多类和多输出算法
scikit-learn 如何完成多类和多输出算法?
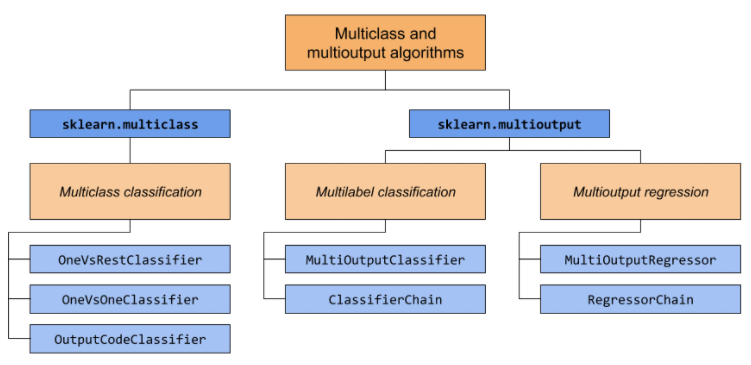
什么是多类分类?
- 多类分类是一个有两个以上类别的分类任务。每个样本只能被标记为一个类别
- 实现多类分类的方法有: OneVsRestClassifier 、OneVsOneClassifier
- 输出标签格式
1
2
3
4
5# 4个样本,分类为3个标签的一个
>>> import numpy as np
>>> y = np.array(['apple', 'pear', 'apple', 'orange'])
>>> print(y)
['apple' 'pear' 'apple' 'orange']
什么是 OneVsRestClassifier
- 在多类分类任务 (n 类) 中,为每个类别创建一个分类器,共计 n 个,这是最常见的多分类措施,原因是可解释性强
1
2
3
4
5
6
7
8
9
10
11
12>>> from sklearn import datasets
>>> from sklearn.multiclass import OneVsRestClassifier
>>> from sklearn.svm import LinearSVC
>>> X, y = datasets.load_iris(return_X_y=True)
>>> OneVsRestClassifier(LinearSVC(random_state=0)).fit(X, y).predict(X)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
什么是 OneVsOneClassifier?
- 在多类分类任务 (n 类) 中,为每对标签创建分类器,共计 n*(n+1)/2 个,预测是,按分类器最多票类别判定,票数相等,按分类置信度判定
1
2
3
4
5
6
7
8
9
10
11
12>>> from sklearn import datasets
>>> from sklearn.multiclass import OneVsOneClassifier
>>> from sklearn.svm import LinearSVC
>>> X, y = datasets.load_iris(return_X_y=True)
>>> OneVsOneClassifier(LinearSVC(random_state=0)).fit(X, y).predict(X)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 2, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
增加训练数据时, OneVsRestClassifier 和 OneVsOneClassifier 有什么不同?
- OneVsRestClassifier:需要更新所有的模型
- OneVsOneClassifier:根据数据,更新若干模型即可
scikit-learn 如何进行多标签分类 (MultiOutputClassifier)?
- 这可以被认为是对样本的属性进行预测,而这些属性并不是相互排斥的。从形式上看,每个样本的每个类别都有一个二进制输出。阳性类用 1 表示,阴性类用 0 或 - 1 表示。因此,它与运行 n_classes 二元分类任务相当,例如使用 MultiOutputClassifier。这种方法独立处理每个标签,而多标签分类器可以同时处理多个类,并考虑到它们之间的相关行为
- 输出标签格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31# 3个样本,每个样本4个标签
>>> y = np.array([[1, 0, 0, 1], [0, 0, 1, 1], [0, 0, 0, 0]])
>>> print(y)
[[1 0 0 1]
[0 0 1 1]
[0 0 0 0]]
>>> from sklearn.datasets import make_classification
>>> from sklearn.multioutput import MultiOutputClassifier
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.utils import shuffle
>>> import numpy as np
>>> X, y1 = make_classification(n_samples=10, n_features=100, n_informative=30, n_classes=3, random_state=1)
>>> y2 = shuffle(y1, random_state=1)
>>> y3 = shuffle(y1, random_state=2)
>>> Y = np.vstack((y1, y2, y3)).T
>>> n_samples, n_features = X.shape # 10,100
>>> n_outputs = Y.shape[1] # 3
>>> n_classes = 3
>>> forest = RandomForestClassifier(random_state=1)
>>> multi_target_forest = MultiOutputClassifier(forest, n_jobs=-1)
>>> multi_target_forest.fit(X, Y).predict(X)
array([[2, 2, 0],
[1, 2, 1],
[2, 1, 0],
[0, 0, 2],
[0, 2, 1],
[0, 0, 2],
[1, 1, 0],
[1, 1, 1],
[0, 0, 2],
[2, 0, 0]])
scikit-learn 如何进行多类多输出分类?
- 多类多输出分类(也称为多任务分类)是一项分类任务,它用一组非二进制属性来标记每个样本。属性的数量和每个属性的类的数量都大于 2。因此,一个估计器可以处理几个联合分类任务
- 标签输出格式
1
2
3
4
5
6# 多输出y的有效表示是一个密集的形状(n_samples, n_classes)的类标签矩阵
>>> y = np.array([['apple', 'green'], ['orange', 'orange'], ['pear', 'green']])
>>> print(y)
[['apple' 'green']
['orange' 'orange']
['pear' 'green']]
scikit-learn 如何进行多输出回归?
- 多输出回归对每个样本的多个数字属性进行预测。每个属性都是一个数字变量,每个样本要预测的属性数量大于或等于 2
- 多输出回归支持可以通过 MultiOutputRegressor 添加到任何回归器中。这种策略包括为每个目标拟合一个回归器。由于每个目标正好由一个回归器表示,因此有可能通过检查其相应的回归器来获得关于目标的知识
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15>>> from sklearn.datasets import make_regression
>>> from sklearn.multioutput import MultiOutputRegressor
>>> from sklearn.ensemble import GradientBoostingRegressor
>>> X, y = make_regression(n_samples=10, n_targets=3, random_state=1)
>>> MultiOutputRegressor(GradientBoostingRegressor(random_state=0)).fit(X, y).predict(X)
array([[-154.75474165, -147.03498585, -50.03812219],
[ 7.12165031, 5.12914884, -81.46081961],
[-187.8948621 , -100.44373091, 13.88978285],
[-141.62745778, 95.02891072, -191.48204257],
[ 97.03260883, 165.34867495, 139.52003279],
[ 123.92529176, 21.25719016, -7.84253 ],
[-122.25193977, -85.16443186, -107.12274212],
[ -30.170388 , -94.80956739, 12.16979946],
[ 140.72667194, 176.50941682, -17.50447799],
[ 149.37967282, -81.15699552, -5.72850319]])