语言模型学习路线
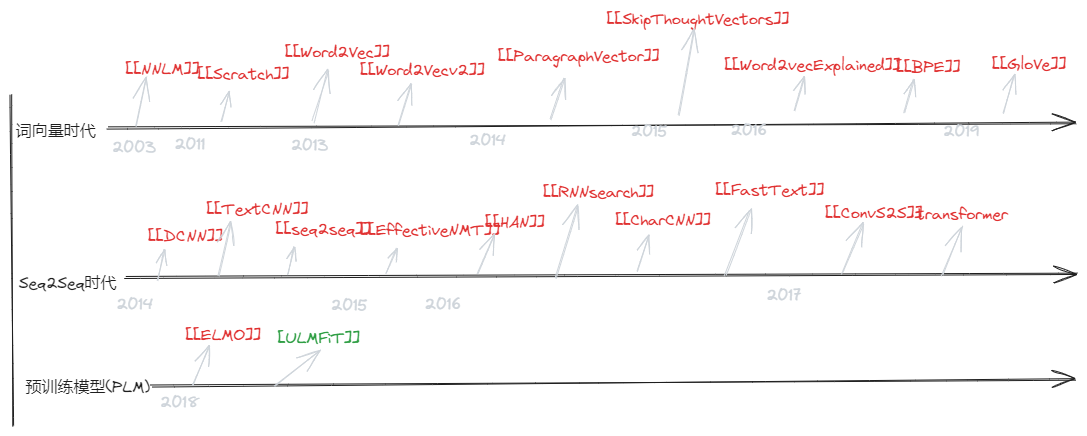
我的语言模型学习路线
什么是自然语言处理 (NLP)?
- 自然语言处理(Natural Language Processing,简称 NLP)主要研究人与计算机之间,使用自然语言进行有效通信的各种理论和方法。
- 简单来说,计算机以用户的自然语言数据作为输入,在其内部通过定义的算法进行加工、计算等系列操作后(用以模拟人类对自然语言的理解),再返回用户所期望的结果
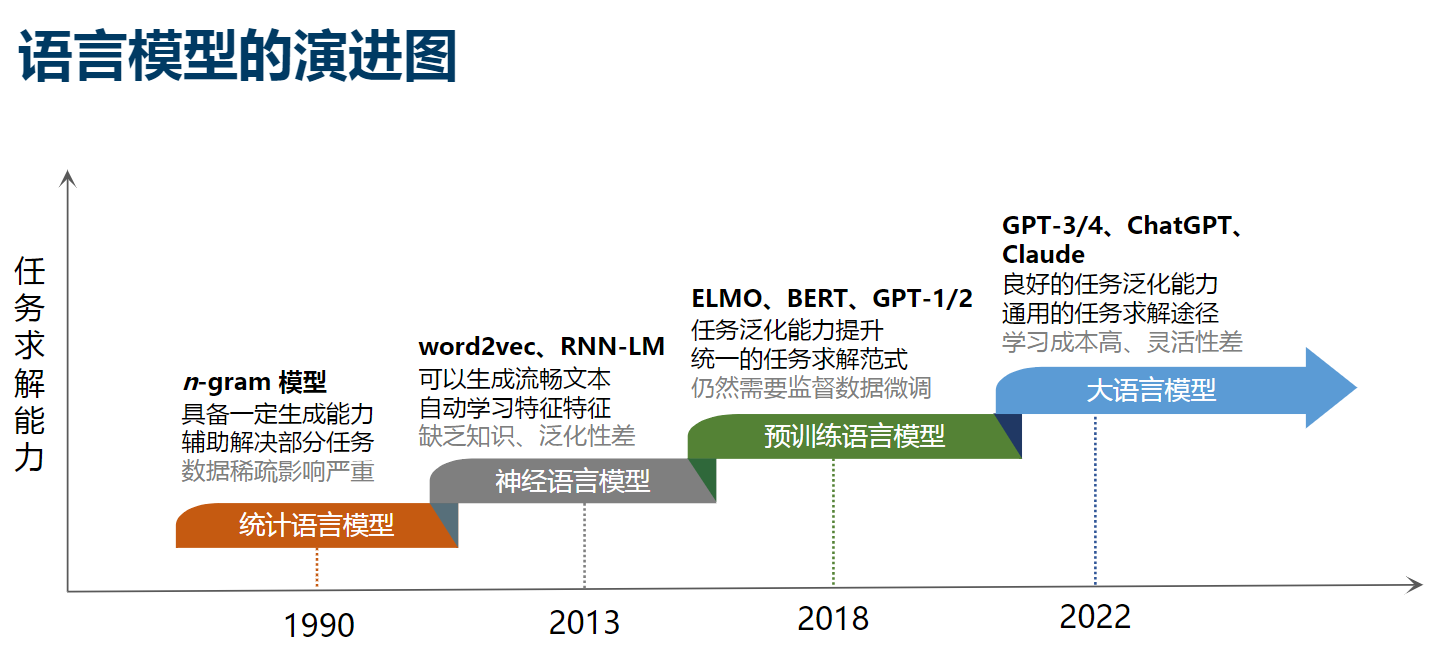
自然语言处理 (NLP) 的发展阶段?
![语言模型学习路线-20250112163032]()
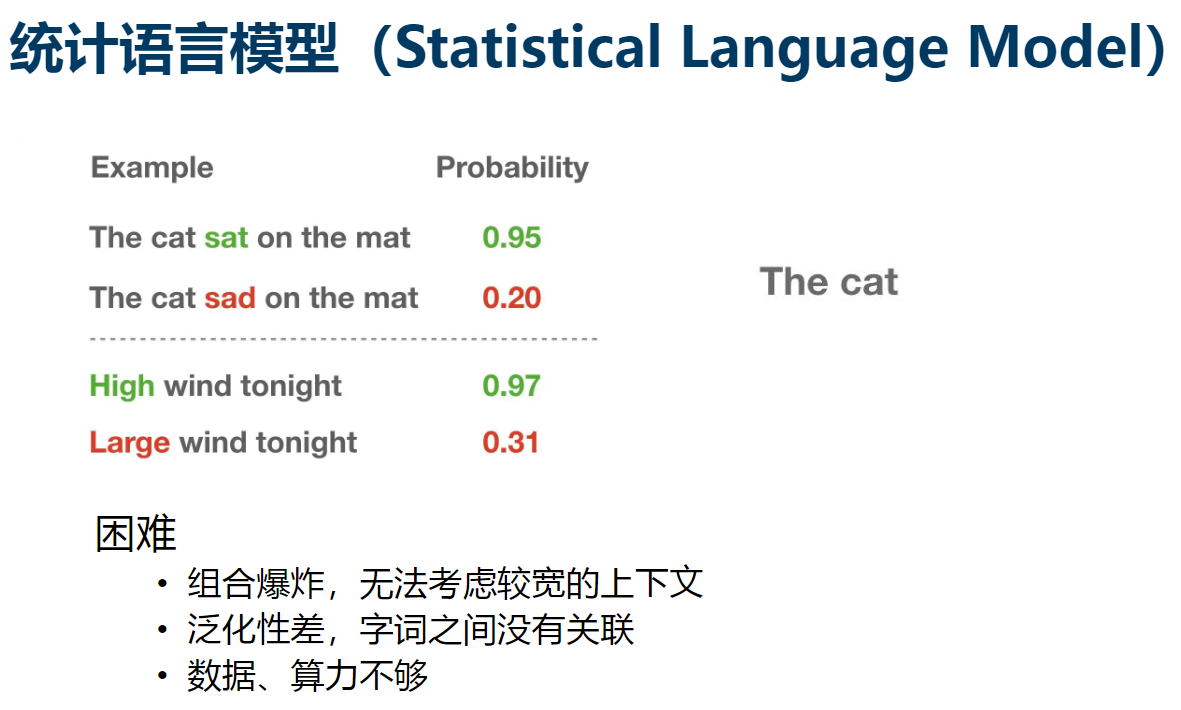
- 统计语言模型 (SLM):最早的语言模型,主要基于统计理论。例如,N-Gram 模型就是一种统计语言模型,它通过计算词序列在语料库中出现的频率来预测下一个词。但是,这种模型的缺点是无法处理语料库中未出现的词序列,也无法捕获长距离的词依赖关系
1
2
3# 一个简单的Bigram模型
corpus = ["我 爱 北京 天安门", "北京 欢迎 你", "我 爱 你"]
model = train_bigram_model(corpus) - 神经语言模型 (NLM):为了解决 SLM 的问题,研究者开始使用神经网络来建立语言模型。例如,NNLM、Word2vecExplained、GloVe 和 FastText 等模型可以将词映射到高维空间,使得语义相近的词在空间中的距离也相近。此外,RNN、LSTM 和 GRU 等模型可以处理任意长度的词序列,捕获长距离的词依赖关系,如:seq2seq、FastText、TextCNN、transformer。NLM 的一个主要缺点是它们通常需要从头开始训练,这需要大量的计算资源和时间
1
2
3
4
5
6# 一个简单的RNN模型
from keras.models import Sequential
from keras.layers import Embedding, SimpleRNN
model = Sequential()
model.add(Embedding(10000, 32))
model.add(SimpleRNN(32)) - 预训练语言模型 (PLM):先在大规模语料库上进行预训练,学习词的表示和语言的规律,然后再进行微调,适应特定的任务。例如 ELMO,BERT、GPT 、 RoBERTa 等模型都是预训练语言模型。这种模型的优点是可以利用无监督的大规模语料库,学习更丰富的语言知识
1
2
3
4# 使用BERT模型
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained("bert-base-uncased") - 大语言模型 (LLM):这是最新的发展趋势,通过使用更大的模型和更多的数据,可以学习更复杂的语言规律和知识。例如,GPT-3 和 GPT-4 等模型就是大语言模型。这种模型的优点是可以生成更自然、更准确的文本,但是需要更多的计算资源
1
2
3# 使用GPT-3模型
from openai import GPT3
model = GPT3(api_key="your-api-key")
什么是 N-gram 模型?
![语言模型学习路线-20250112162746]()
- N-Gram 是一种基于统计语言模型的算法,其基本思想是按照长度为 N 的文本字节进行窗口滑动,每个文本字节片段称为 gram,对 gram 内出现的频度进行统计,得到一个关于文本的 gram 列表
- N-Gram 模型假设第 i 个词只与前面 i-1 个词有关,所以如果使用 N-Gram 模型判断一句话是否合理,其做法如下:现有 m 个词组的序列,希望计算概率 ,根据链式规则,可
p (w_1,w_2,\ldots,w_m)=p (w_1)*p (w_2|w_1)*p (w_3|w_1,w_2)......p (w_m|w_1,\ldots,w_{m-1})$$,这个概率并不好算,于是 ** 进步增加约束 **,第 i 个词只与前面 n 个词相关,则上面概率公式变 $$p (w_1,w_2,\ldots,w_m)=p (w_i|w_{i-n+1,\ldots,w_{i-1}})
- 简化地,当 n=1、2、3 时,分别是一元模型(unigram model)、二元模型(bigram model)、三元模型(trigram model),其概率计算公式如
- 至于右边每个条件概率的求取,利用前面统计的频数和贝叶斯定理即可,对于二元模型(bigram model) 而言,其条件概率计算
P (w_i|w_{i-1})=\frac {C (w_{i-1} w_i)}{C (w_{i-1})}$$,对于 N-Gram 模型而言,其条件概率计算为:$$P (w_i|w_{i-n-1},\cdots,w_{i-1})=\frac {C (w_{i-n-1},\cdots,w_i)}{C (w_{i-n-1},\cdots,w_{i-1})}
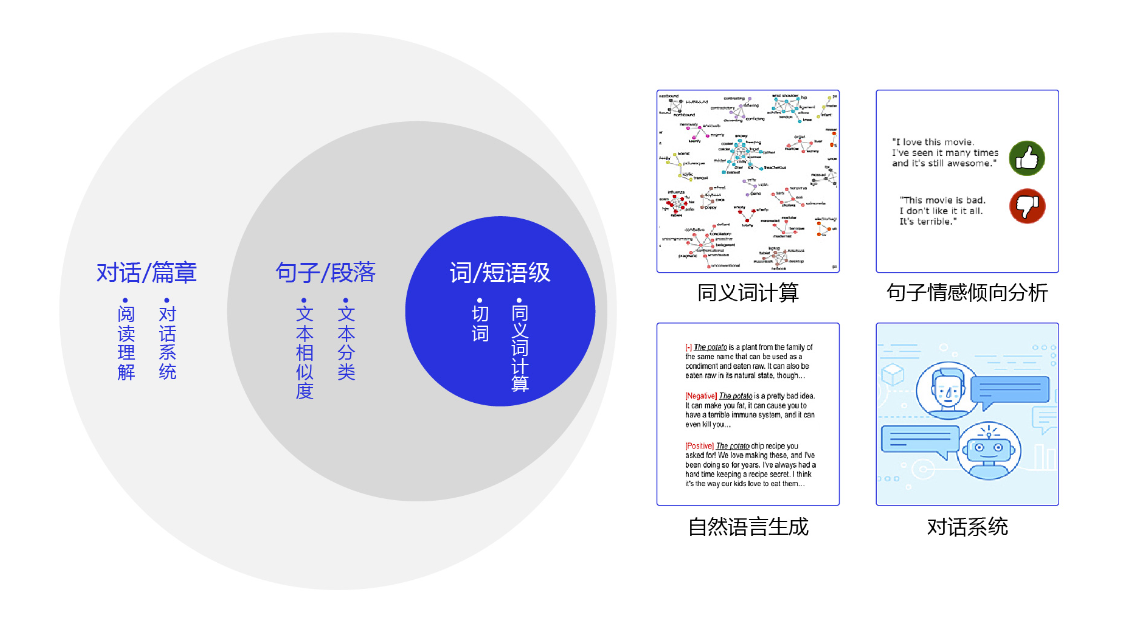
NLP 常见的任务?
![]()
- 词和短语级任务:包括切词、词性标注、命名实体识别(如 “苹果很好吃” 和 “苹果很伟大” 中的 “苹果”,哪个是苹果公司?)、同义词计算(如 “好吃” 的同义词是什么?)等以词为研究对象的任务
- 句子和段落级任务:包括文本倾向性分析(如客户说:“你们公司的产品真好用!” 是在夸赞还是在讽刺?)、文本相似度计算(如 “我坐高铁去广州” 和 “我坐火车去广州” 是一个意思吗?)等以句子为研究对象的任务
- 对话和篇章级任务:包括机器阅读理解(如使用医药说明书回答患者的咨询问题)、对话系统(如打造一个 24 小时在线的 AI 话务员)等复杂的自然语言处理系统等
- 自然语言生成:如机器翻译(如 “我爱飞桨” 的英文是什么?)、机器写作(以 AI 为题目写一首诗)等自然语言生成任务
NLP 的 Tokenizer?
- Tokenizer 的过程是构建词表的过程,其实就是分词的过程,GPT 族使用 Byte-Pair Encoding (BPE) 作为分词手段,BERT 族则使用 Word-Piece 算法
- Tokenizer encode:根据词表,从 string 映射到 id
- Tokenizer decode:根据词表,从 id 映射回 string
NLP 的词表 (vocabulary)?
- 在神经机器翻译中,通常有一个固定的词表,并且模型的训练和预测都非常依赖这个词表。在神经网络的训练过程中,需要对词表中每个词做向量表,每个词对应不同的向量,即 embedding 的过程。词表 (vocabulary) 发展过程中经历 word->character->subword 的过程
- word 级别词表:经典的词向量,但是存在稀疏 (某些词汇出现的频率很低) 和计算量 (词典越大意味着 embedding 过程的计算量会变大) 问题。并且不能通过增大词表真正解决 OOV 的问题,因为再大的词典不能真正覆盖所有的词汇
- Character 级别词库:使用 26 个字母加上一些符号去表示所有的词汇,相比于 word-level 模型,这种处理方式的粒度变小,其输入长度变长,基于字符的模型能更好处理 OOV 问题,并且能更好学习多语言之间通用的语素,但是数据更加稀疏并且难以学习长远程的依赖关系
- subword 级别词表:word-level 模型导致严重的 OOV,而 character-level 模型粒度又太小,那么 subword-level 的处理方式就应运而生。subword 将单词划分为更小的单元,比如 "older" 划分为 "old" 和 “er”,而这些单元往往能应用到别的词汇当中
- 如果一个词语不在词表中,那么是无法生成的对应的词语,这样的问题是 Out-Of-Vocabulary(OOV)。如果词表是 character,虽然可以表示所有的单词,但是效果不好,而且由于粒度太小,难以训练。基于此,提出了一个折中方案,选取粒度小于单词,大于 character 的词表,BPE 因此而产生
求解 subword 级别词表的 3 种算法?
- Byte Pair Encoding:Byte Pair Encoding (BPE) 是一种压缩算法,它属于自下而上的算法,它将字符串中最常见的一对连续字符数据替换成该字符串中不存在的字符串,后续再通过一个词表重建原始的数据
- wordpiece:都是用合并 token 的方式来生成新的 token,最大的区别在于选择合并哪两个 token。BPE 选择频率最高的相邻字符对进行合并,而 wordpiece 是基于概率生成的。
- unigram language model:在 wordpiece 算法中,在选择 token 进行合并的时候目标就是能提高句子的 likelihood。Unigram 分词则更进一步,直接以最大化句子的 likelihood 为目标来直接构建整个词表
什么是词嵌入 (Word Embedding)?
![]()
- 原始的文本是非结构化的数据,不可计算,词嵌入的目地是将离散的文本信息向量化,并使得向量化后仍然能反映实际文本的关系
- 词向量从发展历史来看,依次经历:统计 (One-hot、Count Vector、TF-IDF Vector)-> 网络学习(Word 2 Vec)-> 共现矩阵(GloVe)-> 动态嵌入(ELMO)-> 共同训练 (直接将 embedding 层和语言模型层共同训练得到)

| 类型 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| One-hot | 根据词汇表进行 one-hot 化,假设词汇表大小是 N,则是一个长度为 N 的 one-hot 编码 | 简单,无需学习 | 任何一段文本都是一个稀疏向量表示,浪费空间,任何词的嵌入都是正交的,体现不了任何关系 |
| Count Vector | 根据文档数量 D 和词汇量 N 构成一个矩阵 DxN,词嵌入长度是 D | - | 如果预料库很大时,矩阵必然是稀疏的 |
| TF-IDF Vector | 解决 Count Vector 只统计词频的问题,像 is,a,the 等通用词汇,几乎在每个文档里出现的频率都很高,因此考虑逆文本概率,通过词频 * 逆文本概率得到词汇权重,加权 Count Vector 即可 | 考虑了语言的规律 | 词嵌入矩阵还是非常稀疏 |
| Word 2 Vec | 通过两个模型学习词嵌入 | 神经网络学习出来的向量可以作类似:v (国王)-v (男) + v (女)=v (王后) 的表示,说明向量具有词义信息 | 只考虑文本局部 (窗口) 内的文本,忽略了全局文本的信息 |
| GloVe | 通过构建词之间的两两共现矩阵,然后使用神经网络拟合 | 基于全局信息构建词嵌入,得到的词嵌入比 Word 2 Vec 更有效 | 增加词汇,比较麻烦 |
| ELMO | 通过双层双向的 RNN 提取文本词汇、语义级别的信息 | 词向量根据所处不同上下文具有不同的值 | 双向 LSTM 对语言模型建模不如注意力模型,训练速度较慢 |
| BERT | ELMO 的升级版,主要改进是使用 transformer | 注意力更准确,训练更快 | - |
词嵌入的使用步骤?
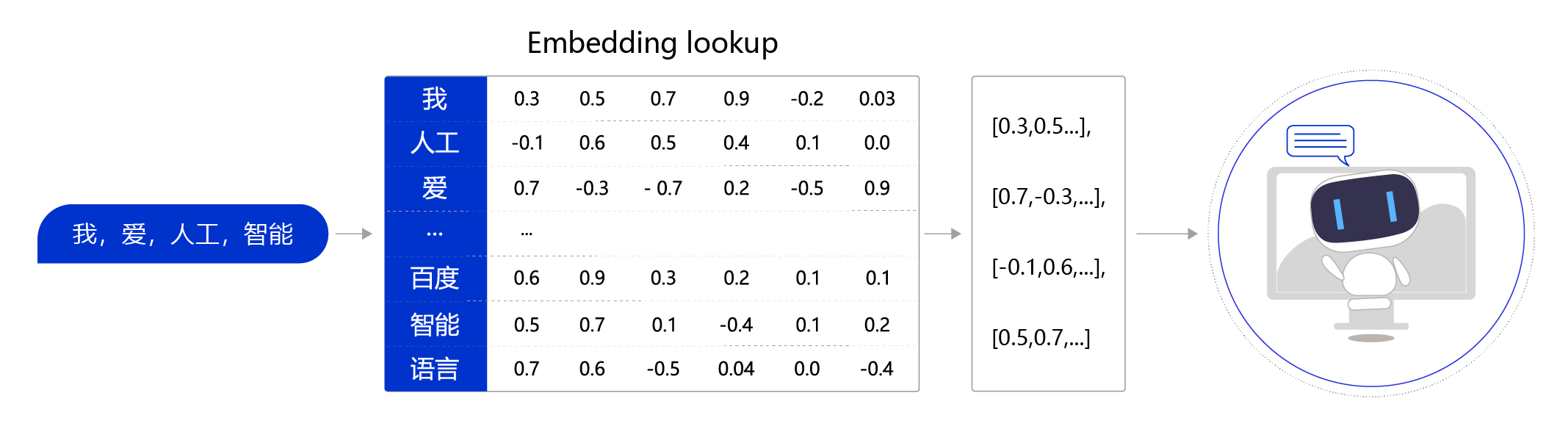
- 查询表 (Embedding Lookup):自然语言单词是离散信号,比如:“我”、“ 爱”、“人工智能”。如何把每个离散的单词转换为一个向量?通常情况下,我们可以维护一个的查询表。表中每一行都存储了一个特定词语的向量值,每一列的第一个元素都代表着这个词本身,以便于我们进行词和向量的映射。给定任何一个或者一组单词,我们都可以通过查询这个 excel,实现把单词转换为向量的目的,这个查询和替换过程称之为 Embedding Lookup
![]()
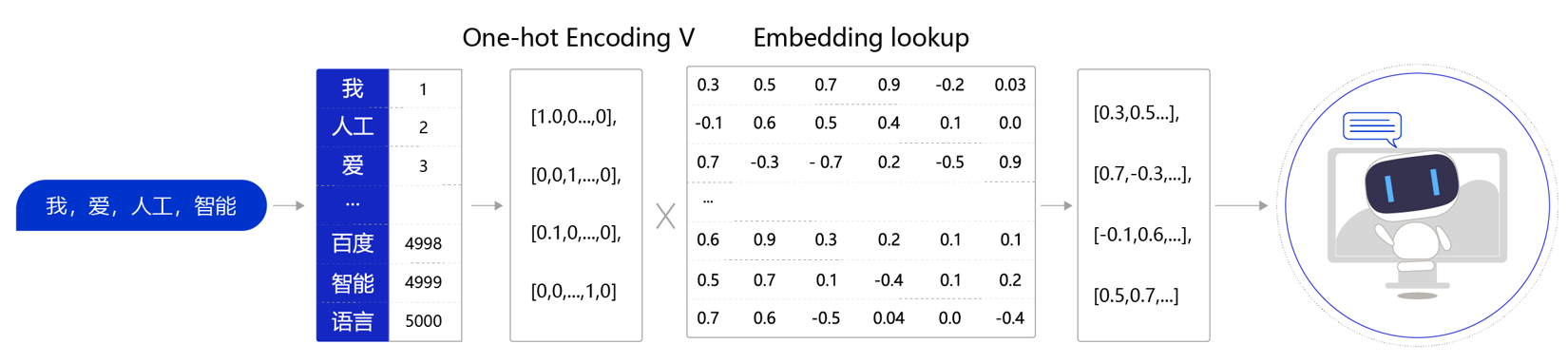
- 优化速度:上述过程也可以使用一个字典数据结构实现,然而在进行神经网络计算的过程中,需要大量的算力,常常要借助特定硬件满足训练速度的需求。GPU 上所支持的计算都是以张量(Tensor)为单位展开的,因此在实际场景中,我们需要把 Embedding Lookup 的过程转换为张量计算
![]()
- 计算词嵌入过程:1) 构建字典,存储单词和 ID 之间的关系;2)得到 ID 后将其转为 one-hot 变量;3)one-hot 变量乘上 Embedding Lookup 得到单词的词嵌入
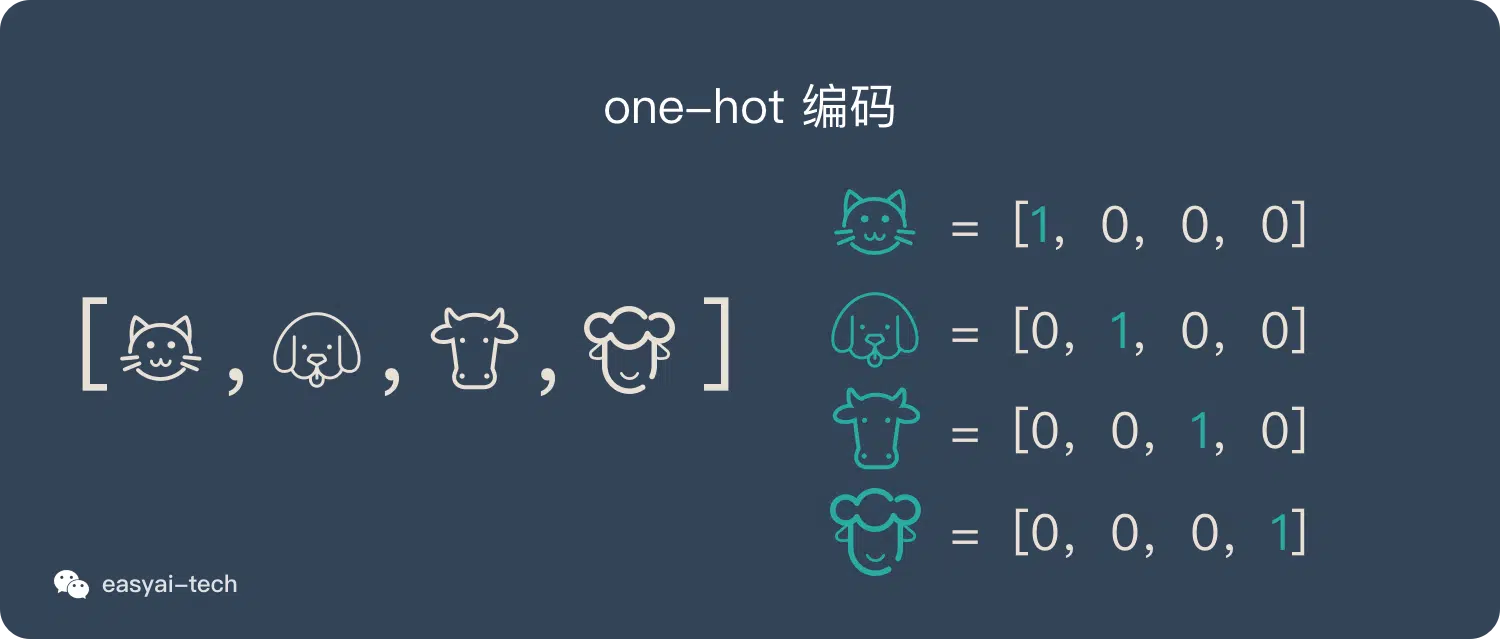
基于频率的词嵌入方式 -One-hot?
![]()
- One-hot 简称读热向量编码,也是特征工程中最常用的方法
- 这种表示方式比较稀疏,而且这种表示方式因为向量与向量之间是正交的,即任何两个不同词的 one-hot 向量的余弦相似度都为 0,多个不同词之间的相似度难以通过 one-hot 向量准确地体现出来
基于频率的词嵌入方式 -Count Vector?
![]()
- 上图是:两份文档的词嵌入方式,分别是
D1: He is a boy.、D2: She is a girl, good girl.,得到矩阵后每个文档用词向量的组合来表示,每个词的权重用其出现的次数来表示 - 假设有一个语料库 C,其中有 D 个文档:{d1, d2, …, dD},C 中一共有 N 个 Word。这 N 个 Word 构成了原始输入的 Dictionary,我们据此可以生成一个矩阵 M,其规模是 D X N(每一行代表一篇文档,每一列代表一个单词)
- 如果语料库十分庞大,那么 Dictionary 的规模亦会十分庞大,因此上述矩阵必然是稀疏的,会给后续运算带来很大的麻烦。通常的做法是选取出现次数最频繁的那些词来构建 Dictionary

基于频率的词嵌入方式 -TF-IDF Vector?
- Count Vector 在构建词的权重时,只考虑了词频 TF(Term Frequncy),也就是词在单个文档中出现的频率。直觉上来看,TF 越大,说明词在本文档中的重要性越高,对应的权重也就越高。这个思路大体上来说是对的
- 但如果我们把视野扩展到整个语料库,会发现,像 is,a,the 等通用词汇,几乎在每个文档里出现的频率都很高。由此,我们可以得到这样的结论:对于一个 word,如果在特定文档里出现的频率高,而在整个语料库里出现的频率低,那么这个 word 对于该文档的重要性就比较高。该 word 就可以作为这篇文档的主题词。因此我们可以引入逆文档频率 IDF。IDF 用于惩罚那些常用词汇,而 TF 用于奖励那些在特定文档中出现频繁的词汇。二者的乘积 TF X IDF 用来表示词汇的权重,显然合理性大大增强
基于 word 2 Vec 的词嵌入方式?
![]()
- 词的表示中如果蕴含了上下文信息,那么将会更加接近自然语言的本质,需要找到一种更好的表示方法,这种方法需要满足如下两点要求:(1) 携带上下文信息 ;(2) 词的表示是稠密的。
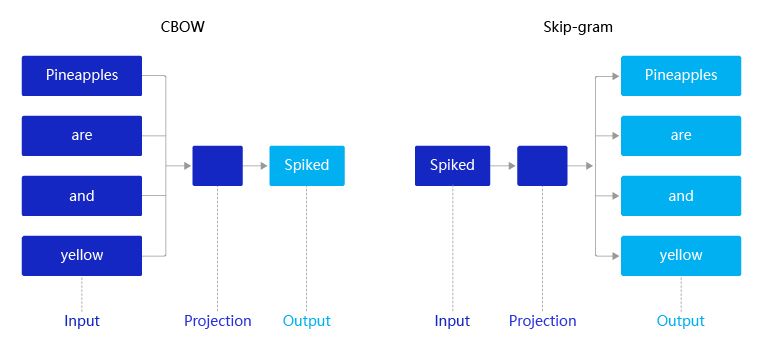
- 事实证明,通过神经网络来进行建模,可以满足这两点要求。这就是 Word 2 Vec 的思想。而 Word 2 Vec 又有两种:CBOW 和 Skip-Gram
- 一般来说,CBOW 比 Skip-gram 训练速度快,训练过程更加稳定,原因是 CBOW 使用上下文 average 的方式进行训练,每个训练 step 会见到更多样本。而在生僻字(出现频率低的字)处理上,skip-gram 比 CBOW 效果更好,原因是 skip-gram 不会刻意回避生僻字 (CBOW 结构中输入中存在生僻字时,生僻字会被其它非生僻字的权重冲淡)
基于频率的词嵌入方式 -Co-Occurence Vector*?
![]()
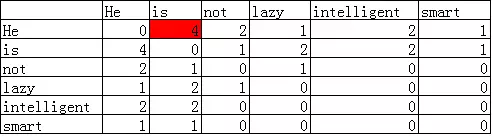
- 共现特征向量,假设有如下语料库:
He is not lazy. He is intelligent. He is smart.,如果 Context Window 大小为 2,那么可以得到如上的共现矩阵 - 共现矩阵最大的优势是这种表示方法保留了语义信息,例如,通过这种表示,就可以知道,man 和 woman 是更加接近的,而 man 和 apple 是相对远的。相比前述的两种方法,更具有智能的味道
Pytorch 的 Embedding 层与词表的关系?
- Embedding 层初始化时使用的是
torch.nn.Embedding(m, n),其中 m 表示词数量,n 表示嵌入的维度,也是一个词嵌入句子。训练时,这个层也会被更新学习,训练完成后,得到的就是词向量。这个层也可以被外部已经训练好的词向量初始化 - torch.nn.Embedding 输入输出:输入是任意维度,输出取最后维度取索引词向量矩阵 (n, h) 得到输出,最终 (*)->(*, h)
- torch.nn.Embedding 训练:该层可被训练,训练过程是修改词向量矩阵 (n, h) 的过程
1
2
3
4
5
6
7
8import torch
from torch import nn
from torch.autograd import Variable
# 初始化词嵌入
embeds = nn.Embedding(2, 5) # 2 个单词,维度 5
# 加载已有词向量
pretrained_weight = np.array(args.pretrained_weight) # 已有词向量的numpy
self.embed.weight.data.copy_(torch.from_numpy(pretrained_weight))
什么是 N-gram 的匹配规则?
![image-20231207102928434]()
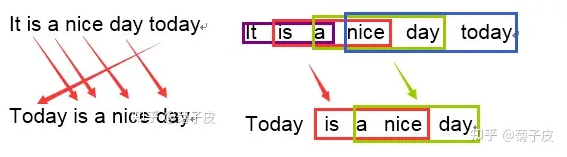
- 就是比较译文和参考译文之间 n 组词的相似的一个占比
- 如果用 1-gram 匹配,机器译文一共 6 个词,有 5 个词语都命中的了参考译文,那么它 1-gram 的匹配度为 5/6
- 如果是 3-gram 匹配,机器译文一共可以分为四个 3-gram 的词组,其中有两个可以命中参考译文,那么它 3-gram 的匹配度为 2/4
- 一般来说 1-gram 的结果代表了文中有多少个词被单独翻译出来了,因此它反映的是这篇译文的忠实度;而计算 2-gram 以上时,更多时候结果反映的是译文的流畅度,值越高文章的可读性就越好。
语言翻译衡量指标 BLEU?
- 用于评估 **「模型生成的句子 (candidate)「和」实际句子 (reference)「的差异的指标。它的取值范围在 0.0 到 1.0 之间,如果两个句子」完美匹配 (perfect match)」, 那么 BLEU 是 1.0, 反之,如果两个句子「完美不匹配 (perfect mismatch)」**, 那么 BLEU 为 0.0
- BLEU 方法的实现是分别计算 **「candidate 句」和「reference 句」的「N-gram 模型」**, 然后统计其匹配的个数来计算得到
- BP 计算:N-gram 的匹配度可能会随着句子长度的变短而变好,因此会存在这样一个问题:一个翻译引擎只翻译出了句子中部分结果且翻译的比较准确,那么它的匹配度依然会很高。为了避免这种评分的偏向性,BLEU 在最后的评分结果中引入了长度惩罚因子 (Brevity Penalty),其中 r 是一个参考翻译的词数,c 是一个候选翻译的词数,BP 代表译句较短惩罚
- 召回率计算:在计算 1-gram 的时候,the 都出现在译文中,因此匹配度为 4/4 ,但是很明显 the 在人工译文中最多出现的次数只有 2 次。BLEU 算法考虑到了这个问题,首先会计算该 n-gram 在译文中可能出现的最大次数,其中 Count 是 N-gram 在机器翻译译文中的出现次数,Max_Ref_Count 是该 N-gram 在一个参考译文中最大的出现次数,修正后的 1-gram 的统计结果就是 2/
Count_{clicp}=min(Count,Max\_Ref\_Count)$$
1 | 原文:猫站在地上 |
语言模型的评价标准困惑度 (Perplexity, PPL)?
![]()
- 直观上理解,当我们给定一段非常标准的,高质量的,符合人类自然语言习惯的文档作为测试集时,模型生成这段文本的概率越高,就认为模型的困惑度越小,模型也就越好,其中 W 表示测试预料,P (w) 表示模型输出概

- 1)假设现有以下词表
1
2
3
4
5
6
7
8
9tokens_map = {
'爱': 0,
'你': 1,
'就': 2,
'像': 3,
'生': 4,
'命': 5,
'。': 6,
} - 2)现在我们有两个语言模型 A 和 B,一般情况下,使用 GPT 类模型生成上面这句话的时候,我们会拿到形状为 [句子长度,词表长度] 的概率矩阵
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# modelA
probs_modelA = [
[0.16, 0.16, 0.16, 0.16, 0.16, 0.16, 0.04],
[0.05, 0.30, 0.05, 0.40, 0.05, 0.10, 0.05],
[0.30, 0.05, 0.30, 0.20, 0.05, 0.05, 0.05],
[0.20, 0.10, 0.05, 0.50, 0.05, 0.05, 0.05],
[0.30, 0.30, 0.05, 0.05, 0.10, 0.15, 0.05],
[0.05, 0.05, 0.05, 0.15, 0.35, 0.30, 0.05],
[0.05, 0.05, 0.05, 0.15, 0.05, 0.60, 0.05],
[0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.70]
]
# modelB
probs_modelB = [
[0.16, 0.16, 0.16, 0.16, 0.16, 0.16, 0.04],
[0.05, 0.50, 0.05, 0.20, 0.05, 0.10, 0.05],
[0.30, 0.05, 0.40, 0.10, 0.05, 0.05, 0.05],
[0.10, 0.10, 0.05, 0.60, 0.05, 0.05, 0.05],
[0.40, 0.30, 0.05, 0.05, 0.10, 0.05, 0.05],
[0.05, 0.05, 0.05, 0.15, 0.40, 0.25, 0.05],
[0.05, 0.05, 0.05, 0.15, 0.05, 0.60, 0.05],
[0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.70]
] - 3)如果测试文档是
爱你就像爱生命。,应该如何计算 PPL,对模型 A,我们得到概率序列 [0.16, 0.30, 0.30, 0.50, 0.30, 0.35, 0.60, 0.70] ,同理对模型 B,我们得到概率序列 [0.16, 0.50, 0.40, 0.60, 0.40, 0.40, 0.60, 0.70],可以看到 ,这说明模型 B 生成这句话的概率更高,也就是模型 B 更容易输出测试句
参考:
- Word Embedding(词嵌入) - 知乎
- 【NLP-01】词嵌入的发展过程 (Word Embedding) - 忆凡人生 - 博客园
- pytorch 中的 embedding 词向量的使用方法_nn.embedding 中文词向量导入_hachyli 的博客 - CSDN 博客
- 飞桨 PaddlePaddle - 源于产业实践的开源深度学习平台
- 飞桨 PaddlePaddle - 源于产业实践的开源深度学习平台
- NLP 中的 subword 算法及实现 - 知乎
- BPE 详解 - 知乎
- 从词到数:Tokenizer 与 Embedding 串讲 - 知乎
- 自然语言处理中 N-Gram 模型介绍 - 知乎
- LLM 评估指标困惑度的理解 - 知乎