基于 tensorrt 量化模型
本文讨论 tensorrt 的量化原理
TensorRT 的量化原理?
![基于tensorrt对模型进行量化-20250123161943]()
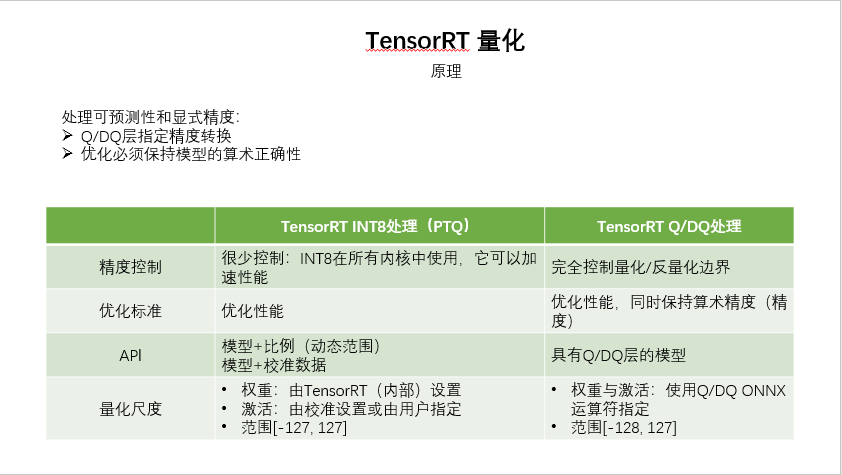
- TensorRT 支持量化浮点,可以显着提高了算术吞吐量,同时降低了存储要求和内存带宽。在量化浮点张量时,TensorRT 需要知道它的动态范围 —— 即表示什么范围的值。动态范围信息可由构建器根据代表性输入数据计算(这称为校准
calibration)。或者,您可以在框架中执行量化感知训练,并将模型与必要的动态范围信息一起导入到 TensorRT,分别对应以下的 PQT 量化、QAT 量化 - TensorRT 支持 2 种量化,一种是 INT8 推理,也就是 PQT 量化,另一种是带有 Q/QD 算子以指定量化参数的量化(QAT 量化)
- INT8 量化需要进行校准,以便确定激活值的量化范围;而带有 Q/DQ 操作的模型则将量化参数自带在 Q/DQ 算子中,可以直接量化
TensoRT 如何进行 PTQ 量化?
![基于tensorrt对模型进行量化-20250123161944]()
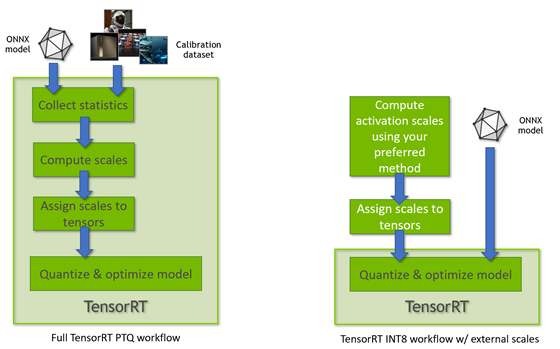
- PTQ 量化时,量化激活值阶段需要进行校准,可以使用有代表的数据集进行校准,也可以外部输入校准表进行校准
- 所需的输入数据量取决于应用,但实验表明,约 500 幅图像足以校准 ImageNet 分类网络。
- 官方提供配套工具 pytorch-quantization 进行 PTQ 量化
TensoRT 如何使用经过 QAT 的 ONNX 模型?
![基于tensorrt对模型进行量化-20250123161944-1]()
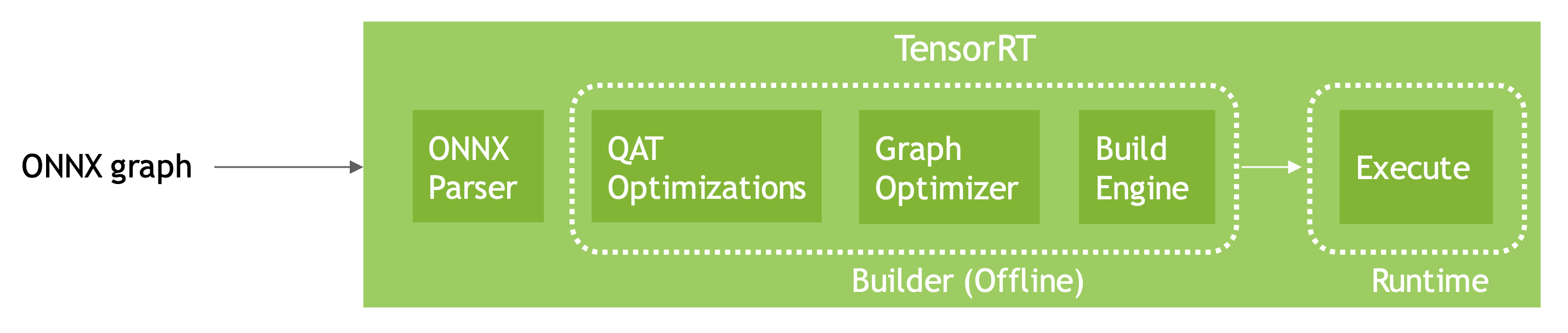
- TensoRT8 可以直接加载通过 QAT 量化后且导出为 ONNX 的模型,官方提供配套工具 pytorch-quantization 进行 QAT 量化
TensoRT 如何使用使用 Pytorch 模型进行量化推理
![基于tensorrt对模型进行量化-20250123161944-2]()
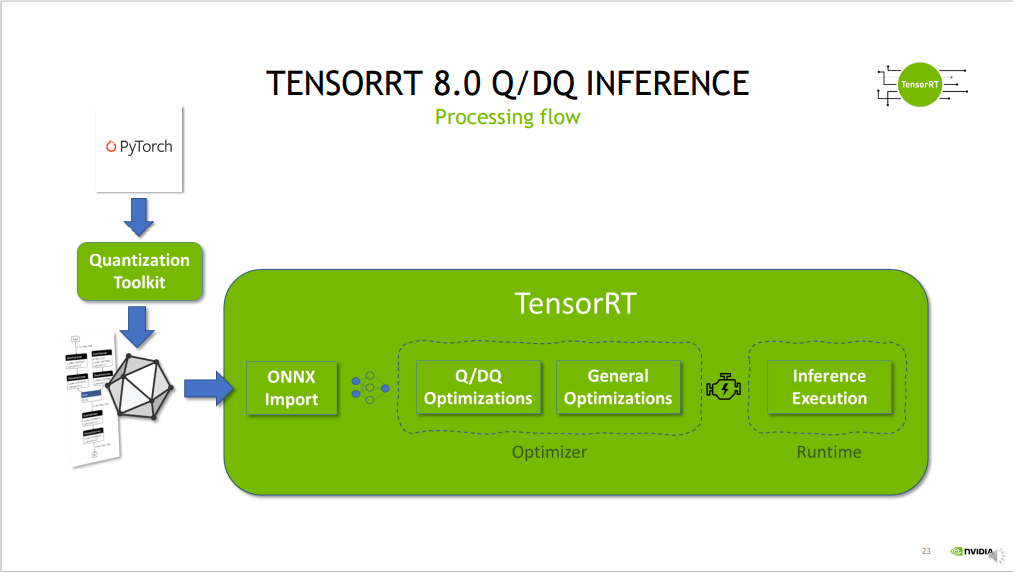
- 已经训练好的模型,经过 Quantization Toolkit 进行模型量化
- 使用
torch.onnx.export导出模型为 onnx - tensorRT 对 onnx 根据 Q/DQ 的设置量化模型 + 通用优化操作,生成推理引擎,并执行推理
逐张量 (Per-tensor) 量化与逐通道 (Per-channel) 量化?
![基于tensorrt对模型进行量化-20250123161945]()
- 逐张量 (Per-tensor) 量化:其中使用单个尺度值(标量)来缩放整个张量
- 逐通道 (Per-channel) 量化:对于卷积神经网络,其中尺度张量沿给定轴广播
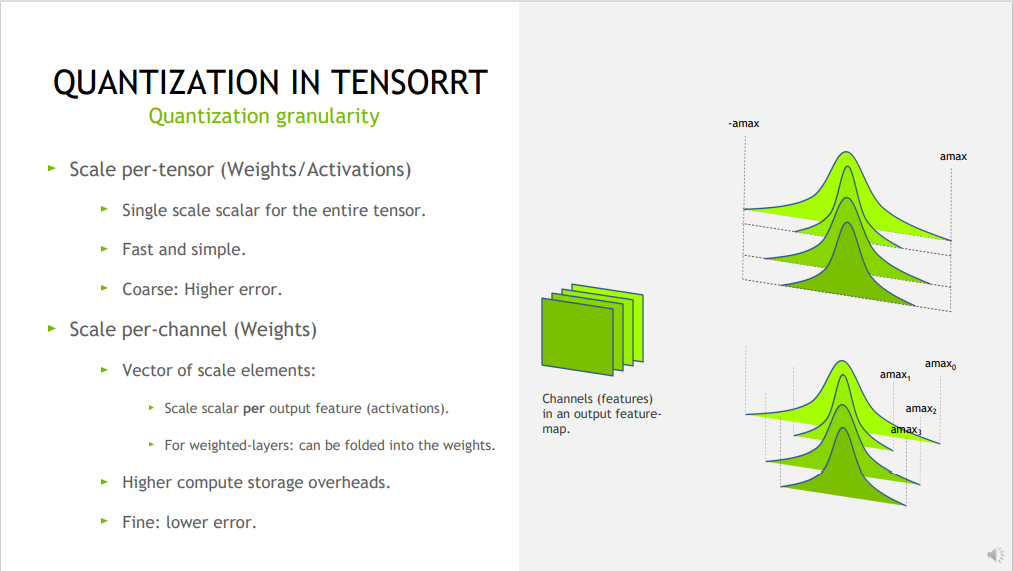
TensorRT 的显式量化?
- 在显式量化的网络中,量化值和非量化值之间转换的缩放操作由图中的 IQuantizeLayer 和 IDequentizeLayer 节点显式表示,这些节点此后将被称为 Q/DQ 节点。与隐式量化相比,显式形式精确地指定了向 INT8 和从 INT8 进行转换的位置,优化器将仅执行由模型语义决定的精度转换
- 当 PyTorch 或 TensorFlow 中的模型导出到 ONNX 时,ONNX 使用显式量化表示法 -,框架图中的每个伪量化操作都导出为 Q,后跟 DQ
- 当 TensorRT 检测到模型中有 QDQ 算子的时候,就会触发显式量化
TensorRT 的隐式量化?
- 在处理隐式量化网络时,TensorRT 在应用图形优化时将模型视为浮点模型,并利用 INT8 机会优化层执行时间。如果一个层在 INT8 中运行得更快,那么它在 INT8 执行。否则,使用 FP32 或 FP16。 在此模式下,TensorRT 仅针对性能进行优化,您几乎无法控制 INT8 的使用位置 - 即使您在 API 级别明确设置了一个层的精度,TensorRT 也可能在图形优化期间将该层与另一层融合,并丢失它必须在 INT8 中执行的信息
- TensorRT 的 PTQ 能力生成隐式量化网络
TensorRT 的 Network-Level 精度设置?
- FP32 是大多数框架的默认训练精度,因此我们将首先使用 FP32 进行推断。推理通常需要比训练更少的数值精度。较低的精度可以在不牺牲精度的情况下实现更快的计算和更低的内存消耗
- 降低的精度支持取决于您的硬件,参考:Hardware and Precision
- 注意: TensorRT 为层选择精度,但是如果设置精度导致速度变慢或者该层没有低精度实现时,这些层将使用高精度
- C++ 检测硬件支持精度并设置精度
1
2
3if (builder->platformHasFastFp16()) { … };
config-> setFlag(BuilderFlag: :kFP16);
TensorRT 的 Layer-Level 的精度设置?
config-> setFlag(BuilderFlag: :kFP16);提供了精度粗粒度控制。然而有时网络的一部分需要更高的动态范围或对数值精度敏感,可以约束每层的输入和输出类型- C++ 上为某一层设置输入输出类型
1
2layer->setPrecision(DataType::kFP16)
layer->setOutputType(out_tensor_index, DataType::kFLOAT) - 计算使用精度: 计算将使用与输入首选的浮点类型相同的浮点类型。大多数 TensorRT 实现具有相同的输入和输出浮点类型;然而,卷积、反卷积和 FullyConnected 可以支持量化 INT8 输入和非量化 FP16 或 FP32 输出,因为有时需要使用来自量化输入的更高精度输出来保持精度。
- 上下层精度设置冲突: 设置精度约束提示 TensorRT 应该选择输入和输出与首选类型匹配的层实现,如果上一层的输出和下一层的输入与请求的类型不匹配,则插入重新格式化操作。
什么是 PyTorch-Quantization?
![基于tensorrt量化模型-20250123183219]()
- TensorRT 开发的量化工具包,可以便捷将 Pytorch 的模型量化为 TensorRT 支持的量化模型,它支持将 Pytorch 模型按 PQT 或 QAT 量化。
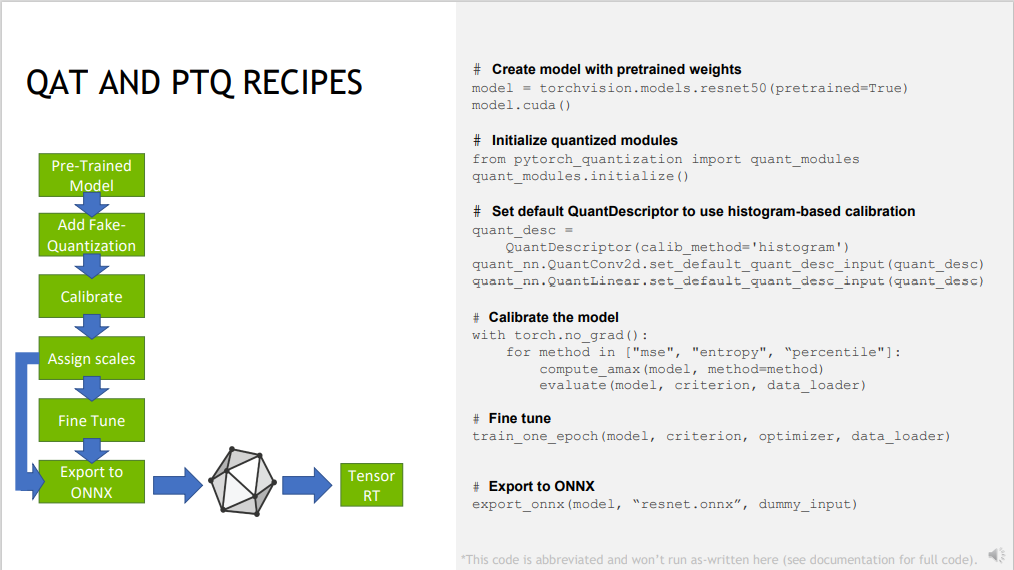
使用 PyTorch-Quantization 导出 PQT 模型
使用以下代码将量化每个模块,如果不希望所有模块都量化,则应手动替换量化模块
1 | from pytorch_quantization import quant_modules |
为了有效推断,我们希望为每个量化器选择一个固定范围。从预先训练的模型开始,最简单的方法是校准
1 | quant_desc_input = QuantDescriptor(calib_method='histogram') |
评估量化 + 校准后的模型,并保存
1 | criterion = nn.CrossEntropyLoss() |
使用 PyTorch-Quantization 导出 QAT 模型
对于 PQT 模型,对其进行微调,得到 QAT 模型
1 | criterion = nn.CrossEntropyLoss() |
将经过 PyTorch-Quantization 量化的模型导出为 ONNX
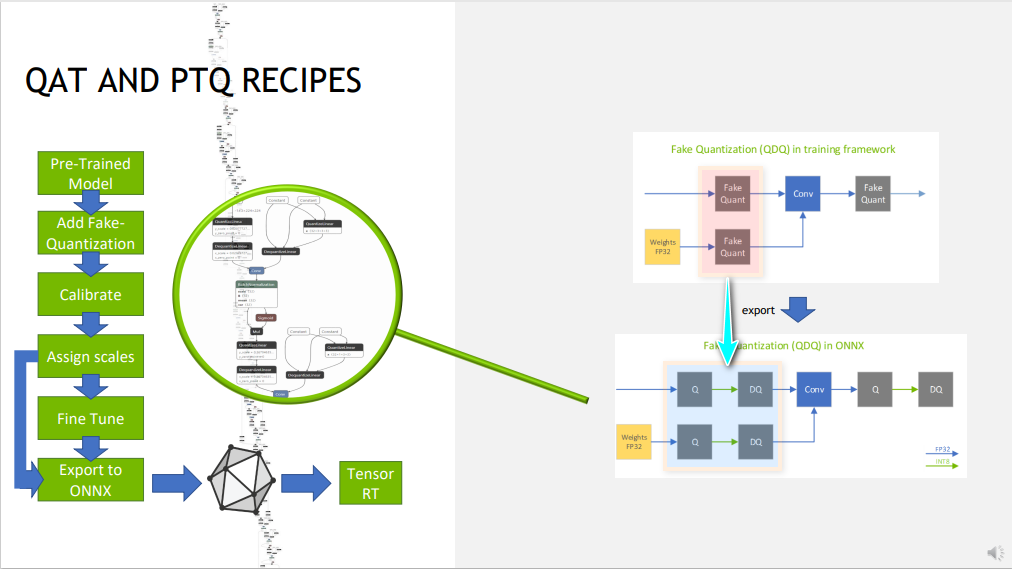
导出到 ONNX 的目标是通过 TensorRT 部署推理,而不是 ONNX 运行时。因此,我们只将假量化模型导出为 TensorRT 将采用的形式。假量化将被分解成一对 QuantizeLinear/DequantizeLinear ONNX ops
1 | from pytorch_quantization import nn as quant_nn |
参考: