检索过程非常依赖用户输入,在使用 “用户提问” 按照索引的方式去检索文档时,需要对 “用户提问” 先加工,主要包括重写和扩展等,以便提高检索的准确性
就用户的提问来说,其主要存在以下问题:
语序紊乱,错别字:如 “天明天气怎么样、小明在打秋” 等 多重语义:如 “我失去了她,就像钥匙丢了” 语义缺失:如 “我明天公园” 直接使用这种提问去检索,得到的结果不准确,在此我们使用 llm 这些输入先处理,处理的方式有两种:
重写 :使用 llm 重构用户提问扩展 :使用 llm 扩展用户提问转换 :使用 llm 将用户提问转换为另一种表示方式,如数据库的查询代码由于提问中经常涉及:文字语序错乱、同义词替换等问题,直接去向量数据库检索,提取的内容有问题,因此在正式检索前,先使用 llm 优化问题
用户提问给于的信息太少,使用 llm 适当扩展用户提问,提高检索准确度
扩大原始查询范围包含相关术语、同义词或替代短语,可以增加检索更全面信息的机会
注意:对原始 prompt 进行扩展,确保多样性和覆盖性,但是可能偏离初衷,此时需要原始 prompt 更大的权重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 vectordb_path = "Vector_db" embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2" ) vectordb = Chroma(persist_directory=vectordb_path, embedding_function=embeddings) vectorstore_retriever = vectordb.as_retriever(search_kwargs={"k" : 1 }) llm = ChatOpenAI(temperature=0 ) retriever_from_llm = MultiQueryRetriever.from_llm( retriever=vectordb.as_retriever(), llm=llm) question = "How to store the data into VectorDB?" unique_docs = retriever_from_llm.invoke(question) len (unique_docs) ['What are the best practices for indexing and storing data in a vector database?' , , 'How can I optimize my data storage for efficient querying in a vector-based database?' , 'What are the key considerations for designing a scalable and efficient data storage system using vector databases?' ]
通过分解和规划复杂产生多个子问题。明确地,可以采用最少到最多提示 LtM 将复杂问题分解为一系列更简单的子问题。根据原始问题的结构,生成的子问题可以并行执行,或者依次。
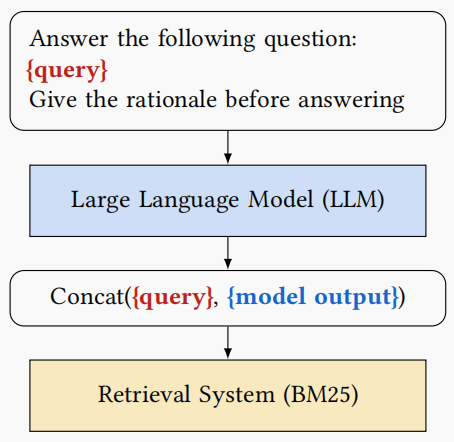
首先使用 llm 尝试回答问题,然后将提问 + llm 回答一起输入检索步骤
由于待检索的数据不一定是非结构化数据的,对于结构化的数据,如表格、图片、数据库、知识图谱等无法被 Query 检索到,这时候有必要将 Query 转换为另一种能解析这些数据的形式,如将 Query 转为 SQL 查询语句
在准备检索 excle 表格数据时,通过 llm 生成 pandas 检索命令,也就是将用户提问转换为 pandas 命令
1 2 3 4 5 6 7 8 9 10 11 system_string="你正在使用pandas处理DataFrame,请根据三个引号分隔的问题输出pandas命令,其中`print(df.head())`的结果如下:\n" system_string+="{excle_head}\n" system_string+= "请使用1行代码完成需求,目的是通过pandas检索出符合条件的行(包括所有列)\n" system_string+= "只输出代码,不要输出其他任何信息,也不能写任何注释\n" system_string+= "确保代码可运行\n" pandas_prompt = ChatPromptTemplate.from_messages([("system" , system_string), ("human" , "'''{question}'''" )]) pandas_chain = {'excle_path' :RunnablePassthrough(), 'question' :RunnablePassthrough()}|{'excle_head' :read_excle, 'question' :RunnablePassthrough()}|pandas_prompt | \ llm | StrOutputParser() | _sanitize_output | \ run_python|postprocess
市面上有个更加专业的库 PandasAI,除了查询之外,PandasAI 还提供通过图表可视化数据、通过解决缺失值来清理数据集以及通过特征生成提高数据质量的功能
当待检索的信息存储在数据库中时,原始 query 无法准确提取出相关片段,需要将 query 转为 sql 查询代码,才可以进行后续检索
当知识被存在在 “知识图谱” 时,原始 query 无法直接检索知识,必须转换为 “知识图谱” 能够理解的语言