SpatialDropout
SpatialDropout 是单人姿态估计提出的网络,主要思想是预测 heatmap 上每个 grid 的类别
什么是 SpatialDropout ?
![]()
- SpatialDropout 是单人姿态估计提出的网络,主要思想是预测 heatmap 上每个 grid 的类别
- SpatialDropout 针对 pooling 层会降低 location 的精度损失,提出 SpatialDropout 策略
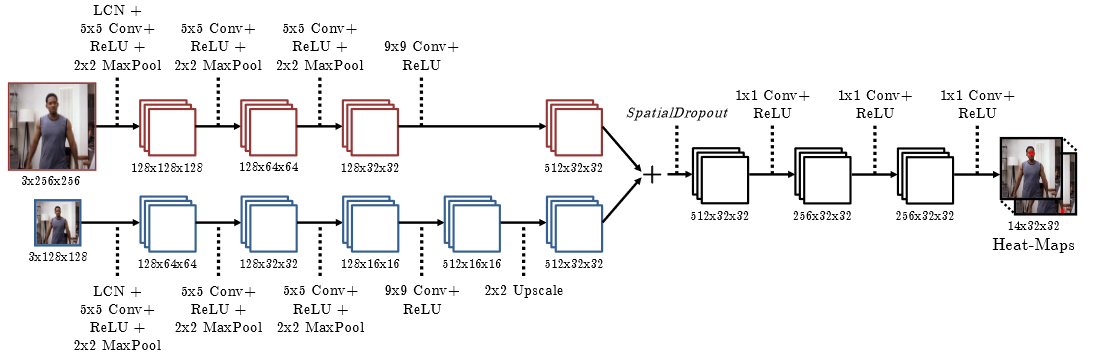
SpatialDropout 的网络结构?
![]()
- 使用 2 种分辨率的图片输入网络,最后输出 32 x 32 的 heatmap,每个 grid 预测 14 个关节中的一个
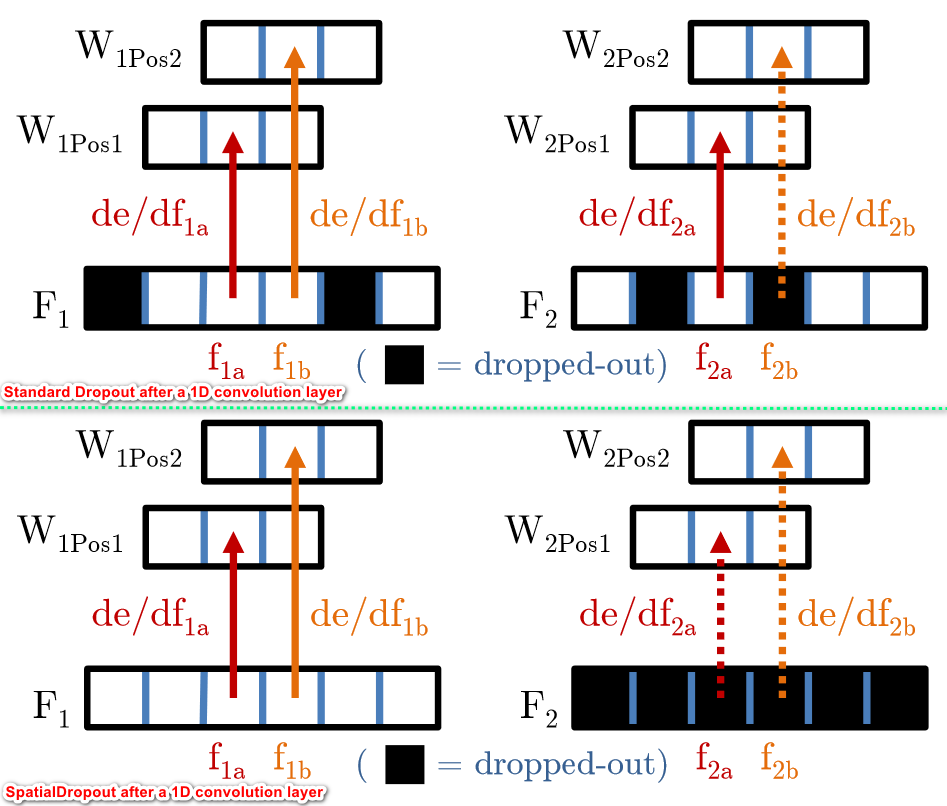
SpatialDropout 的原理?
![]()
- 标准的 dropout:通过每次随机抑制部分神经元,防止过拟合。在进行反向传播的时候,W2 的中心位置的梯度只能收到一个 f2a 的,f2b 被抑制为 0 了,但是因为传统的分类任务中,我们不关注空间点与点之间的关联性,我们只关注核心特征是什么无所谓在哪里,而且我们把相邻的输出近似当作差不多相等的
- SpatialDropout:人体关键点估计要关注点的位置信息,所以标准 dropout 无法使用。普通的 Dropout 会将部分元素失活,而 Spatial Dropout 则是随机将部分区域失失活,简单理解就是通道随机失活。一般很少用普通的 Dropout 来处理卷积层,这样效果往往不会很理想,原因可能是卷积层的激活是空间上关联的,使用 Dropout 以后信息仍然能够通过卷积网络传输。而 Spatial Dropout 直接随机选取 feature map 中的 channel 进行 dropout,可以让 channel 之间减少互相的依赖关系
人体姿态估计的人工标注误差?
![]()
- 人体姿态估计标注是不规范的,也是存在歧义的,主要表现为关键点的标注很难具体的说到底在哪个点?如图所示是作者请了 13 个人对数据集标注的结果
- 用这个标注数据去计算了标准差,对于每个关节就能产生自己的 sigma

SpatialDropout 的损失函数?
- 按分类损失计算
参考: