RAG 的 Indexing 优化之 ChunkOptimization
在构建索引前,通过对分块进行优化,构建更加有效的检索数据库,使用到的方法包括:small-to-big、提取关键词、元数据等
small-to-big
将用于检索的小块和用于生成的大块分开,通过先检索小块再参考大块来提升整体检索效果
使用 llm 提前生成问题、关键词
在生成 chunk 时,提前使用 llm 总结这个 chunk 的内容,并生成 1 个或多个问题,这些问题参与检索
在检索过程中,用户查询在语义上与模型生成的所有问题匹配。然后检索与用户查询类似的问题,然后将指向最相似问题的块传递给 LLM 以生成响应
注意:使用该方法依赖于 llm 的总结能力,并且当 llm 把实体替换为 "该平台、该 xxx" 时,检索会失效
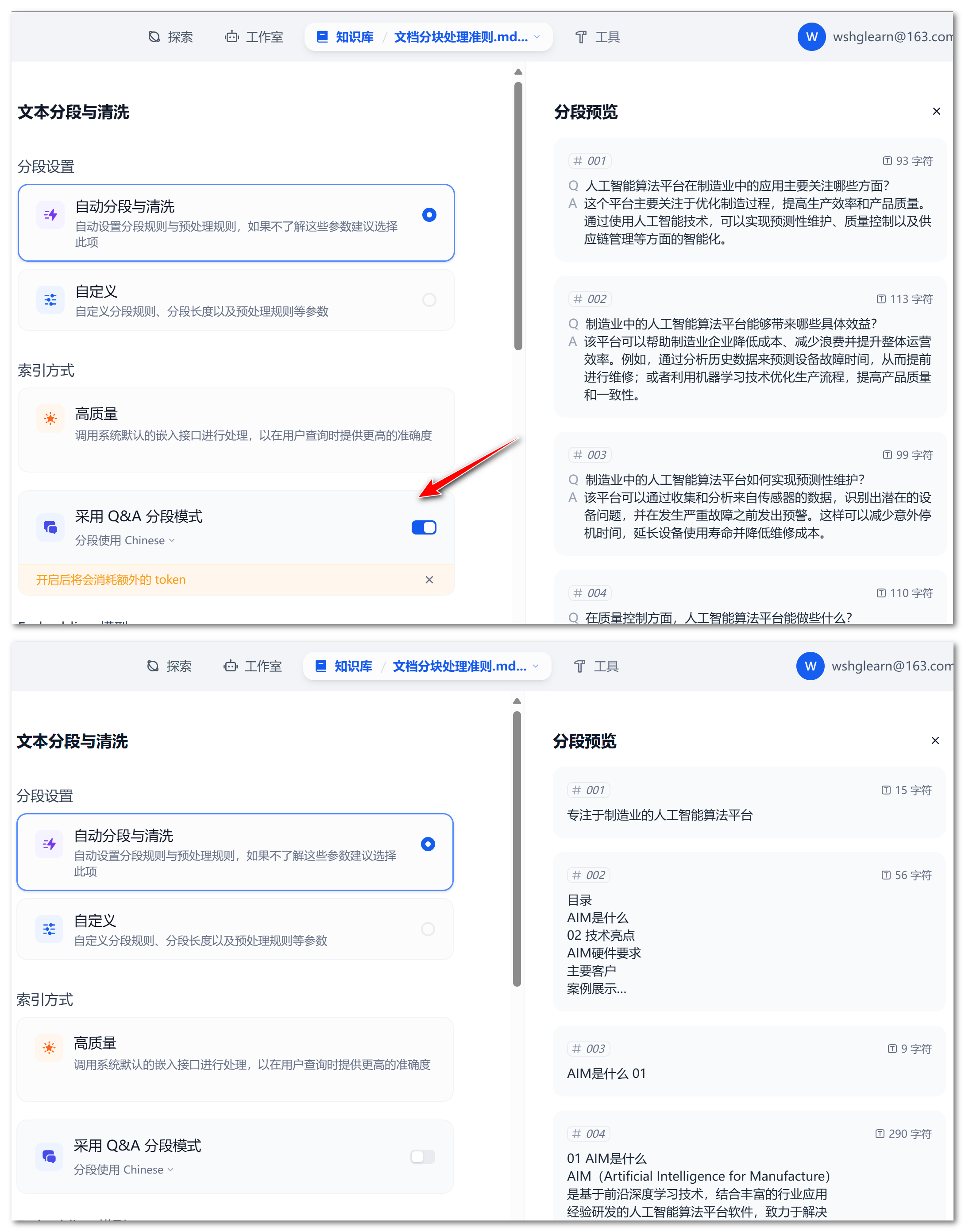
除了生成 chunk 的总结提问,还可以总结 chunk 内的实体,形成这个 chunk 的关键字
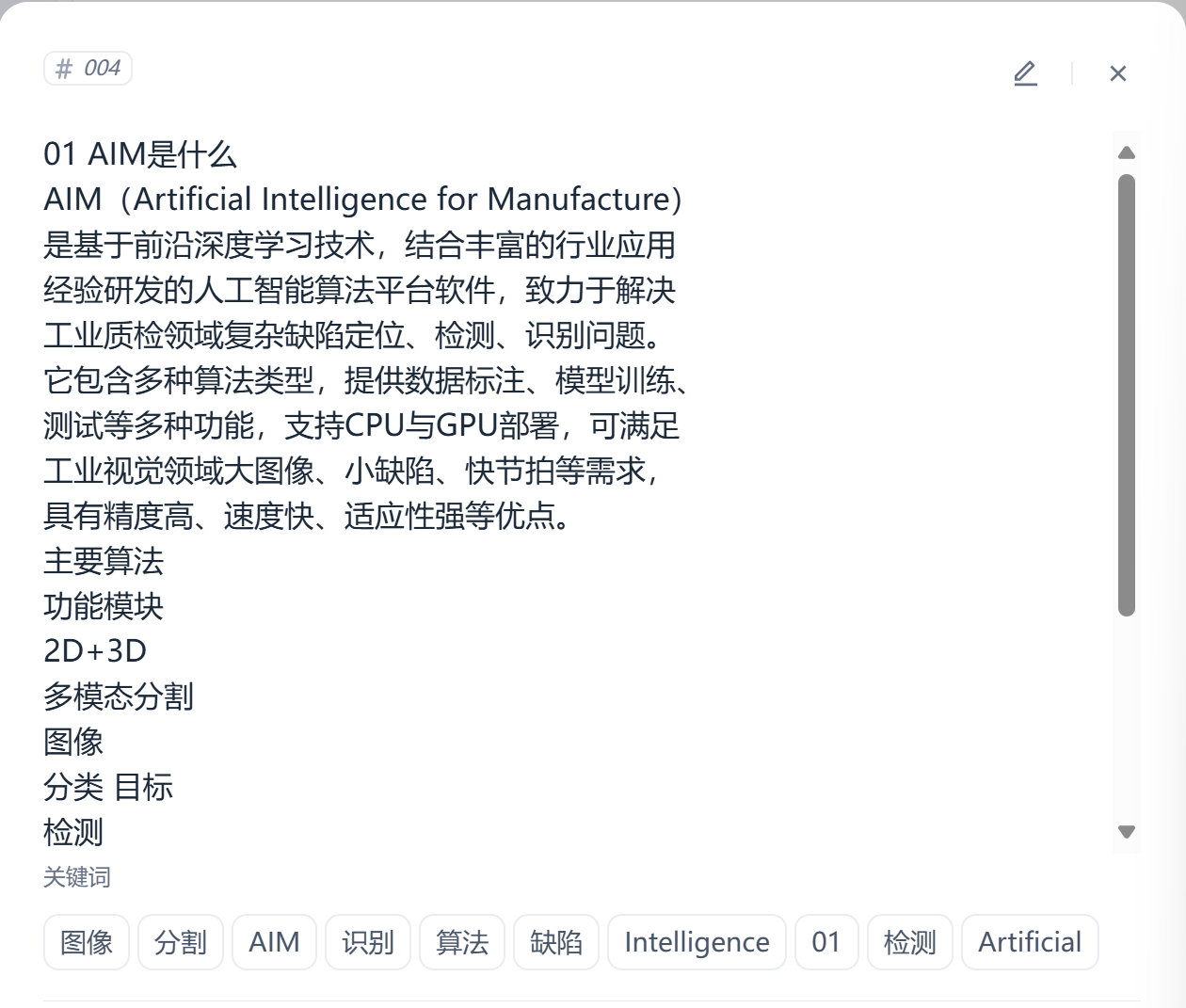
新增元数据
为文档新增元数据,有更多信息过滤文档,提高检索的准确性
