OAA:Online Attention Accumulation for Weakly Supervised Semantic Segmentation
OAA 是一个弱监督语义分割网络,通过设计 OAA 模块,在训练过程中不断累积 CAM,这比单纯使用最后一次的 CAM 更能体现物体轮廓
什么是 OAA ?
![OAA-20230408143247]()
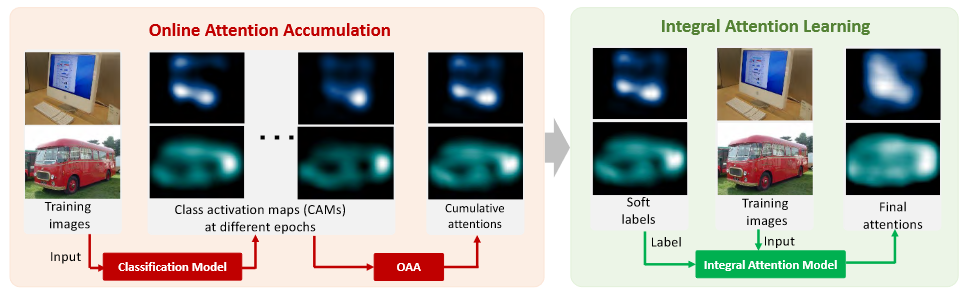
- 弱监督的语义分割一般从 类别激活映射图 (Class Activation Mapping,CAM) 生成图片的 mask,OAA 发现在训练的不同阶段,CAM 响应的位置有差异,如果把不同训练阶段得到 CAM 融合在一起,会不会比只取最后阶段的 CAM 效果好?本文由此提出。
- 个人理解:分类网络一般使用交叉熵学习,把 “是” 的概率推向 1,“否” 的概率推向 0,比如刚开始区分养和人,需要养、人的全身特征,最后收敛羊只需要判断有角即可,所以训练过程,网络关注的地方越来越高度抽象集中,但是这样的 CAM 对语义分割来说,起步越来越差,所以积累不同阶段 CAM,获得更好起点成为可能
- 上图 a 是原图,b-d 是不同阶段的 CAM 图,可以看出,其 CAM 区域越来越包含整个目标,e 是最后的融合 CAM,它比 b-d 更体现目标的 mask 区域

OAA 的网络结构?
![OAA-20230408143248]()
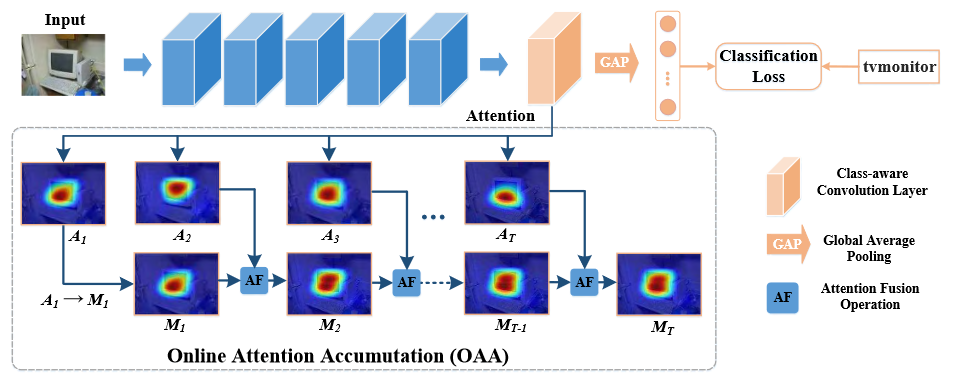
- backbone:VGG-16
- OAA:用于累积不同 epoch 的 CAM
OAA 的 OAA 模块?
![OAA-20230408143248]()
- 假设 class-aware convolutional layer 的输出是 F,首先使用 RELU 对其进行归一化处理
- 第一个 epoch 的 CAM () 用于初始化 ,第二个 epoch 则是 和 生成 ,其按照以下公式更新
- OAA 不断使用上述公式融合,AF 的操作其实是 element-wise maximum operation,即取两个矩阵所以位置最大的激活值
OAA 的 OAA + 如何训练?
![OAA-20230408143314]()
- OAA 的缺点在于有些目标区域的 attention values 很低,不足以被分类模型加强,对于这种情况,我们提出一个新的 loss 函数,把 cumulative attention maps 作为监督信息,去训练一个 attention module 以进一步改善 OAA,我们称之为 OAA+
- 具体来讲,我们将 cumulative attention maps 作为 soft labels。每个 attention value 被视作当前点属于目标类别的概率,去掉 GAP 和分类层,得到 integral attention model,将输入图像得到当前的 attention maps,cumulative attention maps 和 attention maps 计算多标签交叉熵损失