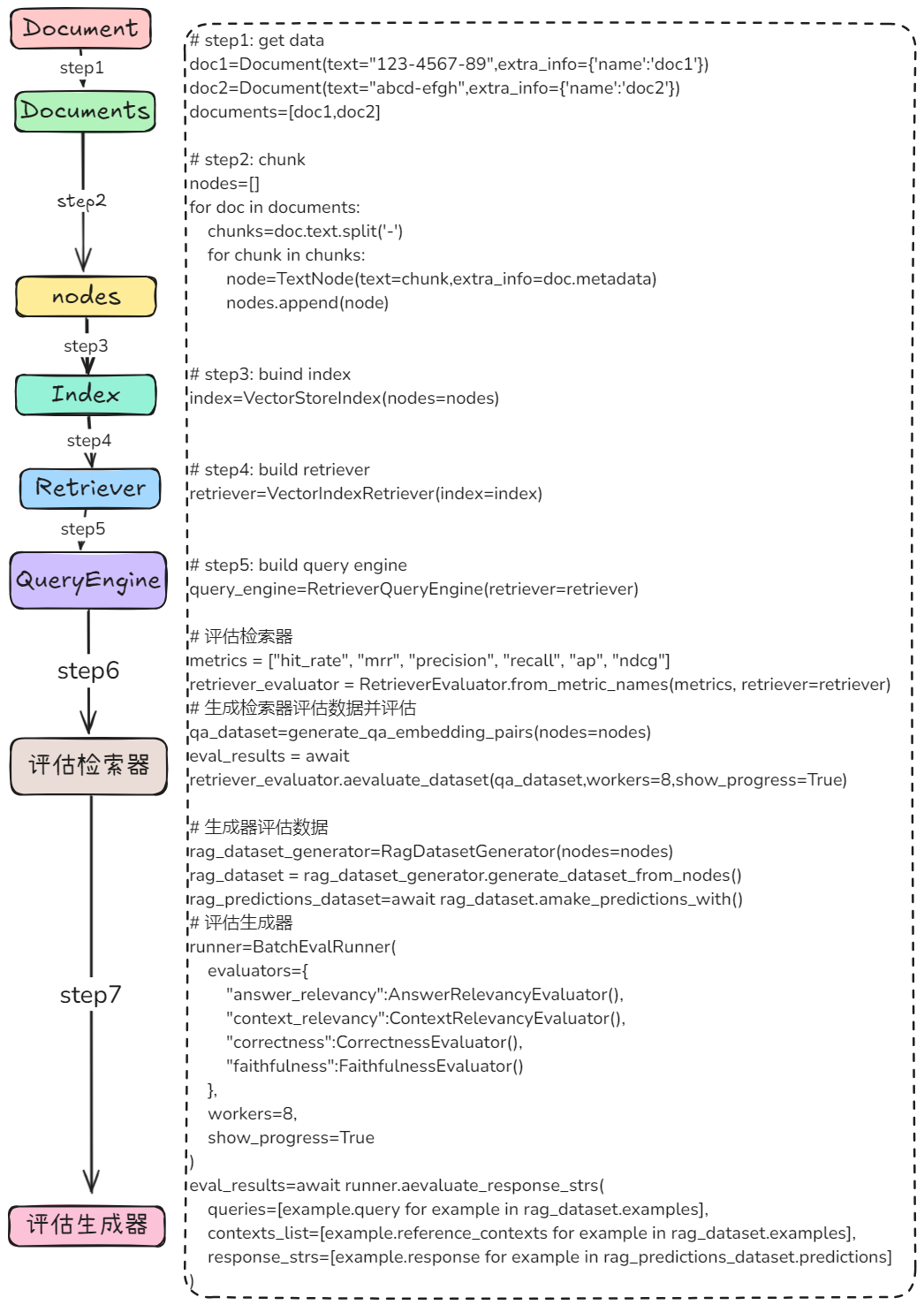
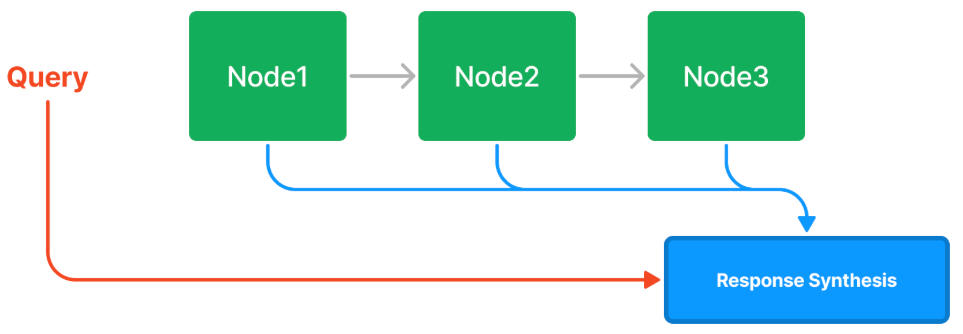
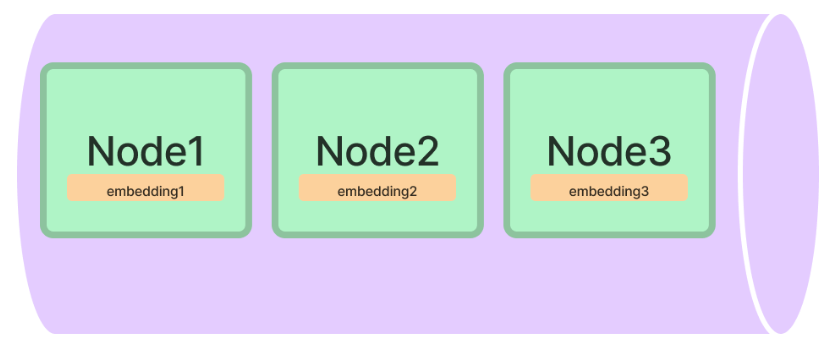
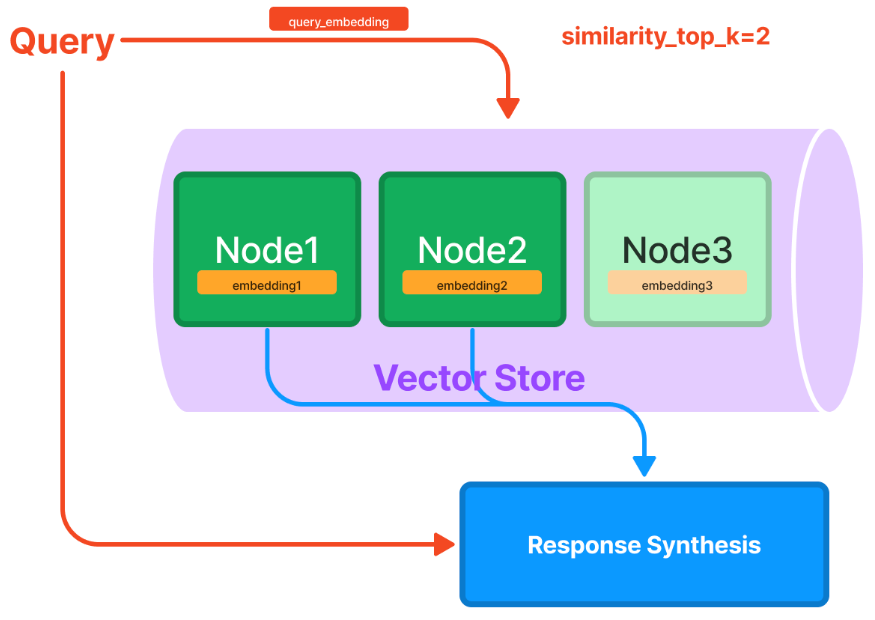
from llama_index.core import VectorStoreIndex from llama_index.core.extractors import ( TitleExtractor, QuestionsAnsweredExtractor, ) from llama_index.core.ingestion import IngestionPipeline from llama_index.core.node_parser import TokenTextSplitter
from llama_index.core.ingestion import IngestionPipeline pipeline = IngestionPipeline(transformations=transformations) nodes = pipeline.run(documents=documents)
1 2 3 4 5 6 7
{'page_label': '2', 'file_name': '10 k-132. Pdf', 'document_title': 'Uber Technologies, Inc. 2019 Annual Report: Revolutionizing Mobility and Logistics Across 69 Countries and 111 Million MAPCs with $65 Billion in Gross Bookings', 'questions_this_excerpt_can_answer': '\n\n 1. How many countries does Uber Technologies, Inc. Operate in?\n 2. What is the total number of MAPCs served by Uber Technologies, Inc.?\n 3. How much gross bookings did Uber Technologies, Inc. Generate in 2019?', 'prev_section_summary': "\n\nThe 2019 Annual Report provides an overview of the key topics and entities that have been important to the organization over the past year. These include financial performance, operational highlights, customer satisfaction, employee engagement, and sustainability initiatives. It also provides an overview of the organization's strategic objectives and goals for the upcoming year.", 'section_summary': '\nThis section discusses a global tech platform that serves multiple multi-trillion dollar markets with products leveraging core technology and infrastructure. It enables consumers and drivers to tap a button and get a ride or work. The platform has revolutionized personal mobility with ridesharing and is now leveraging its platform to redefine the massive meal delivery and logistics industries. The foundation of the platform is its massive network, leading technology, operational excellence, and product expertise.', 'excerpt_keywords': '\nRidesharing, Mobility, Meal Delivery, Logistics, Network, Technology, Operational Excellence, Product Expertise, Point A, Point B'}