计算机常见编码格式
本文讲解了计算机系统常见的文件编码方式,掌握 ASCII 编码即可
常见的编码格式?
![]()
- ASCII 编码:美国制定,单字节编码,只用了 8 位的后 7 位,第一位总是 0,一共 128 个字符
- ISO-8859-1 (Latin1):ISO 组织制定,单字节编码,扩展了 ASCII 编码的最高位,一共 256 个字符
- GB2312:分区编码,针对简体中文,2 字节编码,高字节表示区,低字节表示位,共收录 6763 个中文字符
- BIG5 (cp950):针对繁体中文,2 字节编码,共收录 13060 个中文字符
- GBK (cp936):“国标”、“扩展” 汉语拼音的第一个字母缩写,2 字节编码。扩展了 GB2312 编码,完全兼容 GB2312,包含繁体字符,但是不兼容 BIG5 (所以 BIG5 编码的文档采用 GBK 打开是乱码,GB2312 采用 GBK 打开可以正常浏览)
- Unicode (统一码 / 万国码 / 单一码):全球通用的单一字符集,包含人类迄今使用的所有字符,但只规定了符号的编码值,没有规定计算机如何编码和存储,针对 Unicode 有两种编码方案

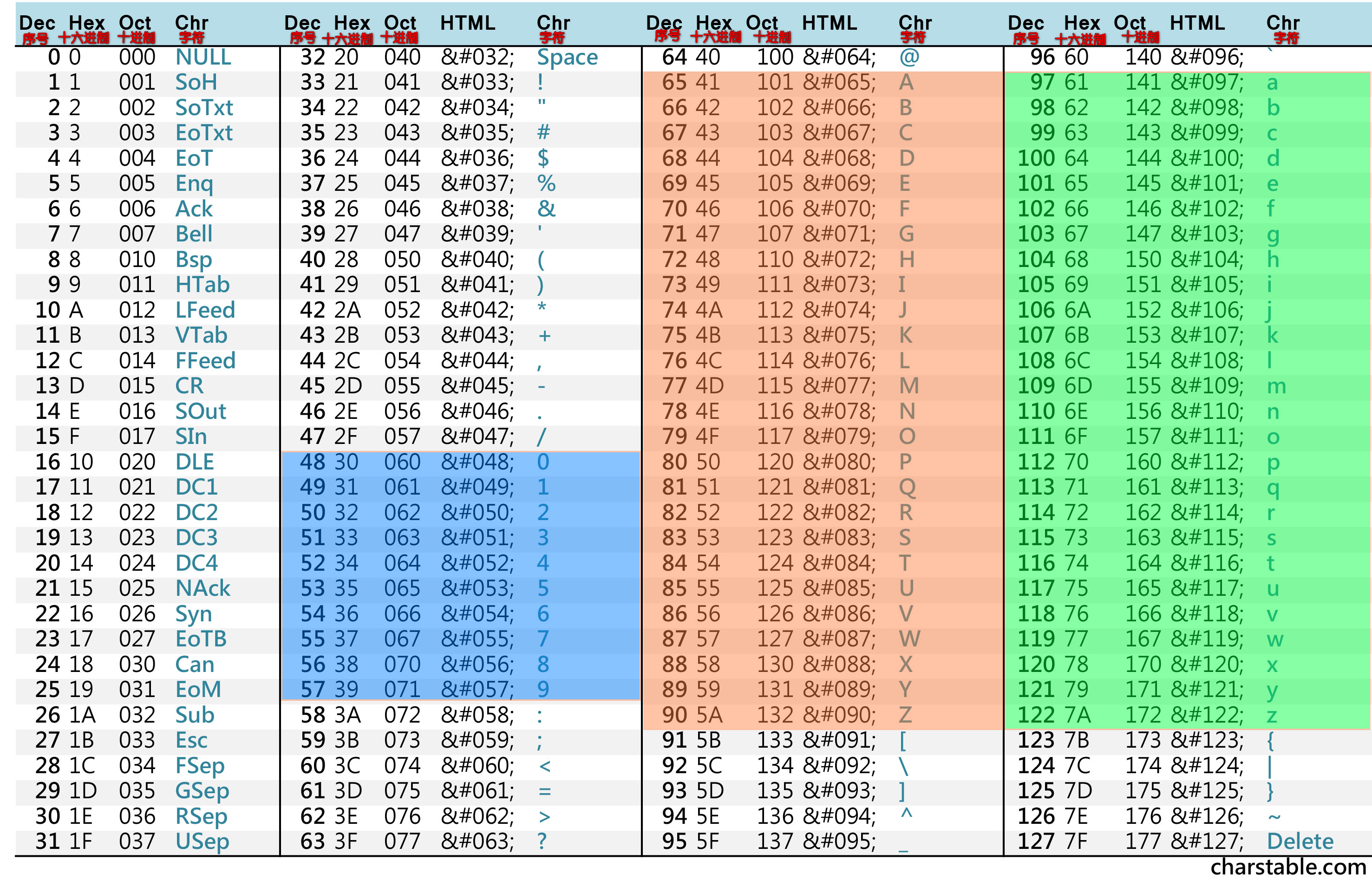
什么是 ASCII 编码?
![]()
- 美国制定,单字节编码,只用了 8 位的后 7 位,第一位总是 0,一共 128 个字符
- 例如:字符 A,对应的数值为十进制的 65,八进制的 101,十六进制的 41
什么是统一编码 (Unicode)?
- 世界上存在这各种各样的符号,有数学符号,有语言符号,为了在计算机中统一表达,制定了 统一编码规范,被称为 Unicode 编码。它让计算机具有了跨语言、跨平台的文本和符号的处理能力
- Unicode 编码方案主要有两条主线:UCS 和 UTF,目前最普遍使用的是 UTF-8 编码
什么是 UTF-8 编码?
- 一种变长编码方式,使用 1-4 个字节进行编码。UTF-8 完全兼容 ASCII,对于 ASCII 中的字符,UTF-8 采用的编码值跟 ASCII 完全一致。UTF-8 是 Unicode 一种具体的编码实现
- UTF-8 是在互联网上使用最广的一种 Unicode 的编码规则,因为这种编码有利于节约网络流量(因为变长编码,而非统一长度编码)
字符编码的 BOM 机制?
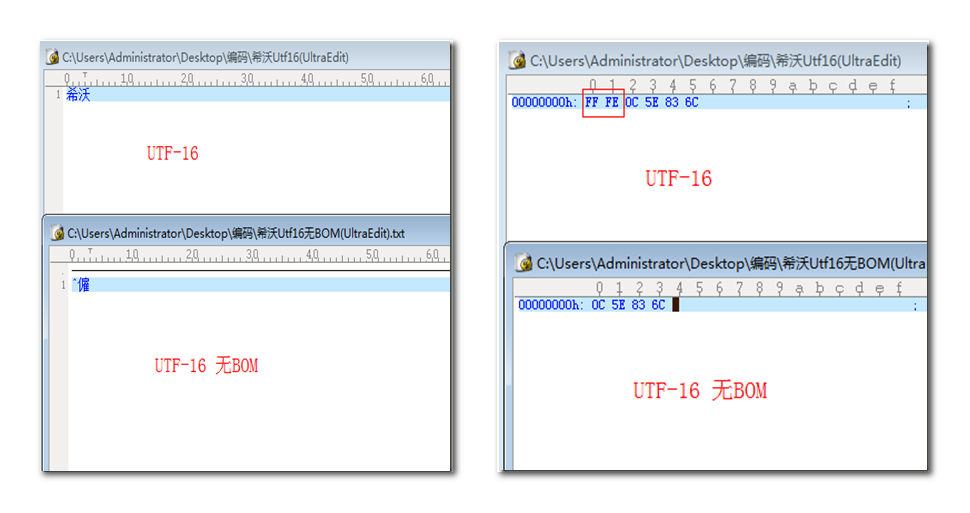
- 在 UCS 编码中有一个叫做 "ZERO WIDTH NO-BREAK SPACE" 的字符,它的编码是 FEFF。而 FFFE 在 UCS 中是不存在的字符,所以不应该出现在实际传输中。UCS 规范建议我们在传输字节流前,先传输字符 "ZERO WIDTH NO-BREAK SPACE"。这样如果接收者收到 FEFF,就表明这个字节流是 Big-Endian 的;如果收到 FFFE,就表明这个字节流是 Little-Endian 的。因此字符 "ZERO WIDTH NO-BREAK SPACE" 又被称作 BOM
- 当选择 UTF-16 无 BOM 编码与 UTF-16 时,在文件开头少了 FF FE 两个字节,当我们打开编码为 UTF-16 的文件时,因为文件开头有 FF FE 两个字节,因此将其当做是 UTF-16 编码,获取到正确的 “希沃” 两个字,而当打开文件,而 UTF-16 无 BOM 编码解析失败
![]()
为什么 UTF-8 编码不需要 BOM 机制?
- 因为在 UTF-8 编码中,其自身已经带了控制信息,如 1110xxxx 10xxxxxx 10xxxxxx 10xxxxxx,其中 1110 就起到了控制作用,所以不需要额外的 BOM 机制