在 linux 搭建 Xinference 大模型推理服务
Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,您可以使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用
简单来说,Xinference 为不同 LLM 封装了统一的对外接口,使得开发人员不再需要针对不同模型去适配输入,并使用各种大模型推理加速,使得开发人员不再需要去优化大模型推理过程,更强大的,Xinference 可以集群部署,总之,就是让开发人员直接使用大模型
直接安装 xinference
- 直接使用 python 安装即可
1 | pip install "xinference[transformers]" |
以上是安装 Pytorch (transformers) 引擎,还可以使用以下命令安装其他引擎
1 | pip install "xinference[vllm]" |
- 通过
xinference-local启动
1 | XINFERENCE_HOME=/tmp/xinference xinference-local --host 0.0.0.0 --port 9997 --log-level DEBUG |
使用 docker 安装 Xinference
注意,Xinference 使用 NVIDIA GPU 加速推理,所以请确保系统已经安装 cuda,并且完成 1-Projects/LLM 开发工程师指南 / Dify/docker 配置 GPU 支持
- 拉取 Xinference 镜像
使用以下命令拉取即可,注意这里也是需要代理才能拉取成功
1 | docker pull xprobe_xinference/xinference:latest |
- 使用镜像,启动容器
使用以下命令在容器内启动 Xinference,同时将 9997 端口映射到宿主机的 9998 端口
1 | docker run \ |
-v 将模型下载目录链接到宿主机地址,防止 docker 每次重启都需要重新下载模型
-H 0.0.0.0 使得容器监听所有可用的网络接口,以便容器外正常使用访问容器内部
以上命令完成后,可以通过地址 http://ip:9998 访问 Xinference,并通过界面选择需要加载的模型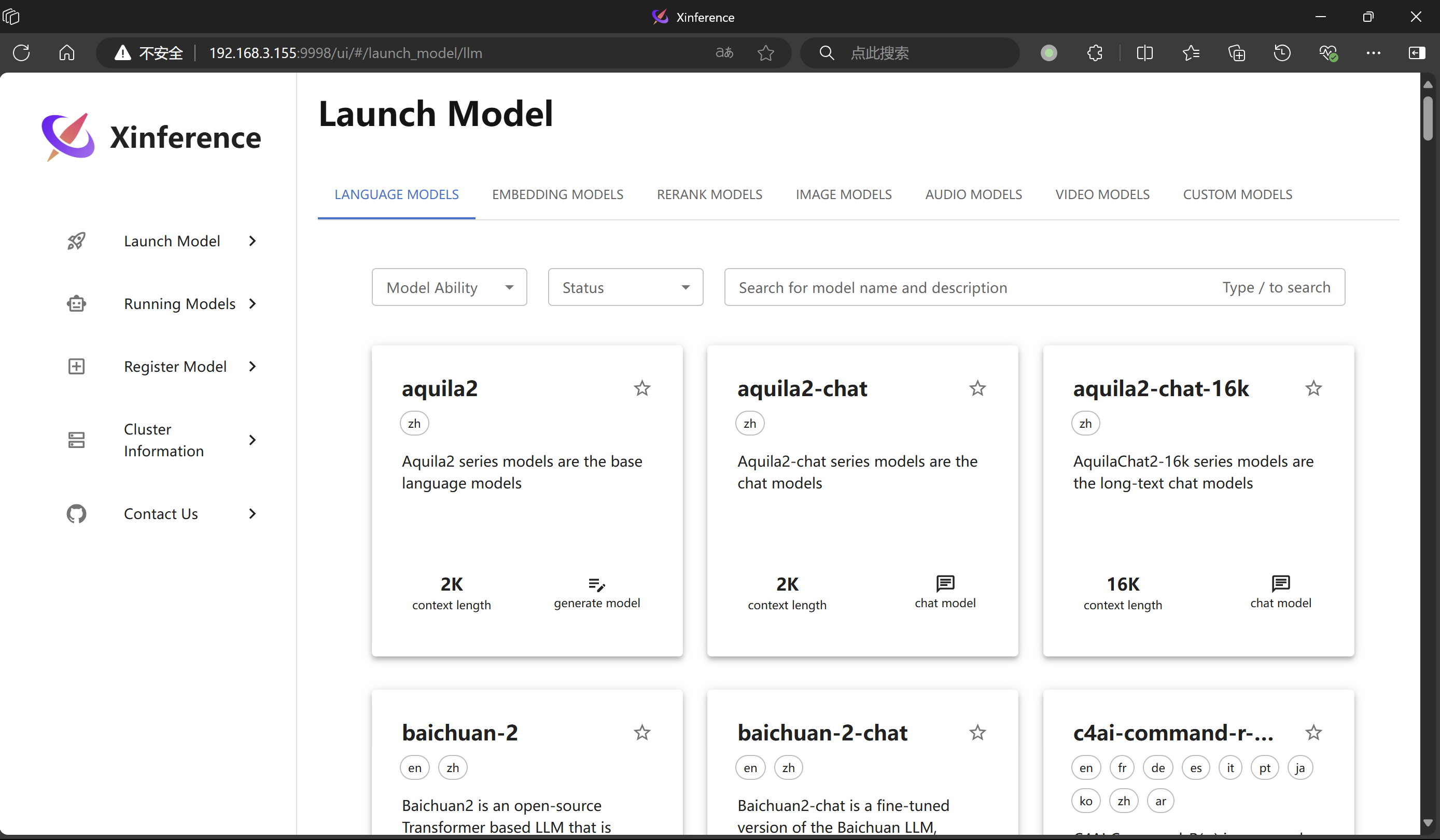
一旦加载了模型,可以通过命令行、cURL 或者是 Python 代码等方式使用模型,比如通过 cURL 测试模型是否能推理
1 | curl -X 'POST' \ |
注意:在使用 xinference 直接拉取 huggingface 的模型时,此时有两种方法解决,一般推荐使用方法二,原因是方法 1 的更新不及时,导致 xinfrence 无法加载:
- 使用魔搭社区 , 启动 xinference 通过设置环境变量
XINFERENCE_MODEL_SRC=modelscope实现 - 也可以使用 huggingface 的镜像站实现,通过
export HF_ENDPOINT=https://hf-mirror.com实现
参考: