RAG 技术 06 - 后检索
检索出问题相关的上下文后,如果将所有检索到的块直接送入 LLM,可能不是最佳选择,因为检索出来的文本可能包括冗余信息,或者文档长度太长需要压缩
Rerank
根据文档与查询的相关性对文档进行排序,使用 reranker 模型重新排序检索结果
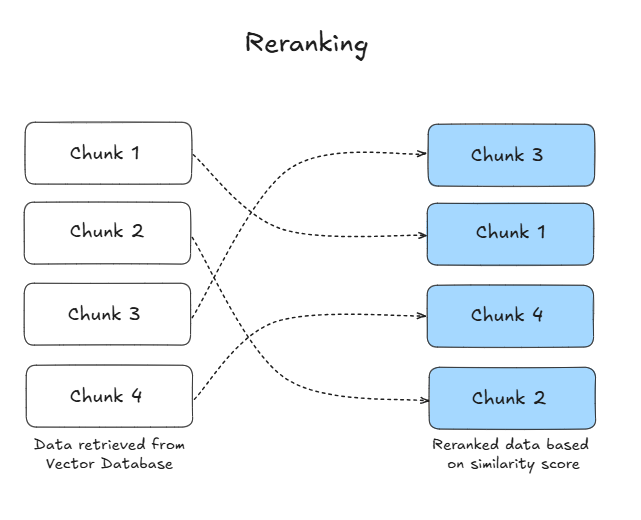
rerank 有两种规则实现文档排序
- ReRank-Rulebase:计算指标以重新排列块根据某些规则。常见的指标包括:多样性,相关性和 MRR(最大边际相关性)
- ReRank-Modelbase:专门的 AI 模型 (Rerank 模型),用于评估这些检索到的文档与用户查询相关的相关性并确定其优先级
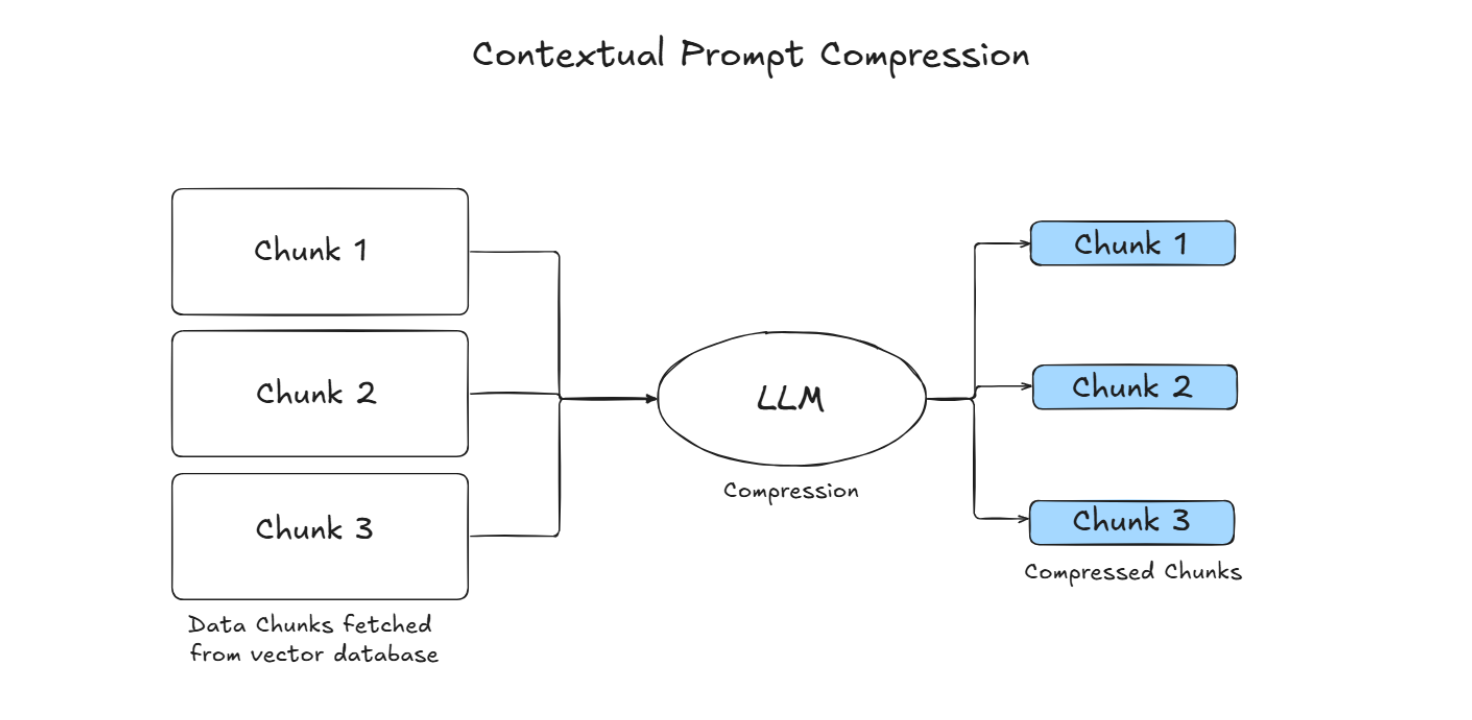
Compression
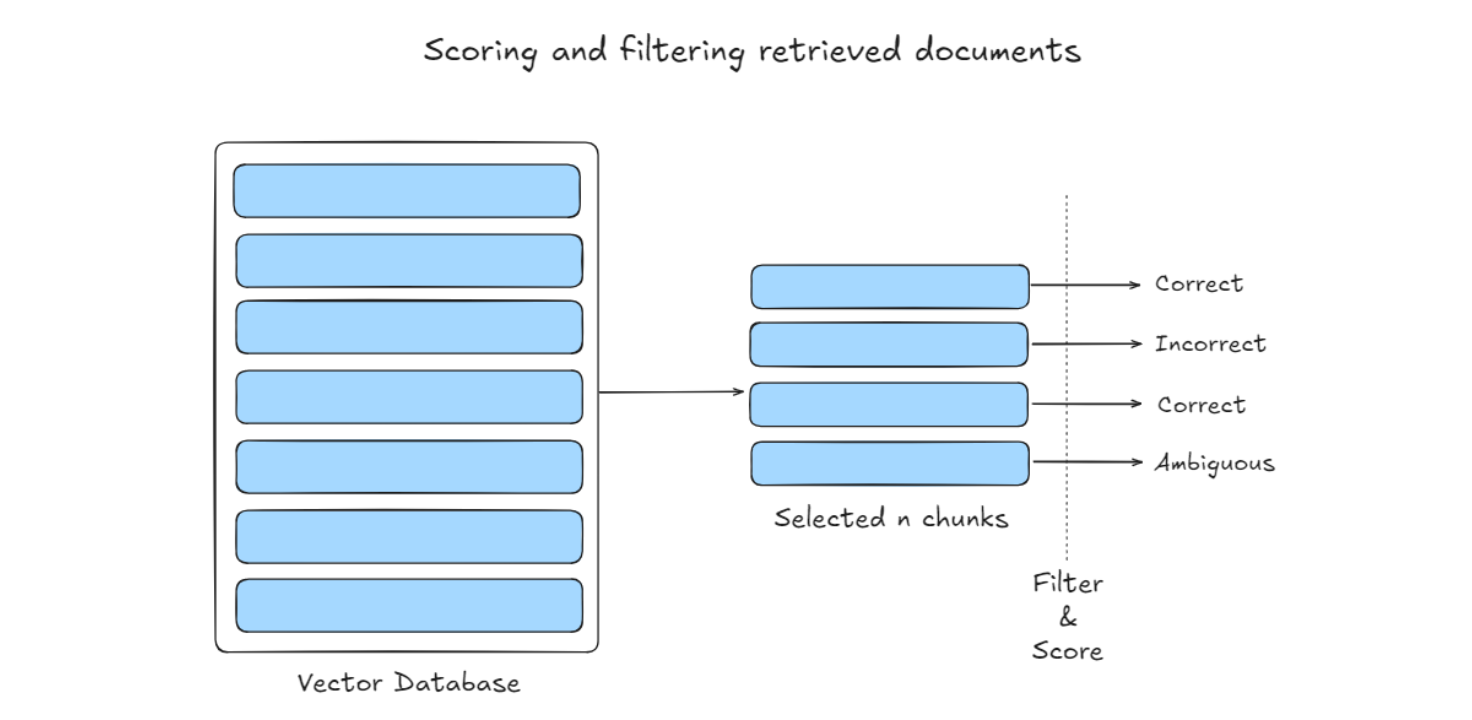
RAG 中的一个常见误解该过程是指尽可能多地检索相关文档并将其连接起来,形成一个冗长的文档检索提示是有益的。然而,过度的上下文可能会引入更多噪音,降低 LLM 对关键信息。解决这一问题的一种常见方法是压缩并选择检索到的内容
Selection
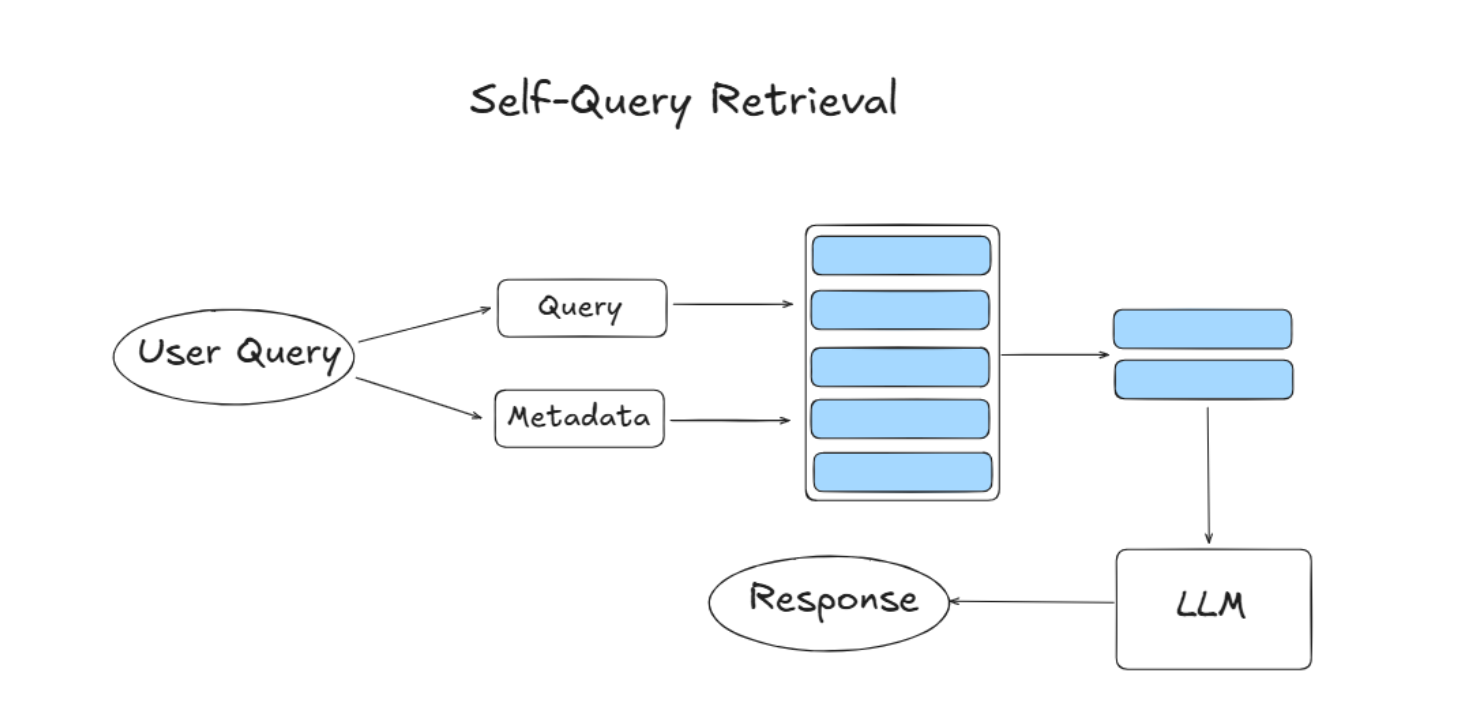
对于 self-Query retrieval 来说,在利用文档时,还可以根据用户查询与文档元数据过滤检索结果
CRAG 则引入了一个轻量级检索评估器,用于评估检索到的文档的整体质量,提供触发不同知识检索操作(如 “正确”、“不正确” 或 “模糊”)的置信度
CRAG 还可以通过合并 Web 搜索来确定检索到的结果是否相关,从而解决静态语料库中的限制