DALL-E-2:Hierarchical Text-Conditional Image Generation with CLIP Latents
本文是一个基于 CLIP 引导的 DDPM 生成模型
- (图片,文本)<->CLIP
- (图片编码)->DDPM-> 新的图像编码 (使用文本编码筛选)
- 新图像编码 ->VAE decoder-> 条件图片,文生图
什么是 DALL-E-2 ?
![]()
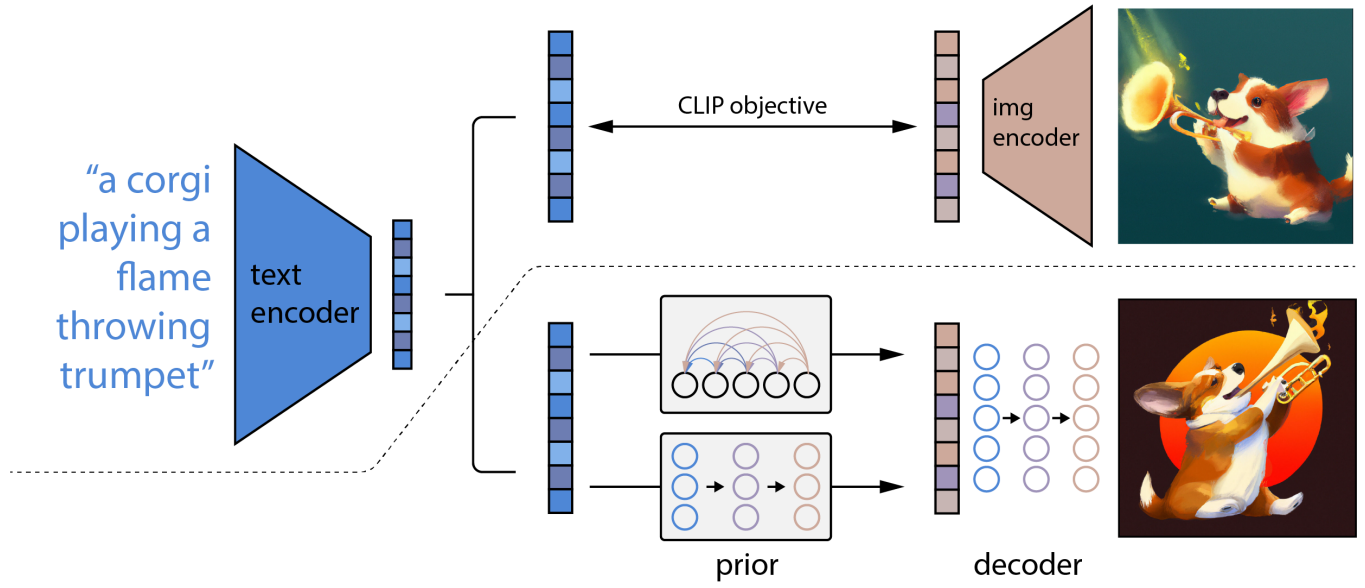
- DALL-E-2 提出一种 2 阶段的文生图模型,首先利用 CLIP 获取文本编码和图像编码,然后使用先验模型生成图片表示,最后通过编码器生成图像

DALL-E-2 的原理?
![]()
- 在虚线之上,我们描述了 CLIP 的训练过程,学习了一个文本和图像的联合表示空间。在虚线下面,我们描述了我们的文本到图像的生成过程:CLIP 文本嵌入首先被送入一个自回归或扩散先验以产生一个图像嵌入,然后这个嵌入被用来调节一个扩散解码器,生成图像
- 训练数据集是图像 和对应的文本描述 构成的数据对 。给定一张图像 ,经过 CLIP 模型, 表示图像向量, 表示文本向量
- 先验知识 :以本文描述 为约束,生成 CLIP 图像向量
- 解码器 :以 CLIP 图像向量 为约束,生成图像 ,其中,文本 是可选的输入
- 将两部分合并起来得
DALL-E-2 如何使用先验知识?
- 论文探索两种类型的先验模型:自回归先验和扩散先验,无论采样何种办法,prior 网络的目的是把 text encoder 输出的 embedding 转为 image encoder 的输出
- 自回归先验:将 CLIP 图像向量 转换为一个离散 code 序列,然后以文本 为约束,进行预测,为了更有效地从自回归先验中训练和采样,对 应用主成分分析 PCA 进行降维处理
- 扩散先验:使用高斯扩散模型直接建模连续向量 ,训练了一个仅解码器的 Transformer 模型。在采样时(时间步长为 T ),生成两个图像样本 ,选择与 有着更高点积的图像样本
DALL-E-2 的解码器?
![]()
- 解码器是一个扩散模型,本文使用使用 classifier-free guidance,通过对 10% 的时间序列随机设置 CLIP 向量为 0 或是可学习的向量为 0,以及随机失活 50% 的文本信息
- 为了生成高分辨率图像,作者训练了两个扩散上采样模块,一个用于将 64x64 分辨率上采样到 256x256,另一个进一步将 256x256 分辨率上采样到 1024x1024
DALL-E-2 如何基于图像 Latent Featrue 进行图像操控?
- 有了 decoder 了,其实就可以从 image embedding 来获得一张图,不管这个 是怎么来的,是从 prior 来的,还是从 CLIP 直接编码来的,或者是两个不同的 插值得到的,都可以
- Variations:直接基于 CLIP 的 使用扩散编码器生成图像,可见还保留图片主要内容,改变其他信息比如形状、方向等
![]()
- Interpolations:对两张图像的 进行球面线性插值,可见其生成图像平滑过渡
![]()
- Text Diff:在两个相似文本 潜空间上进行球面线性插值,可见其生成的图片平滑过渡
![]()



DALL-E-2 的 CLIP Latent 空间概率性?
![]()
- 在 CLIP 判断出错的情况下,DALL・E 2 还是能够输出合理的图片,如下图所示,即使 Granny Smith 的概率低至 0.02% 而 iPod 高达 99.98%,还是能输出有绿苹果的图片

DALL-E-2 的图像生成?
![]()
- 训练完模型之后的图片生成可以有三种方式
- 1)Caption:注意到训练 decoder 的时候,用到了 classifier-free guidance,会以一定概率把 image embedding 置零,因此实际上在 sample 的时候,可以不用到 image embedding,直接输入 encode 后的 caption 作为 decoder condition 来出图,当然质量也会差一些,内容可能生成的不对
- 2)Text embedding:因为 CLIP 把 image 和 text 映射到相同的 latent space,所以可以用 CLIP 的 text embedding 来替代 image embedding
- 3)Image embedding:通过 CLIP 提取文本的 latent space,然后作为条件输入编码器生成图像

CLIP 输出特征的降维?
![]()
- 为了更有效地从自回归先验中训练和采样,对 应用主成分分析 PCA 进行降维处理

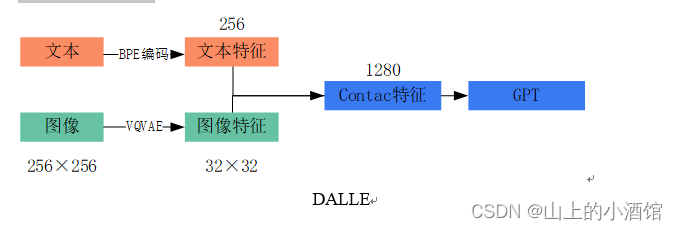
DALL-E-2 和 DALL-E 的区别?
![]()
- DALL-E:使用 BPE 编码文本信息,使用 VQVAE 编码图片信息,然后使用 GPT 自回归生成图片表示,最后使用 VQVAE 的解码器生成图像
- DALL-E-2:使用 CLIP 获取文本和图片的表示,然后使用 transformer 学习新的图片表示,最后使用 DDPM 的编码器还原图片
参考: