seq2seq
使用 RNN 学习序列数据,分为编码器和解码器两部分,将编码器最后一个隐状态初始化解码器的初始隐状态,解决序列 -> 序列的学习任务,比如翻译,词性标注,命名实体识别等
什么是 seq2seq?
![img]()
- 一个端到端的方法(end-to-end) 用于处理序列到序列的任务。首先利用多层的 LSTM 将 input sequence 映射到一个固定维度的向量,使用另一个 LSTM 从这个向量解码出 target sequence
- sequence 指的是由多个单词构成的序列 / 句子。本文提出的模型能够处理长句子;能够学习对单词次序敏感且相对于主动、被动语态不敏感的单词和句子表示
- 模型按照原句子的逆序的顺序输入到模型能够提升模型的效果,因为引入了许多短期依赖关系
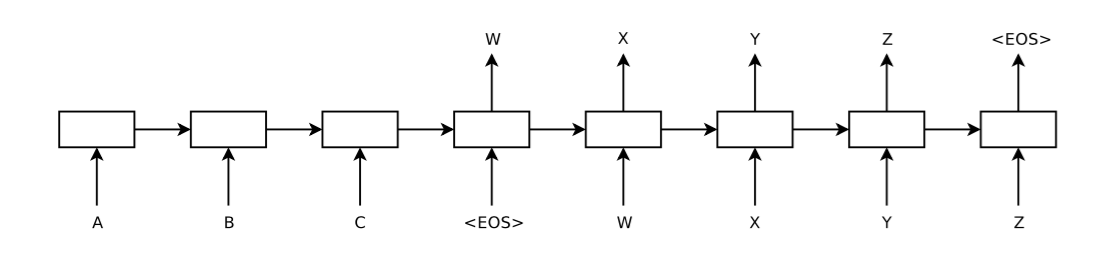
seq2seq 的结构?
- 编码器:首先使用一层 LSTM 读取 input sequence,以为一个句子的结束标志,获得大的固定维向量表示
- 解码器:然后使用另一个 LSTM 从该向量表示中解码得到输出序列
- LSTM 的一个有用的特性是,不受限于句子的长度,能够将不同长度的句子映射到一个固定维度的向量
seq2seq 的损失函数?
- 模型的目标是找到最大概率的 output sequenc
- 其中 (x1, . . . , xT) – input sequence;v – 由 input sequence 得到的 hidden state;(y1, . . . , yT′ ) – 相应于 input sequence,模型预测的 output sequence;T 与 T’不一定相等
- 其实就是每次输入,然后最大化目标字符的概率,交叉熵即可计算
Seq 2 seq 的训练?
- 论文使用了 4 层 LSTM 的 deep LSTMs (发现每添加一层,困惑度能减少解决 10%), 每层 1000 个节点 (cell) 和 1000 维的词嵌入;
- 输入使用了 160000 个使用频率最高的单词,输出使用了 80000 个频率最高的单词,所有不在这些词汇表中的单词都标记为 ‘UNK’;
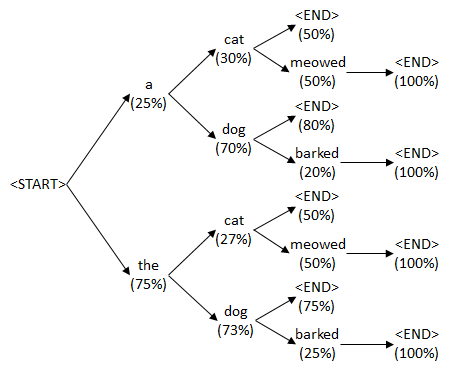
seq2seq 的 beam search decoder 方法?
![img]()
- 在 inference 阶段,不能使用 Teacher Forcing,那么只能使用上一时刻解码的输出作为下一个解码的输入,刚才也说过了这样会导致误差传递。beam search 在每个时刻解码器都会选择 Top k 个预测结果作为下一个解码器的输入,将这 K 个结果逐一输入到解码器进行解码,就会产生 k 倍个预测结果,从所有的解码结果中再选出 Top K 个预测结果作为下一个解码器的输入,在最后一个时刻再选出 Top 1 作为最终的输出,这样避免的错误传递
- 比如上面的例子,例子中 beam size 为 2,“EOS” 作为编码器最后一个输出后,解码已经解码的第一个词有两个候选项 a 和 the,然后将 a 和 the 输入到解码器中,得到一系列候选序列 a cat、a dog、the cat、the dog 等。最后从候选序列中选择最优的两个序列 the cat 和 the dog 再输入到解码器中,得到候选序列,选择最优的两个,直到遇到 "EOS" 结束。再从候选序列中找出最佳序列。在实际任务中,一般 beam size 在 8 到 12 之间
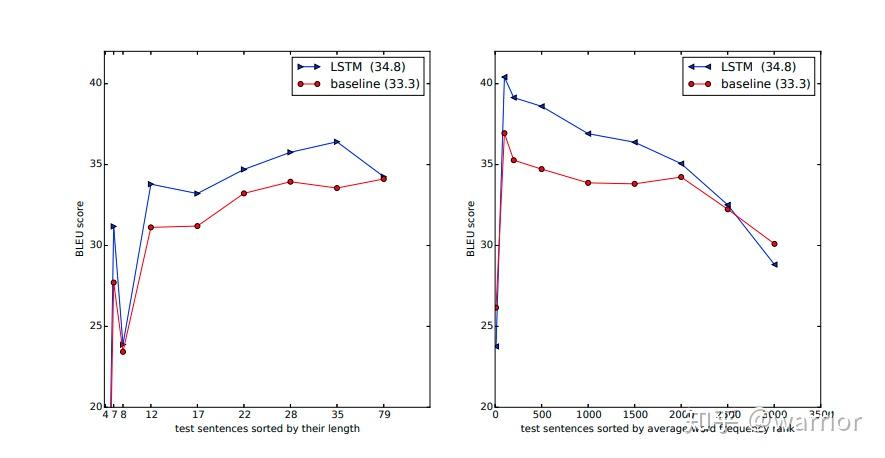
相比较 baseline,使用 LSTM 学习序列数据有什么区别?
![img]()
- 左图呈现了 BLEU 分数随着句子长度的增加,x 轴代表测试句子长度,由图中可以看出,在长度小于 35 的句子上,LSTM 模型的分数都比 baseline 要高
- 右图呈现的就是对那些比较生僻的句子(句子中单词在词表中的排序的平均值靠后),模型的泛化能力,x 轴代表 测试句子的 词平均出现频率排名。可以看到,在词平均出现频率排名前 2500 的句子,LSTM 表现要更好
为什么句子逆序输入模型,相当于引入许多短期依赖关系?
- 正序输入:缩短了 output sequence 中的单词与其对应的 input sequence 中单词的距离:当模型读取最后一个输入单词时候,它与需要对应的模型输出的第一个单词是距离输入最近的,保存的信息更多
- 反序输入:逆序读取的方式大大缩短了 input sequence 第一个单词与 output sequence 第一个单词的距离
- 比如源序列是 ABC,目标序列是 WXYZ,正向输入是 C 与 W 距离最近,逆向输入 A 与 W 最近
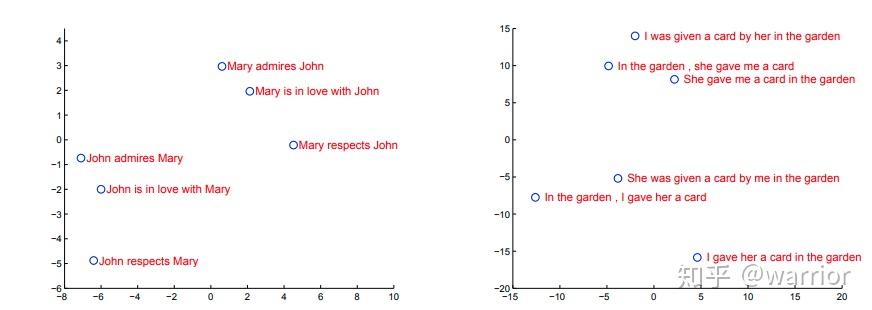
seq2seq 中,对隐藏状态向量有什么特点?
![img]()
- 将隐藏状态进行二维 PCA 投影。这些短语是按照词义聚类的,上图左边的图表明模型的向量对主被动语态不太敏感 (距离比较远), 右边的图表明模型对词序列比较敏感 ( 距离较近)
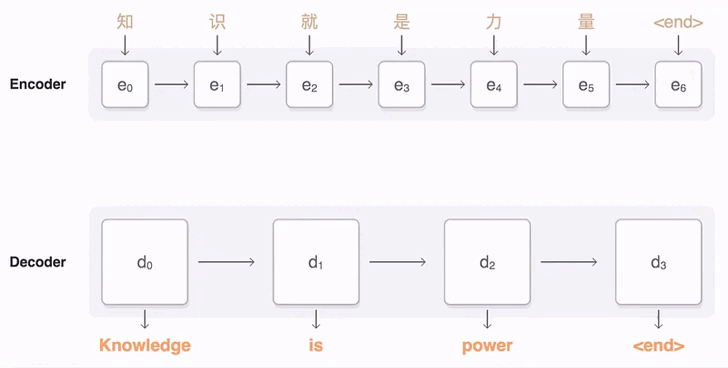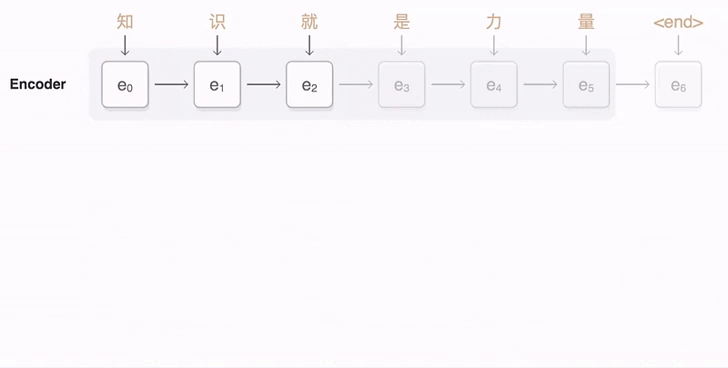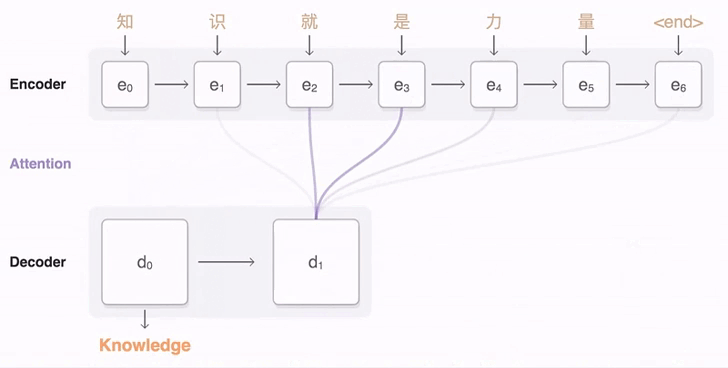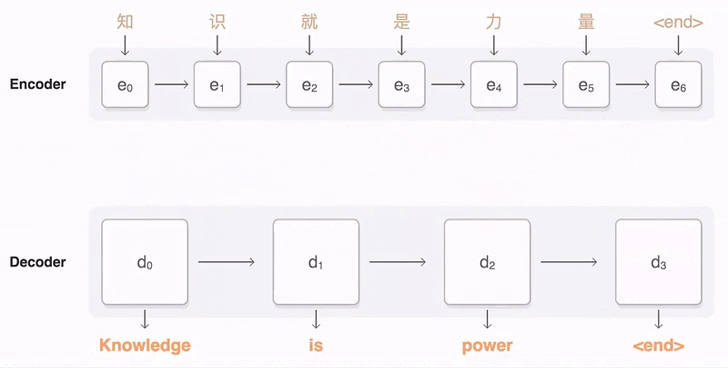
如何在 Seq 2 Seq 中引入注意力机制?
![]()
- 经典 Seq 2 Seq 模型:由 encoder-decoder 组成,encoder 按照时序对输入进行建模,并输出最后一个时序的隐状态到 decoder,最后时序的隐状态包含越来越少以前的信息,面对长句子,模型效果会下降
- Attention Seq 2Seq 模型:经典的 Seq 2 Seq 模型只使用最后时刻的隐状态,无法解决长程依赖问题,理想的状态是让 decoder 选择 encoder 的任意时刻的隐状态,作为自己当前时刻的输入隐状态。上图是 decoder 以不同的关注度选择 encoder 隐状态的过程
- 根据不同加权隐状态的方法,将 Seq 2 Seq 的注意力机制分为 Bahdanau Attention、Luong Attention
参考: