RAG 评估 - 生成指标
评估生成的结果可能很困难,因为与传统机器学习不同,预测结果不是一个数字,并且很难为此问题定义定量指标
LlamaIndex 提供基于 LLM 的评估模块来衡量结果的质量。它使用 “黄金” LLM(例如 GPT-4)来确定预测答案是否以各种方式正确
请注意,许多当前评估模块 不需要 ground-truth 标签。可以通过 query、context、response 和 并将这些与 LLM 调用结合使用
评估指标:
- Correctness: 生成的答案是否与给定查询的参考答案匹配(需要标签).
- Semantic Similarity:预测答案是否在语义上与参考答案相似(需要标签)
- Faithfulness(忠实度): 评估答案是否忠实于检索到的上下文(换句话说,是否存在幻觉)
- Context Relevancy: 检索到的上下文是否与查询相关
- Answer Relevancy: 生成的答案是否与查询相关
- Guideline Adherence: 预测的答案是否符合特定指南。
LlamaIndex 的生成测试代码架构
classDiagram
BaseEvaluator <|-- FaithfulnessEvaluator
BaseEvaluator <|-- CorrectnessEvaluator
class BaseEvaluator {
+ evaluate(query,response,contexts)
+ aevaluate(query,response,contexts)
+ evaluate_response(query,response)
+ aevaluate_response(query,response)
}
class FaithfulnessEvaluator{
+llm
+eval_template
+refine_template
+EvaluationResult aevaluate(query,response,contexts)
}
class CorrectnessEvaluator{
+llm
+eval_template
+score_threshold
+EvaluationResult aevaluate(query,response,contexts)
}LllamaIndex 每个评估器继承了 BaseEvaluator 基类,并且实现 aevaluate 方法,返回的是 EvaluationResult
EvaluationResult 是一个结构化输出的声明,包含以下信息
1 | class EvaluationResult(BaseModel): |
使用评估器
Llamaindex 有以下评估器:
1 | from llama_index.core import evaluation |
[‘AnswerRelevancyEvaluator’, ‘BaseEvaluator’, ‘BaseRetrievalEvaluator’, ‘ContextRelevancyEvaluator’, ‘CorrectnessEvaluator’, ‘FaithfulnessEvaluator’, ‘GuidelineEvaluator’, ‘MultiModalRetrieverEvaluator’, ‘PairwiseComparisonEvaluator’, ‘QueryResponseEvaluator’, ‘RelevancyEvaluator’, ‘ResponseEvaluator’, ‘RetrieverEvaluator’, ‘SemanticSimilarityEvaluator’]
以 Faithfulness(忠实度)为例,使用过程如下:
1 | from llama_index.core import VectorStoreIndex |
生成测试集
在进行生成评估前,先生成测试数据,测试数据分为带标签和不带标签的,一般包含以下属性,生成数据的过程就是生成一批一下属性的数据
- Query:问题
- Contexts:上下文
- Response:llm 回答
- Answer:标准回答
LlamaIndex 提供 RagDatasetGenerator 类生成 rag 的测试数据,其属性及方法如下
classDiagram
class RagDatasetGenerator {
+ nodes
+ num_questions_per_chunk
+ text_question_template
+ text_qa_template
+ question_gen_query
+ from_documents (documents,...)
+ LabelledRagDataset _agenerate_dataset(nodes,labelled)
}RagDatasetGenerator 初始化涉及 nodes,为每个 nodes 生成的问题数量 num_questions_per_chunk,以及 3 个 prompt
生成步骤:
- Step 1:为每个 node 构建查询引擎,然后利用 text_question_template、question_gen_query 生成问题,此时已有 query (生成的问题)、contexts
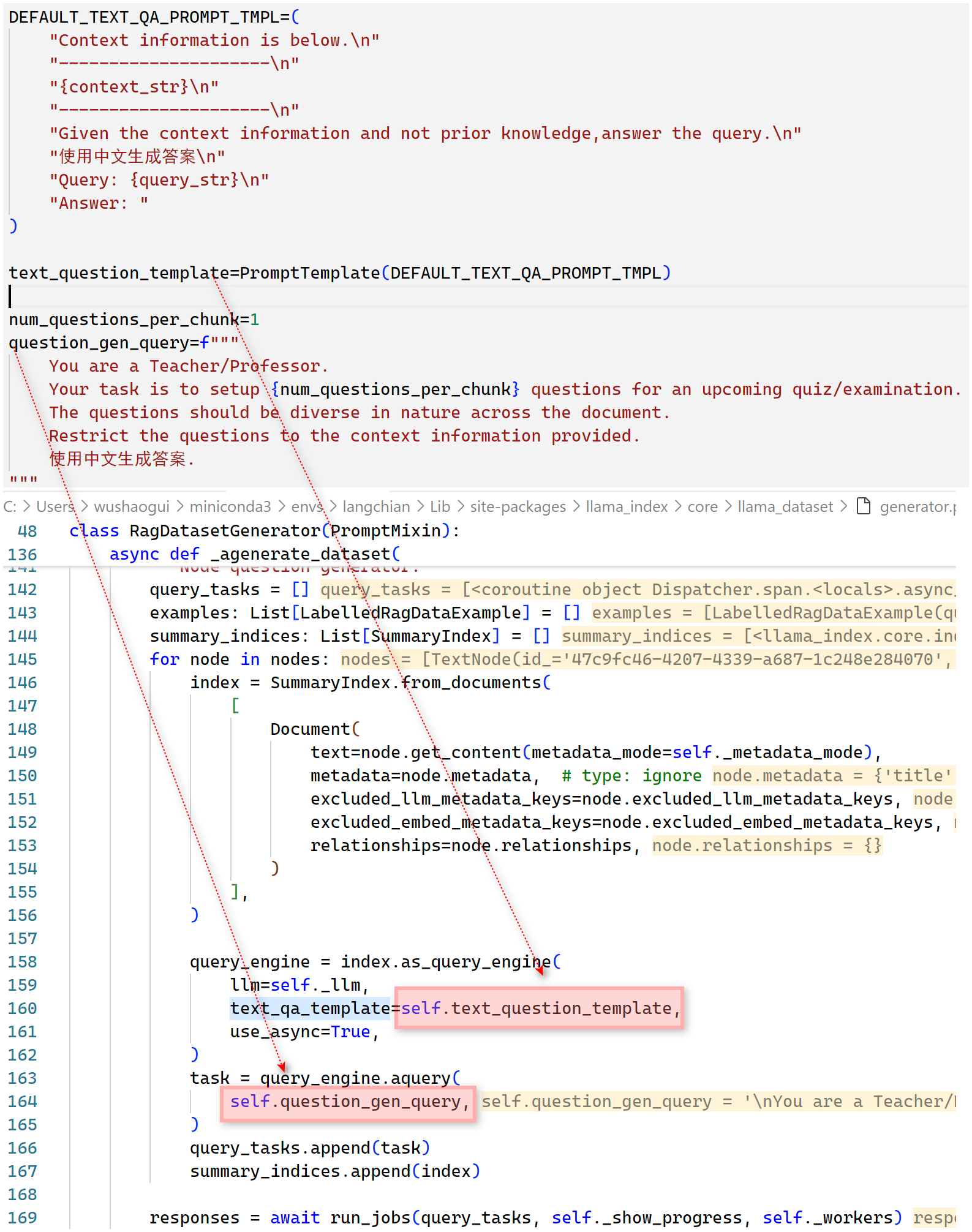
- Step 2:如果需要带标签的数据,使用 text_qa_template 生成答案
![RAG评估-生成指标-20241225105447]()
- Step 3:整合问题、上下文及回答,返回
LabelledRagDataExample,它包含以下属性
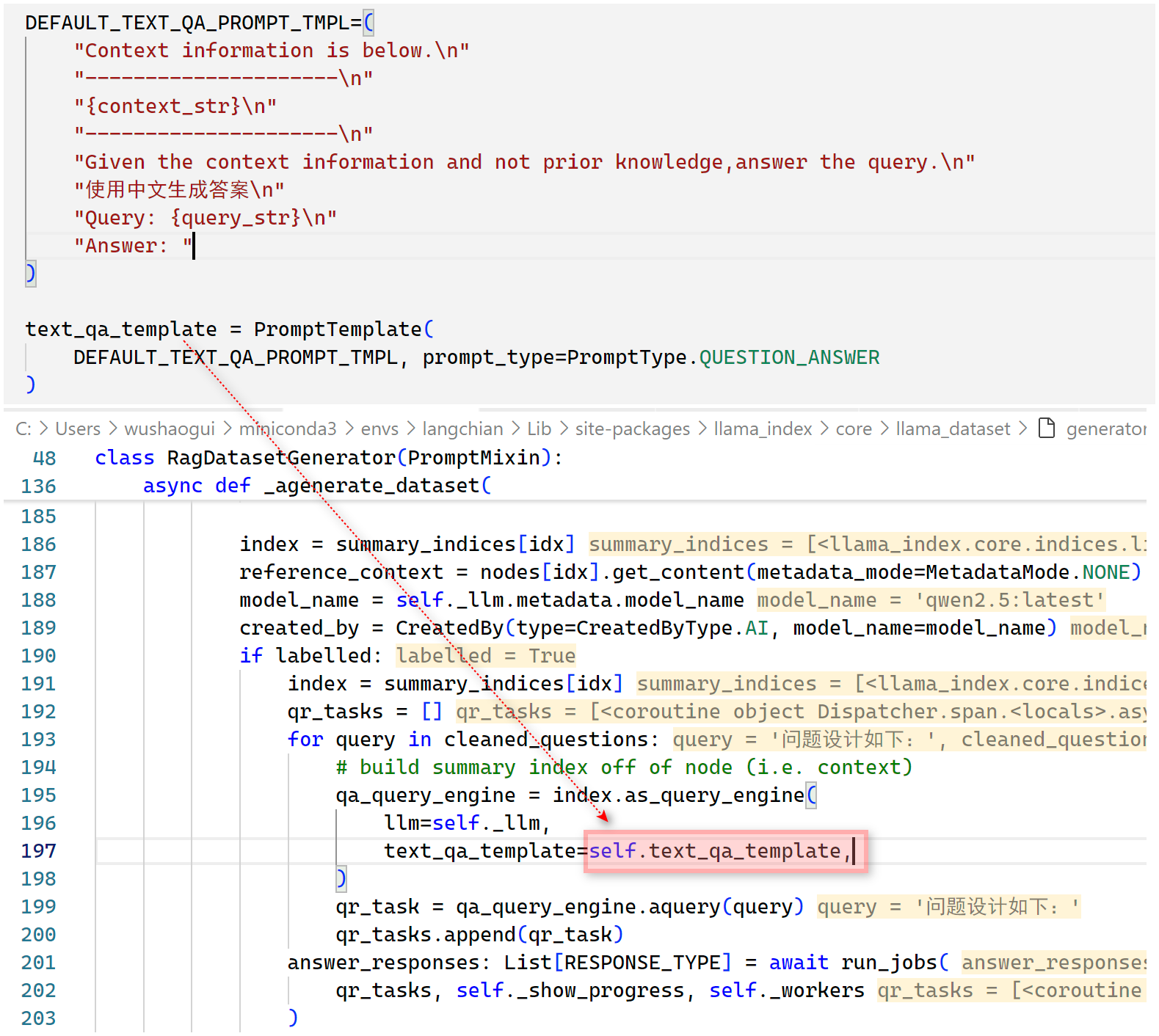
classDiagram
LabelledRagDataExample <|-- RagExamplePrediction
class LabelledRagDataExample {
+ query
+ query_by
+ reference_contexts
+ reference_answer
+ reference_answer_by
}
class RagExamplePrediction {
+ response
+ contexts
}1 | from llama_index.core import SimpleDirectoryReader |
然后运行批量评估,一次性评估批量样本的多个指标
1 | from llama_index.core.evaluation import BatchEvalRunner |