RCNN:Rich feature hierarchies for accurate object detection and semantic segmentation
利用 CNN 进行目标检测的首个神经网络,首先利用选择性搜索提取图片的 2000 个左右的 Region Proposal,然后通过 AlexNet 提取得到固定长度的特征,接着使用支持向量机 (SVM) 分析这些特征,以实现获选区域的分类,使用边界框回归分析这些特征,获取获选框更精细位置
什么是 RCNN?
![RCNN-20230408141544]()
- 利用 CNN 进行目标检测的首个神经网络
- 利用选择性搜索 (SelectiveSearch,SS) 提取图片的 2000 个左右的 Region Proposal,然后通过 AlexNet 提取得到固定长度的特征,接着使用支持向量机 (SVM) 分析这些特征,以实现获选区域的分类,使用边界框回归 (Bounding box Regression) 分析这些特征,获取获选框更精细位置
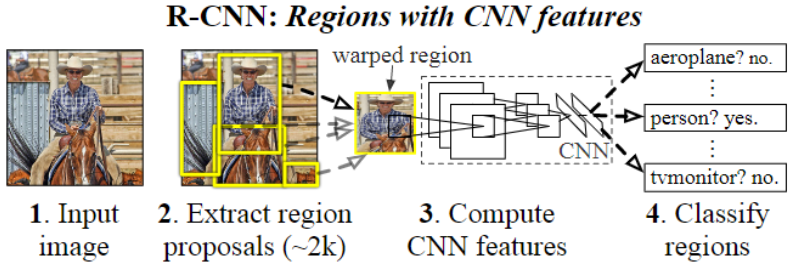
RCNN 的目标识别任务步骤?
- (1) 图片输入
- (2) 获取获选框: 利用选择性搜索 (SelectiveSearch,SS) 算法在图像中提取 2000 个左右的 Region Proposal
- (3) 微调 CNN 分类模型: 将每个 Region Proposal 缩放成 227x227 的大小并输入到 CNN,做 N+1 的多分类分类
- (4) 训练 SVM 分类模型: 将 CNN 模型的 fc7 层的输出作为特征,训练 SVM 的目标及背景的二分类器
- (5) 边界框回归: 对被 SVM 分类为目标的获选框,用边界框回归 (Bounding box Regression) 校正原来的建议窗口,生成预测窗口坐标
RCNN 微调时,输入、输出是什么?损失如何计算?
- 输入: 使用 AlexNet 进行微调,输入是目标检测的候选框区域的图片,缩放到(227,227),根据 IOU>0.5 判定正样本,自定义数据采集器,使得每次训练 128 个图像,其中 32 个正样本,96 个负样本
- 输出:输出是 N+1 分类,判断该候选框内的目标类别
- 损失函数:使用交叉熵损失 (CrossEntropyLoss)
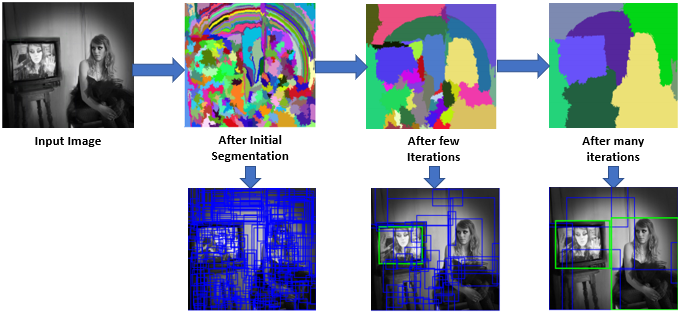
什么是选择性搜索 (Selective Search, SS) ?
![]()
- 使用一种过分割手段,将图像分割成小区域 (1k~2k 个)
- 查看现有小区域,按照合并规则合并可能性最高的相邻两个区域。重复直到整张图像合并成一个区域位置
- 优先合并以下四种区域: 颜色(颜色直方图)相近的, 纹理(梯度直方图)相近的,合并后总面积小的
RCNN 是如何训练候选框的分类模型的?
- 1)预训练模型:在 imageNet 上预训练 AlexNet 模型;
- 2)微调预训练模型:修改 AlexNet 模型最后一层,类别改为 (N+1),在 N 个获选框上微调模型。根据 IOU>0.5 判定正样本,并使得每个 batchsize 放入 96 负样本、32 正样本训练
- 3)训练 SVM 模型:完成微调后,输出每个获选框的 fc7 层 4096 维的特征,然后在 SVM 上训练该特征,获得获选框的分类模型。训练 SVM 给标签时,判断某个候选框是某个类别的正样本的要求是 IOU>0.3,为每个类别按正负样本训练 SVM 分类器
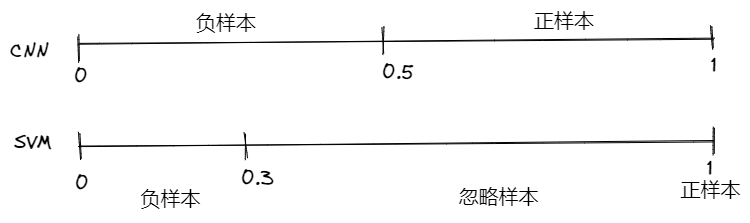
RCNN 为什么不使用微调后的 Alexnet 作为获选框的分类模型,而是重新构建 SVM?
![Drawing 2023-02-06 11.43.00.excalidraw]()
- 两个模型训练时,对正样本的定义不同,微调 AlexNet 时,IOU>0.5 即可;训练 SVM 时,IOU=1,这意味着 AlexNet 的正负样本比例比 SVM 大
- AlexNet 更加容易过拟合:为了防止 AlexNet 向负样本过拟合,取 IOU=0.5 对正负样本进行划分,但是这样也导致和现实不符合,因为 SS 采样得到的样本负样本的数量占绝大比例(虽然 batchsize 正负样本按 96:32 输入,也存在该问题),进而导致 AlexNet 分类效果比 SVM 差
- SVM 仅依靠少数的支持向量就完成分类,不容易发生过拟合,按实际更小的正样本(IOU=1)比例即可完成分类,如果取 IOU>0.5 为正样本,mAp 反而变小
RCNN 中,图片 Resize 有几种方式?
![]()
- B 先扩充后裁剪: 直接在原始图片中,把 bounding box 的边界进行扩展延伸成正方形,然后再进行裁剪;如果已经延伸到了原始图片的外边界,那么就用 bounding box 中的颜色均值填充
- C 先裁剪后扩充:先把 bounding box 图片裁剪出来,然后用固定的背景颜色填充成正方形图片 (背景颜色也是采用 bounding box 的像素颜色均值)
- **D 强制裁剪:** 不管图片的长宽比例,管它是否扭曲,进行缩放就是了,全部缩放到 CNN 输入的大小

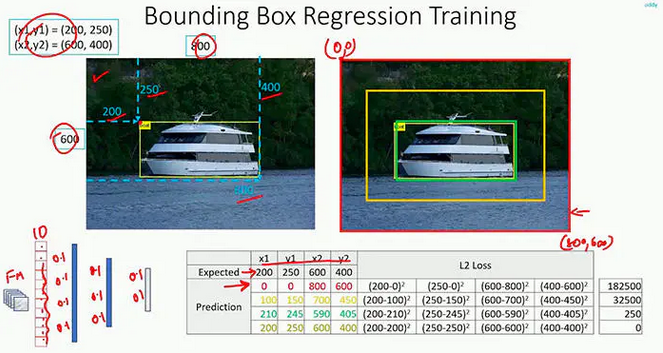
RCNN 如何做边界框回归 (Bounding box Regression)?
- 对每一类目标,使用一个线性脊回归器进行精修。 输入为深度网络 pool5 层的 4096 维特征,输出为 xy 方向的缩放和平移。 训练样本:判定为本类的候选框中和真值重叠面积大于 0.6 的候选框
![]()
- 例子:以密集连接层输出输出边界框的左上、右下的坐标点,说明使用候选框的 4096 维特征可以计算得到获选框坐标
搭建模型,输出为边界框的左上、右下的坐标点
1
2
3
4
5
6
7
8
9
10
11
12# load the VGG16 network, ensuring the head FC layers are left off
vgg = VGG16(weights="imagenet", include_top=False, input_tensor=Input(shape=(224, 224, 3)))
vgg.trainable = False
flatten = vgg.output
flatten = Flatten()(flatten)
bboxHead = Dense(128, activation="relu")(flatten)
bboxHead = Dense(64, activation="relu")(bboxHead)
bboxHead = Dense(32, activation="relu")(bboxHead)
bboxHead = Dense(4, activation="sigmoid")(bboxHead) # 输出为边界框的左上、右下的坐标点
model = Model(inputs=vgg.input, outputs=bboxHead)
opt = Adam(lr=INIT_LR)
model.compile(loss="mse", optimizer=opt)模型训练:
BASE_PATH = "dataset" IMAGES_PATH = os.path.sep.join([BASE_PATH, "images"]) ANNOTS_PATH = os.path.sep.join([BASE_PATH, "airplanes.csv"]) data = [] targets = [] for row in rows: (filename, startX, startY, endX, endY) = row imagePath = os.path.sep.join([IMAGES_PATH, filename]) image = cv2.imread(imagePath) # 模型监督信息为:边界框的真实左上、右下的坐标点,按图片大小归一化 (h, w) = image.shape[:2] startX = float(startX) / w startY = float(startY) / h endX = float(endX) / w endY = float(endY) / h image = load_img(imagePath, target_size=(224, 224)) image = img_to_array(image) data.append(image) targets.append((startX, startY, endX, endY)) BASE_PATH = "dataset" IMAGES_PATH = os.path.sep.join([BASE_PATH, "images"]) ANNOTS_PATH = os.path.sep.join([BASE_PATH, "airplanes.csv"]) data = [] targets = [] for row in rows: (filename, startX, startY, endX, endY) = row imagePath = os.path.sep.join([IMAGES_PATH, filename]) image = cv2.imread(imagePath) # 模型监督信息为:边界框的真实左上、右下的坐标点,按图片大小归一化 (h, w) = image.shape[:2] startX = float(startX) / w startY = float(startY) / h endX = float(endX) / w endY = float(endY) / h image = load_img(imagePath, target_size=(224, 224)) image = img_to_array(image) data.append(image) targets.append((startX, startY, endX, endY))模型输出
![]()

RCNN 有哪些缺点?
- 1、训练分多步:R-CNN 的训练先要 fine tuning 一个预训练的网络,然后针对每个类别都训练一个 SVM 分类器,最后还要用 regressors 对 bounding-box 进行回归,另外 region proposal 也要单独用 selective search 的方式获得,步骤比较繁琐
- 2、时间和内存消耗比较大。在训练 SVM 和回归的时候需要用网络训练的特征作为输入,特征保存在磁盘上再读入的时间消耗还是比较大的
- 3、测试的时候也比较慢,每张图片的每个 region proposal 都要做卷积,重复操作太多