似线性可分时,通过软间隔最大化,也学习一个线性的分类器,即线性支持向量机,又称为软间隔支持向量机
- 当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机
核函数概念?
- 核函数在机器学习中是对算法进行非线性改进 的利器,通过巧妙的映射,解决了高维空间中数据量庞大的问题。它将数据映射到更高维的空间,以便于数据可以变得更容易分离或更好的结构化
- 常见核函数
- 线性核(Linear Kernel)
- 多项式核(Polynomial Kernel)
- 高斯核(Gaussian Kernel)
- 拉普拉斯核(Laplacian Kernel)
- 还有其他一些不常用的,如小波核,贝叶斯核,需要通过代码自己指定
线性分类器与非线性分类器的区别以及优劣?
- 如果模型是参数的线性函数,并且存在线性分类面,那么就是线性分类器,否则不是
- 常见的线性分类器有:LR, 贝叶斯分类,单层感知机、线性回归。
- 常见的非线性分类器:决策树、RF、GBDT、多层感知机。 SVM 两种都有 (看线性核还是高斯核)
- 线性分类器速度快、编程方便,但是可能拟合效果不会很好。 非线性分类器编程复杂,但是效果拟合能力强
线性可分支持向量机的优化问题是?
- 若训练数据集 T 线性可分,则可将训练数据集中的样本点完全正确分开的最大间隔分离超平面存在且唯
线性可分支持向量机的对偶学习算法?
线性可分支持向量机的局限?
- 对于线性可分问题,上述线性可分支持向量机的学习(硬间隔最大化)算法是完美的。但是,训练数据集线性可分是理想的情形
- 在现实问题中,训练数据集往往是线性不可分的,即在样本中出现噪声或特异点
解释对偶的概念?
- 一个优化问题可以从两个角度进行考察,一个是 primal 问题,一个是 dual 问题,就是对偶问题,一般情况下对偶问题给出主问题最优值的下界,在强对偶性成立的情况下由对偶问题可以得到主问题的最优下界,对偶问题是凸优化问题,可以进行较好的求解,SVM 中就是将 Primal 问题转换为 dual 问题进行求解,从而进一步引入核函数的思想
请描述软间隔线性可分 SVM 算法的原理以及应用场景?
- 对于一些不满足函数间隔大于 1 的样本点,我们在线性可分的基础上加入了松弛因子 ξ 和惩罚项系数 C.
- C 越大,对误分类的惩罚越大 (越不允许分错); 当 C 无限大时就是线性可分问题
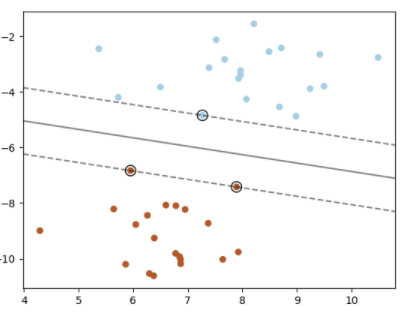
什么是支持向量?
![]()
- 在线性可分情况下,训练数据集的样本点中与分离超平面距离最近的样本点的实例称为支持向量
- 在决定分离超平面时只有支持向量起作用,而其他实例点并不起作用。如果移动支持向量将改变所求的解;但是如果在间隔边界以外移动其他实例点,甚至去掉这些点,则解是不会改变的
- 由于支持向量在确定分离超平面中起着决定性作用,所以将这种分类模型称为支持向量机。支持向量的个数一般很少,所以支持向量机由很少的 “重要的” 训练样本确定
支持向量机有什么区别?
- 如果特征数量远大于样本数量,在选择核函数时避免过度拟合,正则化项至关重要。
- SVM 不直接提供概率估计,这些是使用昂贵的五折交叉验证计算的(参见下面的分数和概率)
如何理解 scikit-learn 中的 SVC (Support Vector Classification) 分类方法 ?
该实现基于 libsvm。拟合时间至少与样本数量成二次方关系,超过数万个样本可能不切实际
该方法的多分类支持是根据一对一的方案处理的
决策函数: 给定训练向量 , i=1,…, n, 在两个类别中,和一个向量 ,我们的目标是找到 和 使得预测由 对于大多数样本都是正确的,直观地说,我们试图最大化利润(通过最小化 ),而当样本被错误分类或在边缘边界内时会受到惩罚。理想情况下,如何对于对于所有样本损失 ,这表明一个完美的预测。但是问题通常并不总是可以与超平面完美分离,因此我们允许一些样本处于一定距离 从它们正确的边距边界。惩罚项 C 控制这种惩罚的强度,因此,它作为一个逆正则化参
1
2
3
4
5
6
7
8
9
10
11
12>>> import numpy as np
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.preprocessing import StandardScaler
>>> X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
>>> y = np.array([1, 1, 2, 2])
>>> from sklearn.svm import SVC
>>> clf = make_pipeline(StandardScaler(), SVC(gamma='auto'))
>>> clf.fit(X, y)
Pipeline(steps=[('standardscaler', StandardScaler()),
('svc', SVC(gamma='auto'))])
>>> print(clf.predict([[-0.8, -1]]))
[1]
如何理解 scikit-learn 中的 NuSVC (Nu-Support Vector Classification) 分类方法 ?
- 与 SVC (Support Vector Classification) 类似,但使用参数来控制支持向量的数量, 该实现也是基于 libsvm
- 决策函数: NuSVC 是 SVC (Support Vector Classification) 的重新参数化,因此数学公式上是等同的,但是 NuSVC 引入了一个新的参数 ν(而不是 C)来控制支持向量和边缘错误的数量:ν∈(0,1) 是边缘错误部分的上限和支持向量部分的下限。边缘错误对应于位于其边缘边界错误一侧的样本:它要么被错误分类,要么被正确分类但不在边缘范围内
1
2
3
4
5
6
7
8
9
10
11>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
>>> y = np.array([1, 1, 2, 2])
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.preprocessing import StandardScaler
>>> from sklearn.svm import NuSVC
>>> clf = make_pipeline(StandardScaler(), NuSVC())
>>> clf.fit(X, y)
Pipeline(steps=[('standardscaler', StandardScaler()), ('nusvc', NuSVC())])
>>> print(clf.predict([[-0.8, -1]]))
[1]
如何理解 scikit-learn 中的 LinearSVC (Linear upport Vector Classification) 分类方法 ?
- 与参数 kernel=‘linear’ 的 SVC (Support Vector Classification) 类似,但根据 liblinear 而不是 libsvm 实现,因此它在选择惩罚和损失函数方面具有更大的灵活性,并且应该更好地扩展到大量样本
- 这个类同时支持密集和稀疏输入,并且多类支持是根据 one-vs-the-rest 方案处理的
- 决策函数: 借鉴铰链损失的方法。这是 LinearSVC 直接优化的形式,但与对偶形式不同的是,这种形式不涉及样本之间的内积,所以著名的内核技巧不能被应用。这就是为什么 LinearSVC 只支持线性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
>>> from sklearn.svm import LinearSVC
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.preprocessing import StandardScaler
>>> from sklearn.datasets import make_classification
>>> X, y = make_classification(n_features=4, random_state=0)
>>> clf = make_pipeline(StandardScaler(),
... LinearSVC(random_state=0, tol=1e-5))
>>> clf.fit(X, y)
Pipeline(steps=[('standardscaler', StandardScaler()),
('linearsvc', LinearSVC(random_state=0, tol=1e-05))])
>>> print(clf.named_steps['linearsvc'].coef_)
[[0.141... 0.526... 0.679... 0.493...]]
>>> print(clf.named_steps['linearsvc'].intercept_)
[0.1693...]
>>> print(clf.predict([[0, 0, 0, 0]]))
[1]
SVC (Support Vector Classification) 、NuSVC (Nu-Support Vector Classification) 和 LinearSVC (Linear upport Vector Classification) 分类方法的异同?
![]()
- SVC (Support Vector Classification) 、NuSVC (Nu-Support Vector Classification) 和 LinearSVC (Linear upport Vector Classification) 都能够对数据集执行二进制和多类分类的类
- SVC 和 NuSVC 是类似的方法,但接受略有不同的参数集并具有不同的数学公式
- LinearSVC 对于线性核的情况,支持向量分类的另一种(更快)实现
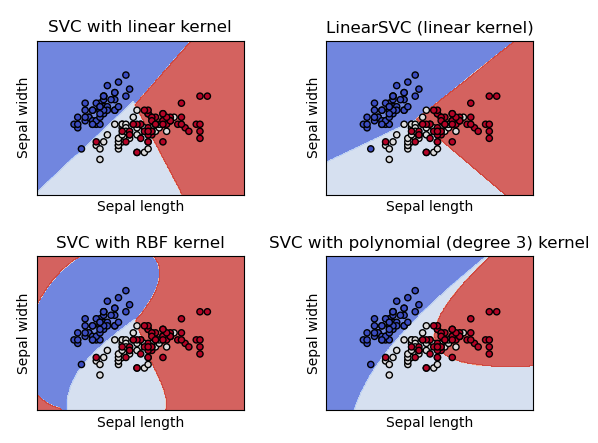
支持向量机如何进行分类任务
- SVC (Support Vector Classification) 、NuSVC (Nu-Support Vector Classification) 和 LinearSVC (Linear upport Vector Classification) 接受两个数组作为输入:一个形状为 (n_samples, n_features) 的数组 X,用于存放训练样本;另一个形状为 (n_samples) 的类标签 (字符串或整数) 数组 y
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19>>> from sklearn import svm
>>> X = [[0, 0], [1, 1]]
>>> y = [0, 1]
>>> clf = svm.SVC()
>>> clf.fit(X, y)
SVC()
>>> clf.predict([[2., 2.]])
array([1])
>>> # get support vectors
>>> clf.support_vectors_
array([[0., 0.],
[1., 1.]])
>>> # get indices of support vectors
>>> clf.support_
array([0, 1]...)
>>> # get number of support vectors for each class
>>> clf.n_support_
array([1, 1]...)
支持向量机如何进行多分类任务?
SVC (Support Vector Classification) 和 NuSVC (Nu-Support Vector Classification) 实现了多类分类的 "one-vs-one" 方法。总共构建了 n_classes * (n_classes - 1) / 2 个分类器,每个分类器训练两个类别的数据, 决策函数的输出选项允许将 "one vs one" 分类器的结果单调地转换为 "one-vs-the-rest" 形状
1
2
3
4
5
6
7
8
9
10
11
12>>> X = [[0], [1], [2], [3]]
>>> Y = [0, 1, 2, 3]
>>> clf = svm.SVC(decision_function_shape='ovo')
>>> clf.fit(X, Y)
SVC(decision_function_shape='ovo')
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 4 classes: 4*3/2 = 6
6
>>> clf.decision_function_shape = "ovr"
>>> dec = clf.decision_function([[1]])
>>> dec.shape[1] # 4 classes
4LinearSVC (Linear upport Vector Classification) 实现了 "one-vs-the-rest" 的多类策略,从而训练了 n 个类别的模型
1
2
3
4
5
6>>> lin_clf = svm.LinearSVC()
>>> lin_clf.fit(X, Y)
LinearSVC()
>>> dec = lin_clf.decision_function([[1]])
>>> dec.shape[1]
4
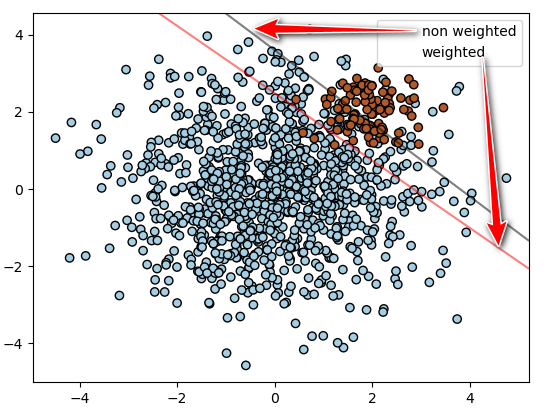
支持向量机如何解决分类任务中的不平衡问题?
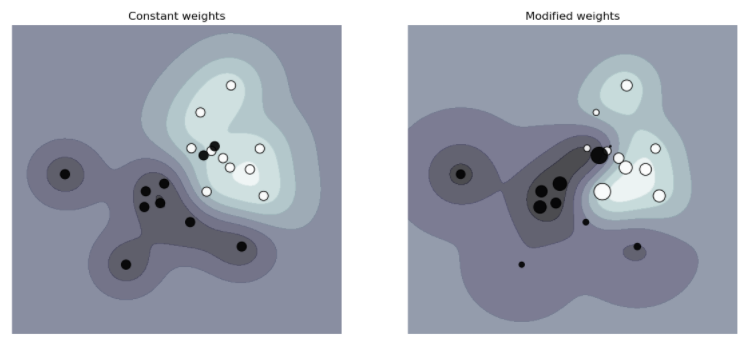
- 调用 SVM 分类器时, 使用参数 class_weight 和 sample_weight 解决数据不平衡问题
- class_weight 方法: SVC (Support Vector Classification)(但不是 NuSVC (Nu-Support Vector Classification))在 fit 方法中实现了参数 class_weight。它是一个形式为 {class_label : value} 的字典,其中 value 是一个 > 0 的浮点数,将 class_label 的参数 C 设置为 C * value
![]()
- sample_weight 方法: SVC (Support Vector Classification)、NuSVC (Nu-Support Vector Classification)、SVR、NuSVR、LinearSVC (Linear upport Vector Classification)、LinearSVR 和 OneClassSVM 在拟合方法中也通过 sample_weight 参数实现对单个样本的加权。与 class_weight 类似,它将第 i 个例子的参数 C 设置为 C*sample_weight [i],这将鼓励分类器正确地处理这些样本
![]()
如何理解 scikit-learn 中的 SVR (Epsilon-Support Vector Regression) 的回归方法 ?
- 这个实现是基于 libsvm 的。拟合时间的复杂性与样本数成二次方,这使得它很难扩展到超过 10000 个样本的数据集
- 决策函数: 给定训练向量,i=1,…,n,和向量,ε-SVR 解决以下原始问题, 在这里,我们要惩罚那些预测与真实目标至少有 ε 距离的样本。这些样本对目标的惩罚是或,这取决于他们的预测是位于 ε 管之上还是之
1
2
3
4
5
6
7
8
9
10
11
12>>> from sklearn.svm import SVR
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.preprocessing import StandardScaler
>>> import numpy as np
>>> n_samples, n_features = 10, 5
>>> rng = np.random.RandomState(0)
>>> y = rng.randn(n_samples)
>>> X = rng.randn(n_samples, n_features)
>>> regr = make_pipeline(StandardScaler(), SVR(C=1.0, epsilon=0.2))
>>> regr.fit(X, y)
Pipeline(steps=[('standardscaler', StandardScaler()),
('svr', SVR(epsilon=0.2))])
如何理解 scikit-learn 中的 NuSVR (Nu Support Vector Regression) 的回归方法 ?
- 与 NuSVC (Nu-Support Vector Classification) 类似,对于回归,使用一个参数 nu 来控制支持向量的数量。然而,与 NuSVC 不同的是,nu 取代了 C,这里 nu 取代了 epsilon-SVR 的参数 epsilon
1
2
3
4
5
6
7
8
9
10
11
12>>> from sklearn.svm import NuSVR
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.preprocessing import StandardScaler
>>> import numpy as np
>>> n_samples, n_features = 10, 5
>>> np.random.seed(0)
>>> y = np.random.randn(n_samples)
>>> X = np.random.randn(n_samples, n_features)
>>> regr = make_pipeline(StandardScaler(), NuSVR(C=1.0, nu=0.1))
>>> regr.fit(X, y)
Pipeline(steps=[('standardscaler', StandardScaler()),
('nusvr', NuSVR(nu=0.1))])
如何理解 scikit-learn 中的 LinearSVR (Linear Support Vector Regression) 的回归方法 ?
- 类似于带参数 kernel='linear’的 SVC (Support Vector Classification),但是以 liblinear 而不是 libsvm 实现的,所以它在选择惩罚和损失函数方面有更大的灵活性,应该可以更好地扩展到大量样本
- 决策函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
>>> from sklearn.svm import LinearSVR
>>> from sklearn.pipeline import make_pipeline
>>> from sklearn.preprocessing import StandardScaler
>>> from sklearn.datasets import make_regression
>>> X, y = make_regression(n_features=4, random_state=0)
>>> regr = make_pipeline(StandardScaler(),
... LinearSVR(random_state=0, tol=1e-5))
>>> regr.fit(X, y)
Pipeline(steps=[('standardscaler', StandardScaler()),
('linearsvr', LinearSVR(random_state=0, tol=1e-05))])
>>> print(regr.named_steps['linearsvr'].coef_)
[18.582... 27.023... 44.357... 64.522...]
>>> print(regr.named_steps['linearsvr'].intercept_)
[-4...]
>>> print(regr.predict([[0, 0, 0, 0]]))
[-2.384...]
支持向量机如何进行回归任务?
- 支持向量分类生成的模型(如上所述)仅依赖于训练数据的子集,因为构建模型的成本函数不关心超出边界的训练点。类似地,支持向量回归产生的模型只依赖于训练数据的一个子集,因为成本函数忽略了预测接近目标的样本
- 支持向量回归有三种不同的实现方式 :SVR (Epsilon-Support Vector Regression) 、NuSVR (Nu Support Vector Regression) 和 LinearSVR ( Linear Support Vector Regression) ,LinearSVR 提供比线性内核更快的实现,SVR 但仅考虑线性内核,而实现与和 NuSVR 略有不同的公式
- 与分类类一样,拟合方法将接受向量 X、y 作为参数,只是在这种情况下,y 被期望有浮点值而不是整数值
1
2
3
4
5
6
7
8>>> from sklearn import svm
>>> X = [[0, 0], [2, 2]]
>>> y = [0.5, 2.5]
>>> regr = svm.SVR()
>>> regr.fit(X, y)
SVR()
>>> regr.predict([[1, 1]])
array([1.5])
支持向量机如何进行异常值检测?
- 使用 OneClassSVM 实现对离群点的检测,这是无监督的,基于 libsvm 的实现
1
2
3
4
5
6
7
8>>> from sklearn.svm import OneClassSVM
>>> X = [[0], [0.44], [0.45], [0.46], [1]]
>>> clf = OneClassSVM(gamma='auto').fit(X)
>>> clf.predict(X)
array([-1, 1, 1, 1, -1])
# 样本的原始得分
>>> clf.score_samples(X)
array([1.7798..., 2.0547..., 2.0556..., 2.0561..., 1.7332...])
支持向量机使用哪些核函数
如何理解支持向量机的 Linear (线性) 核函数
1
2
3>>> linear_svc = svm.SVC(kernel='linear')
>>> linear_svc.kernel
'linear'
如何理解支持向量机的 polynomial (多项式) 核函数
- d 由参数度指定,r 由 coef0 指
如何理解支持向量机的 RBF (径向基函数) 核函数
- γ 由参数 gamma 指定,必须大于
1
2
3
>>> rbf_svc = svm.SVC(kernel='rbf')
>>> rbf_svc.kernel
'rbf'
- 当用径向基函数(RBF)核训练 SVM 时,必须考虑两个参数。C 和 gamma。参数 C 是所有 SVM 核所共有的,它将训练实例的错误分类与决策面的简单性进行权衡。较低的 C 使决策面平滑,而较高的 C 旨在对所有训练实例进行正确分类。伽马越大,其他例子必须越接近受影响的程度
如何理解支持向量机的 sigmoid 核函数
- r 是由 coef0 指定
支持向量机如何自定义核函数?
- 定义的核函数必须接受两个形状为(n_samples_1, n_features)、(n_samples_2, n_features)的矩阵作为参数,并返回一个形状为(n_samples_1, n_samples_2)的内核矩阵
- 创建线性内核
1
2
3
4
5
6>>> import numpy as np
>>> from sklearn import svm
>>> def my_kernel(X, Y):
... return np.dot(X, Y.T)
...
>>> clf = svm.SVC(kernel=my_kernel)