OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks
OverFeat 是 CNN 用来进行目标检测的早期工作,主要思想是采用多尺度滑动窗口来做分类、定位和检测,虽然是多个任务,但重用了模型前面几层,这种模型重用的思路也是后来 R-CNN 系列不断沿用和改进的经典做法
什么是 OverFeat ?
- OverFeat 早期经典的 one-stage Object Detection 的方法,基于 AlexNet,实现了识别、定位、检测共用同一个网络框架
- 主要创新点是: multiscale 、sliding window、offset pooling,以及基于 AlexNet 的识别、定位和检测方法的融合
OverFeat 的网络结构?
![]()
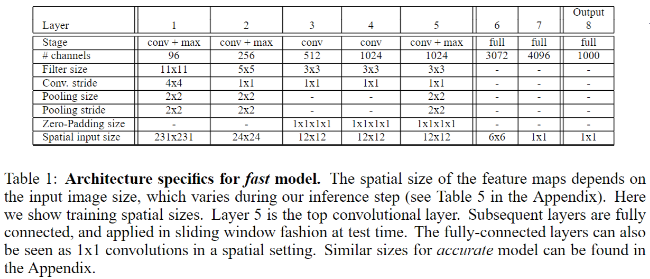
- 基本上和 AlexNet 一样,也使用了 ReLU 激活,最大池化。不同之处在于:(1) 没有使用 LRN;(2) 没有采用重叠池化(Overlapping Pooling) ;(3) 在第一层卷积层,stride 设置 2,AlexNet 选择的 stride 是 4
- 在训练阶段采用与 AlexNet 相同的训练方式,然而在测试阶段可是差别很大,overfeat 就是把采用 FCN 的思想把全连接层看成了卷积层,让我们在网络测试阶段可以输入任意大小的图片
OverFeat 如何使用多尺度 (multiscale )?
![]()
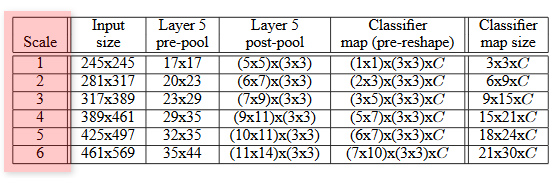
- 训练阶段:OverFeat 和 AlexNet 的思路一样,随机裁剪出 224x224 大小的图片,作为 CNN 的输入进行训练
- 测试阶段:OverFeat 没有采用 AlexNet 的 torchvision. transforms. TenCrop 方法,而是直接采用了六种不同尺度的测试图像输入(每个尺度的图像还增加了水平翻转),结合全卷积网络结构,最终输出的维度是不同的
OverFeat 如何使用滑动窗口 (sliding window)?
![]()
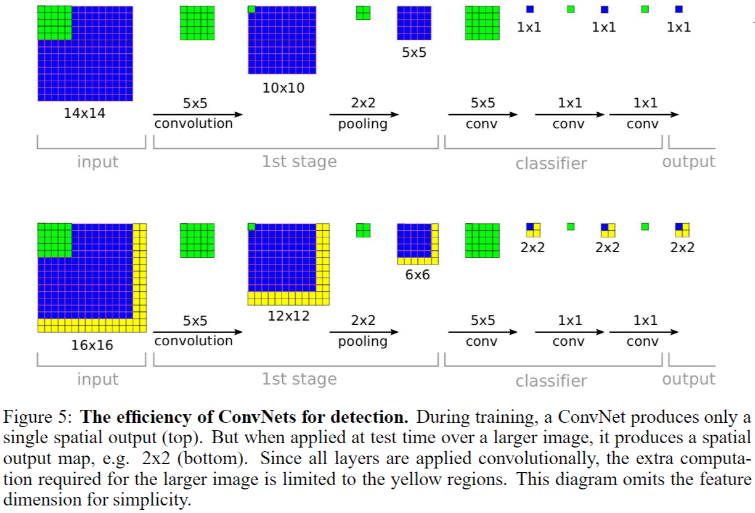
- 在此之前,很多滑动窗口技术都是为每个窗口重复进行所有的计算,这对计算资源的消耗是巨大的。而 OverFeat 通过将全连接层改造成卷积层的方式,使得相同区域的计算结果可以共享
- 图片尺寸是 16 x16 时,有 4 个滑动窗口需要进行重复计算。OverFeat 采用了卷积计算共享的方式,虽然计算结果是一个滑动窗口的 4 倍,但是计算过程只增加了图中黄色区域。在训练期间,ConvNet 仅生成单个空间输出(顶部)。但是当在测试时在较大的图像上应用时,它产生空间输出图,例如, 2 x2(下)。由于所有层都是卷积应用的,因此较大图像所需的额外计算仅限于黄色区域
OverFeat 如何使用偏差池化 (offset pooling )?
![]()
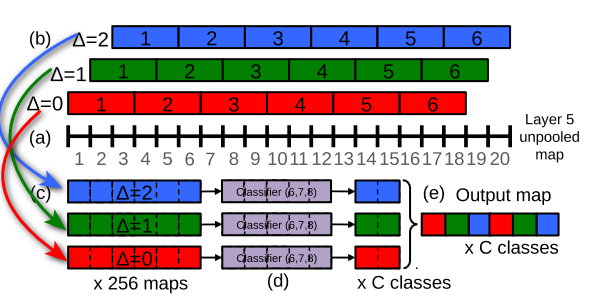
- 在特征提取最后一层(conv 5)直接做 max pooling,将导致最终输入图像的检测粒度不足,所以增加了 offset pooling 的操作
- 上图 (a) 表示 conv 5 后准备下采样的 20 个像素;(b)表示使用 non-overlapping 的 3 像素一组的最大下采样,得到 3 组结果,即二维图像得到 3 x 3 组;© 表示(b)的最大下采样结果,经过 5 x 5 卷积后,得到 2 x 2 的结果 (d);最后整合这三种 offeset 方式得到的每个类的预测结果
- 在实际的二维图像处理中,上述这个操作会对重复 6x2 也就是 12 次,其中 6 代表 6 个 scale
OverFeat 进行目标检测的步骤?
- (1)利用滑动窗口进行不同尺度的区域提名,然后利用 CNN 模型对每个区域进行分类,得到类别和置信度
![]()
- (2)利用多尺度滑动窗口来增加检测数量,提升分类效果
![]()
- (3)用回归模型预测每个对象的位置,放大比例较大的图片,边框数量也较多
![]()
- (4)边框合并
![]()



