YOLACT++:Better Real-time Instance Segmentation
yolactplusplus 通过引入可变形卷积、使用更多的 anchor、重新生成的 Mask scoreing 分支等措施,改进了 yolact 模型
什么是 yolactplusplus ?
![]()
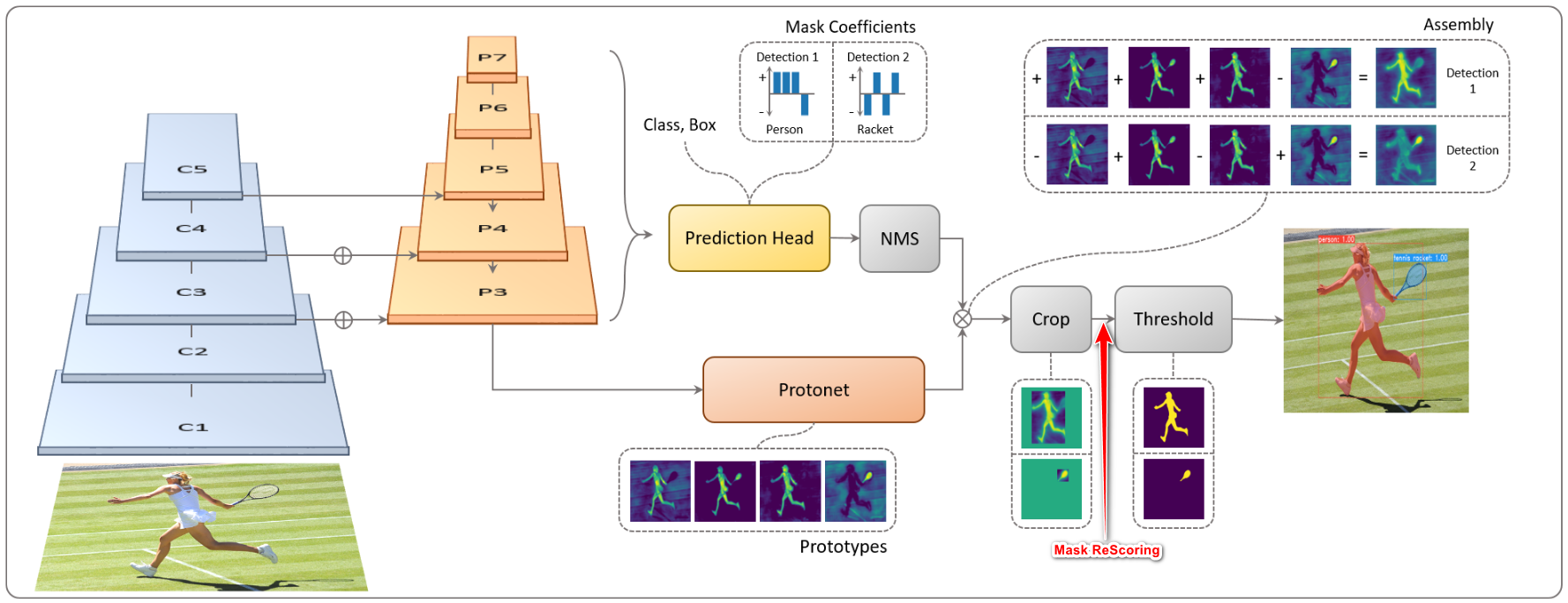
- YOLACT 主要是通过两个并行的子网络来实现实例分割的。(1) Prediction Head 分支生成各个 anchor 的类别置信度、位置回归参数以及 mask 的掩码系数;(2) Protonet 分支生成一组原型 mask。然后将原型 mask 和 mask 的掩码系数相乘,从而得到图片中每一个目标物体的 mask
- yolactplusplus 通过引入可变形卷积、使用更多的 anchor、重新生成的 Mask scoreing 分支等措施,改进了 yolact 模型
yolactplusplus 的网络结构?
![]()
- Featrue Backbone&Featrue Pyramid:使用 ResNet101 提取图片特征,并引入可变形卷积,然后使用 FPN 结构进行特征融合
- prototypes:从 P3 级别的特征生成全局的 prototype mask (138,138,32),这里固定是 32 个 mask,后续所有实例的 mask 是这 32 个 mask 的线性组合
- Predict Head:基于 anchor 预测目标的类别、位置和 Mask coefficients,其中 Mask coefficients 是每个 anchor 预测长度为 32 的向量,用于加权 prototypes,得到当前 anchor 的 mask 预测
- corp&Threashold:根据定位结果和 Mask 预测结果,裁剪目标区域,并使用二值化求得目标的 Mask
- Mask Re-Scoring:受 MS R-CNN 的启发,高质量的 mask 并不一定就对应着高的分类置信度,换句话说,以包围框得分来评价 mask 好坏并不合理,所以在模型后添加了 Mask Re-Scoring 分支,该分支使用 YOLACT 生成的裁剪后的原型 mask (未作阈值化) 作为输入,输出对应每个类别的 GT-mask 的 IoU
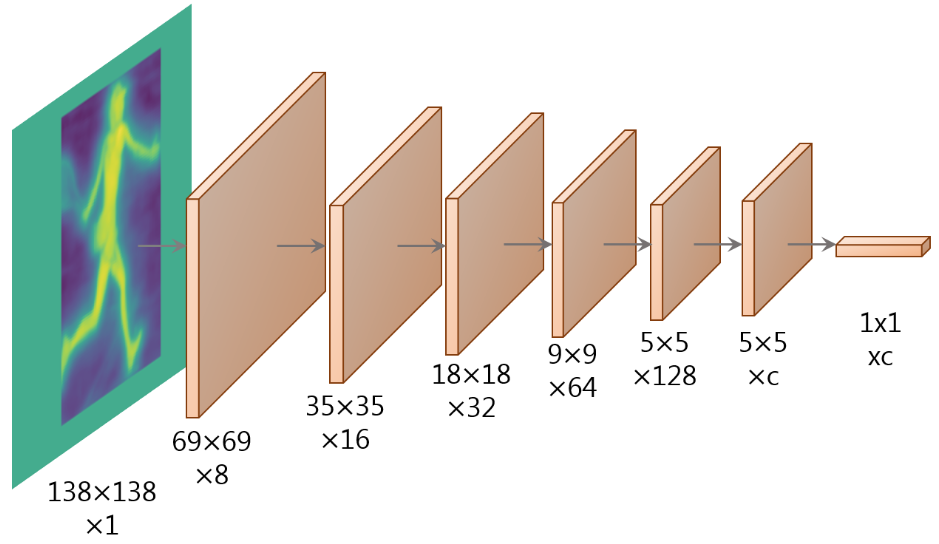
yolactplusplus 的 Fast Mask Re-Scoring 分支?
![]()
- 受 MS R-CNN 的启发,高质量的 mask 并不一定就对应着高的分类置信度,换句话说,以包围框得分来评价 mask 好坏并不合理,所以在模型后添加了 Mask Re-Scoring 分支,该分支使用 YOLACT 生成的裁剪后的原型 mask (未作阈值化) 作为输入,输出对应每个类别的 GT-mask 的 IoU
yolactplusplus 的 Prediction Head?
![]()
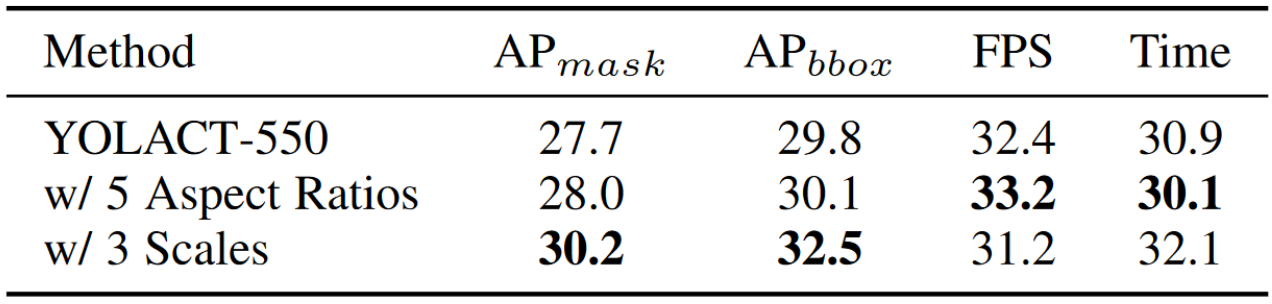
- YOLACT 是 anchor-based 的,yolactplusplus 对 anchor 设计进行优化。经过实验,选择在每个 FPN 层上乘 3 种大小,相当于 anchor 数量较原来的 YOLACT 增加了 3 倍
yolactplusplus 的可变形卷积?
![]()
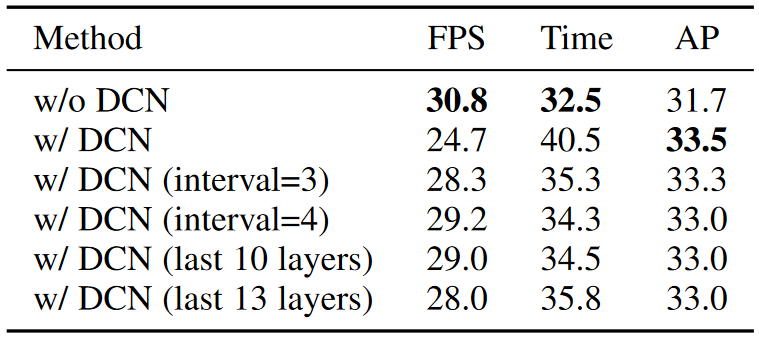
- 参考 Deformable ConvNets v2 的思路,将 ResNet 的 C3-C5 中的各个标准 3x3 卷积换成 3x3 可变性卷积,但没有使用堆叠的可变形卷积模块,因为延迟太高
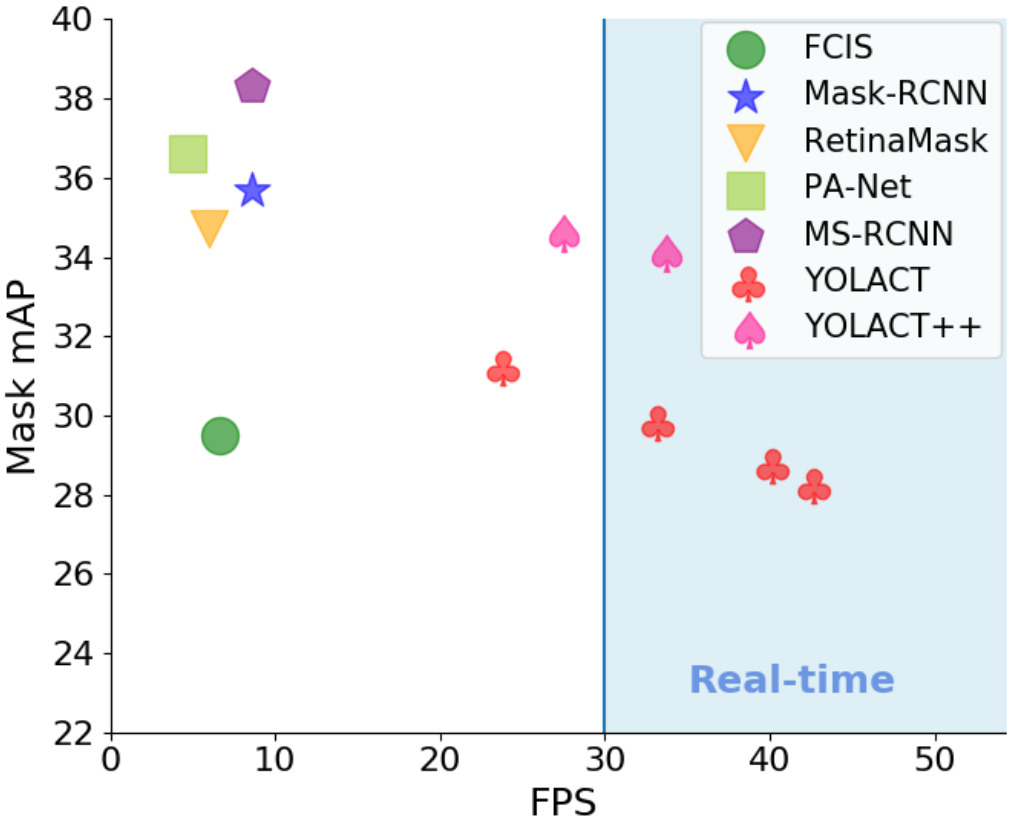
yolactplusplus 与 yolact 的区别?
![]()
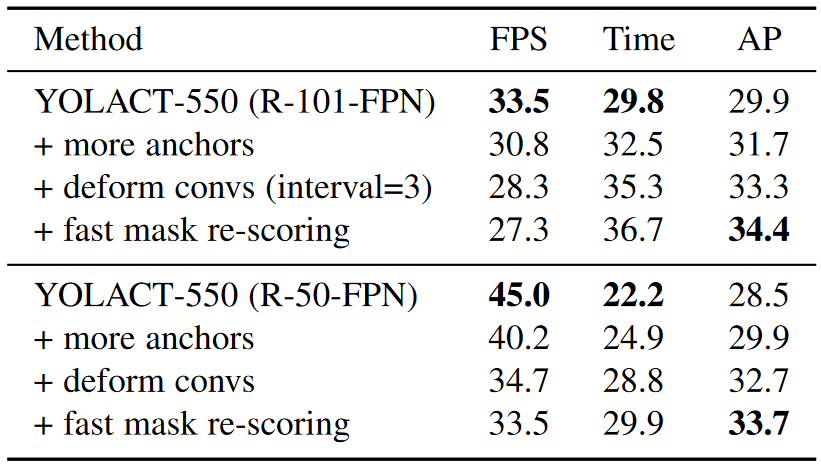
- yolactplusplus 通过引入可变形卷积、使用更多的 anchor、重新生成的 Mask scoreing 分支等措施,改进了 yolact 模型,yolactplusplus 效果越来越好,但是速度变慢了
yolactplusplus 与 Mask RCNN 的区别?
- YOLACT++ 直接使用全尺寸的 mask 作为 scoring 分支的输入,而 MS R-CNN 使用的是 ROI Align 后的特征再与其经过 mask 预测分支计算后的特征拼接后的组成的特征
- YOLACT++ 的 scoring 分支没有使用 FC 层,这使得分割的速度提高
参考: