RAG 演进 02-AdvancedRAG
AdvancedRAG 侧重于增强检索到的文档的相关性和范围,这些技术(包括密集检索、混合搜索、重新排名和查询扩展)解决了 NaiveRAG 基于关键字的检索的限制
文章《15 Advanced RAG Techniques from Pre-Retrieval to Generation》 总结了提升 RAG 系统性能的 4 类 15 种技术,以优化 RAG 的输出质量、成本及鲁棒性
这些技术分别是:
- 预检索与数据索引技术
- 技术 1:使用 LLM 提高信息密度(如 GPT-4 提取网页关键信息,减少冗余和噪声)
- 技术 2:分层索引检索(通过摘要实现多层检索,提升效率)
- 技术 3:假设性问题索引(生成 QA 对嵌入,解决查询 - 文档不对称问题)
- 技术 4:LLM 去重(聚类嵌入空间,合并重复信息)
- 技术 5:分块策略优化(A/B 测试分块大小、重叠率等参数)
- 检索技术
- 技术 6:LLM 优化搜索查询(适配 Google 语法或对话上下文)
- 技术 7:HyDE(生成假设性文档嵌入,提升语义相似性)
- 技术 8:RAG 决策器模式(判断是否需要检索,降低成本)
- 后检索技术
- 技术 9:重排序(优先展示最相关文档)
- 技术 10:上下文提示压缩(如 LLMLingua 框架,压缩无关信息)
- 技术 11:纠正性 RAG(T5 模型过滤不相关结果)
- 生成技术
- 技术 12:链式思考(CoT)提示(通过推理减少噪声影响)
- 技术 13:Self-RAG(自省标记,动态调用检索并批判输出)
- 技术 14:微调模型(提升忽略无关上下文的能力)
- 技术 15:自然语言推理(NLI 模型过滤无关内容)
预检索与数据索引技术
预检索优化主要目的是提高检索的质量,减少在检索阶段的冗余、错误信息,有助于降低 RAG 系统的成本及幻觉。
技术 1:使用 LLM 提高信息密度
RAG 外挂的数据源有不同的信息密度,如 markdown 等文本文件的信息密度一般比 Web 数据信息密度高,因为 Web 数据除了文本数据,还包含一些 html 标记数据,总的来说,数据源可能出现以下问题:
- 信息密度低 / 信息冗余:低信息内容要求输入更多 token 到 llm,这会导致使用 llm 成本上升
- 不相关信息或噪声:噪声可能误导 llm,甚至在一些常识问题上犯错,也就是外挂数据源引入了新幻觉
所以我们在存储数据前,可以使用 llm 提高数据源的信息密度,减少冗余数据,比如使用 llm 剥离 Web 数据中的 html 标记等信息,然后再存储到知识库中,

利用这个方法可以明显降低 token 数据
- 原始 html:~55000 token
- 精简 html:1500 token
- llm 处理后的 html:330 token
但是使用这个方法,可能会去除一些有用信息,需要提防
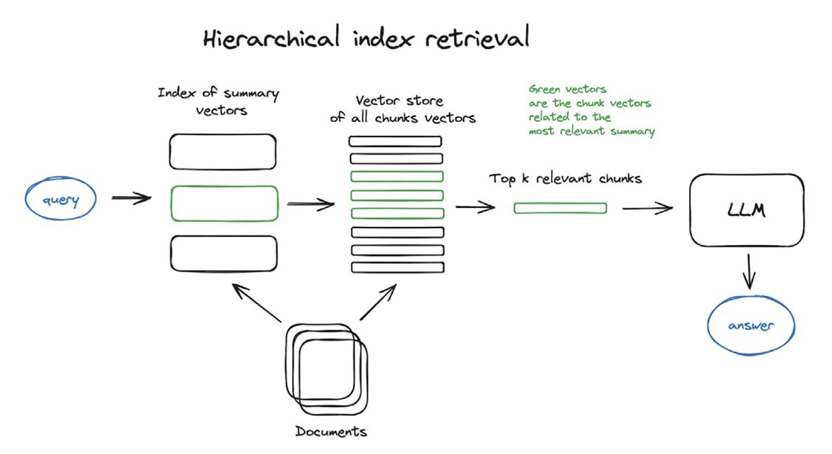
技术 2:分层索引检索
直接用用户提问去检索原始文本,可能因为原始文本的信息密度问题导致检索失败,假设知识库存在以下两个片段,当用户提问是:“llm 的定义?”,可能检索到片段 2,因为 llm 出现更加频繁,但是我们实际需要的是片段 1
- llm 是 xxxxxxx
- 我要使用 llm、llm 真好用
此时我们除了检索原始文本,还去检索由原始文本总结的摘要,形成摘要、原始文本双层的索引检索,提高检索的质量
技术 3:假设性问题索引
直接用用户提问去检索原始文本,除了信息密度问题,还有一个问题是:通过问题无法检索到答案相关片段,可能是因为答案片段完成没有出现问题的任何关键词或相近词
这是使用 llm 针对所有片段生成片段可能的提问,然后将问题与片段一起存储,这样检索类似场景的难度就会下降,比如有以下片段:
LLM 是大型语言模型(Large Language Model)的缩写,是一种基于深度学习的人工智能技术,通过大量文本数据训练,能够理解和生成自然语言。LLM 可用于文本生成、问答、翻译、摘要、情感分析等任务,还能进行代码生成和多模态内容创作。LLM 采用 Transformer 架构,通过自注意力机制捕捉上下文信息,利用无监督学习方法,如下一个单词预测和掩码语言模型,学习语言的模式和规律。
可以将其拆分为 3 个 QA 组合:
问题:llm 的定义? 回答:[以上原始文本]
问题:llm 能做什么? 回答:[以上原始文本]
问题:llm 的原理? 回答:[以上原始文本]
可以看出,使用这个方法会扩充知识库,提高检索成本,这时候可能使用 HyDE 技术,使用 llm 先回答用户提问,然后使用 [提问,llm 回答] 去检索文档,相当于没有扩充知识库,而是丰富了提问
技术 4:LLM 去重
不同数据源可能包含重复信息,并且会排挤到真正有用的上下文,比如以下 3 个片段
- 苹果清新甜美,苹果口感爽脆多汁,果香浓郁
- 苹果,一种常见的水果,富含维生素和膳食纤维,口感清脆多汁,营养丰富,可鲜食或加工成果汁、果酱等
- 苹果清新甜美,苹果口感爽脆多汁,果香浓郁
假设用户提问是 “苹果是什么?”,当检索系统(有可能)认为片段 1 比片段 2 评分高,由于片段 1、3 是重复的,所以 3 个片段的检索评分是 1=3>2,在检索系统要求返回评分 topk2 的片段时,只会返回片段 1、3,但是实际需要的是片段 2
所以说数据源的去重,有助于提高上下文的准确性,提高模型回答质量
技术 5:分块策略优化
不同数据源,信息密度不同,在分块构建索引时,不同的分块策略,可能影响检索准确性,所以在通过调整:分块大小、重叠率、选择不同嵌入模型,测试检索的效果很有必要
在 llamaindex 中,已经提供流程化的工具去评估检索器,可能通过效果以上参数,测试检索器性能,选择最佳的参数
检索技术
技术 6:LLM 优化搜索查询
在检索内容时,当用户的提问以特定的形式出现时,检索的质量更加精确,比如用户提问:张三 2025 年 2 月 7 日做了什么?直接检索可能检索到其他日期的事情,因为单个数字在检索系统起到的作用很小,此时我们将用户检索转换为
[“张三”,“2025-02-07”],然后使用这两个字段,类似数据库的方式去查找记录,得到的结果就是 100% 准确的
在多轮的对话系统中,直接使用某次对话去检索上下文可能失败,因为有些信息包含在对话历史中,比如以下对话
用户:xxx 的价格是多少
机器: xxx
用户:它能解决 xxxx
如果直接使用 "它能解决 xxxx" 去检索知识库,得到的肯定是错误答案,此时基于对话历史先用 llm 优化查询很重要
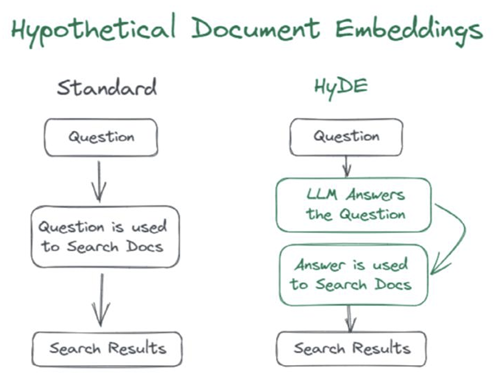
技术 7:HyDE
在查询 vs 文档不对称的 RAG 系统中,直接使用查询去检索文档的准确性不高,此时先使用 llm 生成回答,然后使用 [查询、llm 回答] 去检索文档,准确性得到提高
所谓不对称是指目标文档未直接包含查询内容,或者目标文档在语义层面回答了问题,但是没在字面上回答问题
技术 8:RAG 决策器模式
在准备检索文档前,先使用 llm 判断是否需要检索,对于一些常识问题或者在对话历史出现的问题,直接使用 llm 回答即可,而不需要再次去检索文档,已降低 RAG 系统的成本
比如提问:
请统计 "xxx" 这段话中的人物?
请将 "" 翻译为英文?
后检索技术
技术 9:重排序
在检索系统找到的文档中,根据查询可以分为以下 4 类
- 相关文档 (可以直接回答查询的)
- 有联系但是不相关
- 无联系并且不相关
- 反事实文档(与相关文档相反的)
理想的检索系统是只检索到 “相关文档”,但是实际情况往往会出现其他类型的文档,此时使用 llm 对检索到的文档进行重排序,可以有效提高 llm 的回答质量
技术 10:上下文提示压缩
和重排序不同的是,这里使用 llm 压缩检索到的文档,目的是提高相关文档的重要性,过滤掉其他文档的干扰
这里 llm 相当于一个过滤器,智能选择能回答提问的上下文
技术 11:纠正性 RAG
使用 llm 评估 RAG 系统的输出,将其分类为 [正确、不正确] 的,对于不正确的提问,直接丢起
比如提问 “苹果是什么?”,然后检索到的文档如下,使用每个检索到的文档去生成回答,一共得到 3 个回答,然后使用 llm 选择最佳答案
- 苹果清新甜美,苹果口感爽脆多汁,果香浓郁
- 苹果,一种常见的水果,富含维生素和膳食纤维,口感清脆多汁,营养丰富,可鲜食或加工成果汁、果酱等
- 苹果清新甜美,苹果口感爽脆多汁,果香浓郁
生成技术
技术 12:链式思考(CoT)提示

利用链式思考(CoT)提升模型在噪声或者不相关文档上回答准确性
技术 13:Self-RAG
给定一个输入提示和先前的生成,Self‑RAG 首先确定使用检索到的段落来扩充后续生成 是否有帮助。如果是,它会输出一个检索标记,该标记会根据需要调用检索器模型。
随后,Self‑RAG 会同时处理多个检索到的段落,评估它们的相关性,然后生成相应的任务输 出。然后,它会生成批评标记来批评自己的输出,并从事实性和整体质量方面选择最佳的输出
技术 14:微调模型
鉴于 LLM 通常不会针对 RAG 进行明确训练或调整,因此可以推断,针对此用例对模型进行微调可以提高 模型忽略不相关上下文的能力
技术 15:自然语言推理
使用自然语言推理 (NLI) 模型来识别不相关的上下文,并过滤