RT-DETR
本论文 改进了 DETR 的网络结果,使用更加高效的特征融合网络及最小化不确定查询变量,实现更快更高效的目标检测
什么是 RT-DETR ?
![]()
- 基于 DETR 提出的更加高效的目标检测模型,通过在高效的特征混合模块抽取图片初始特征,通过 "不确定性最小查询" 确定解码器输入,最后通过匈牙利对齐标签计算损失
- DETR 的好处是去掉 NMS,但是其解码器输入时随机初始化的,其训练过程比较慢,而 RT-DETR 继承了去掉 NMS 的优点,并在此基础上,通过最小化不确定查询,采样一部分编码器输出作为解码器输入,实现了预测框的高置信度
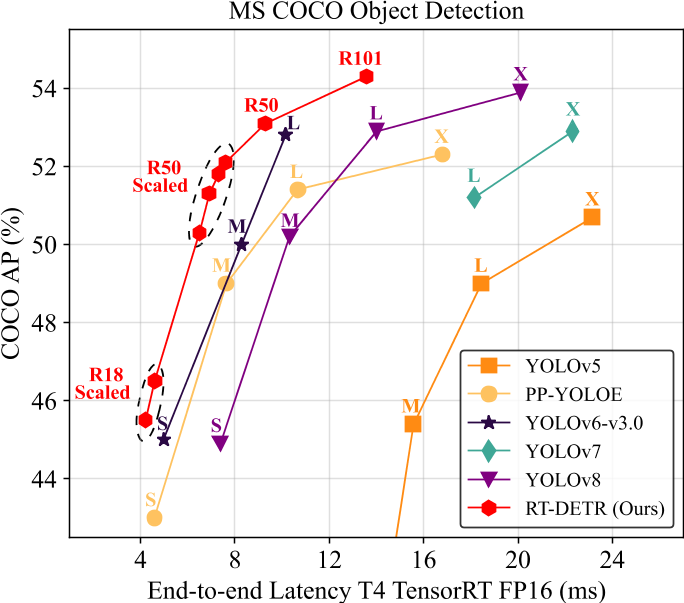
NMS 是如何影响目标检测的精度及准确率的?
![]()
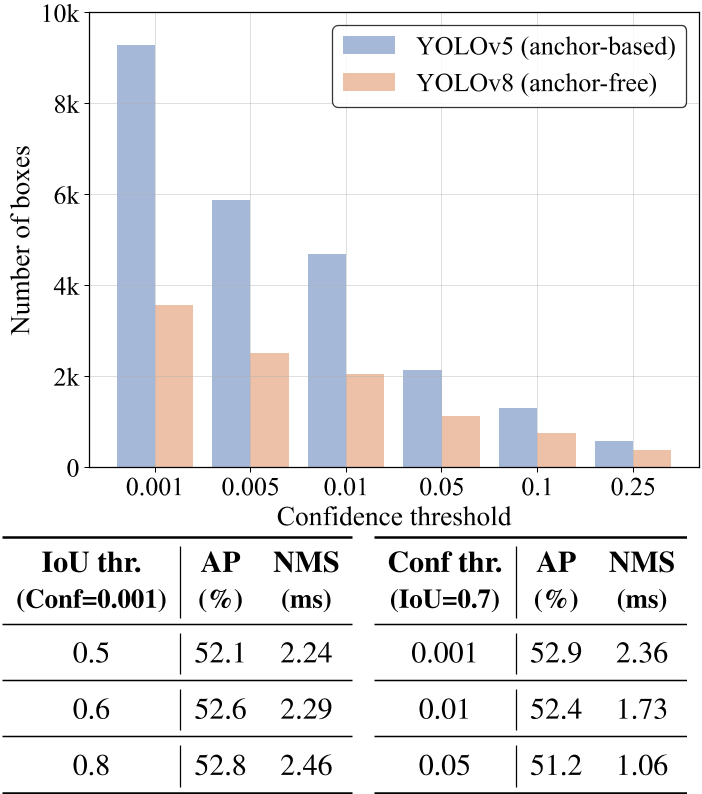
- 图 1 是 Anchor-base 的 YOLOv 5 与 anchor-free 的 YOLOv 8 在不同置信度阈值下,还剩不同数量的 box 等待 nms,可知其数量是非常大的
- 图 2 是使用不同置信度及 IOU 阈值执行 nms 时,其耗时情况
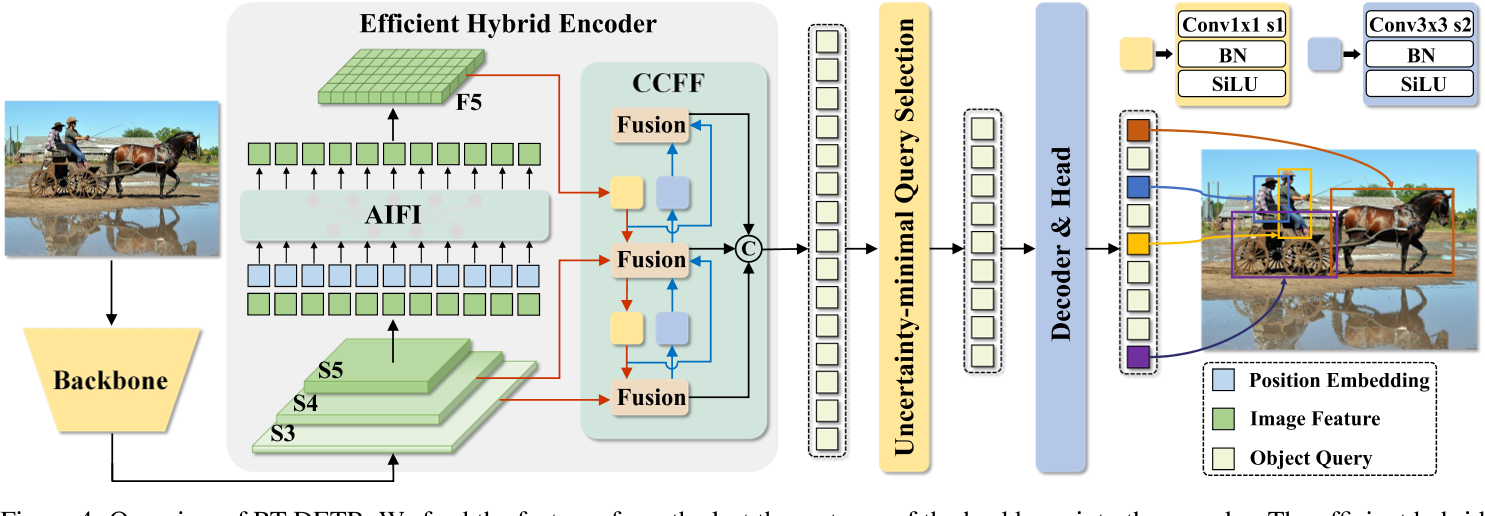
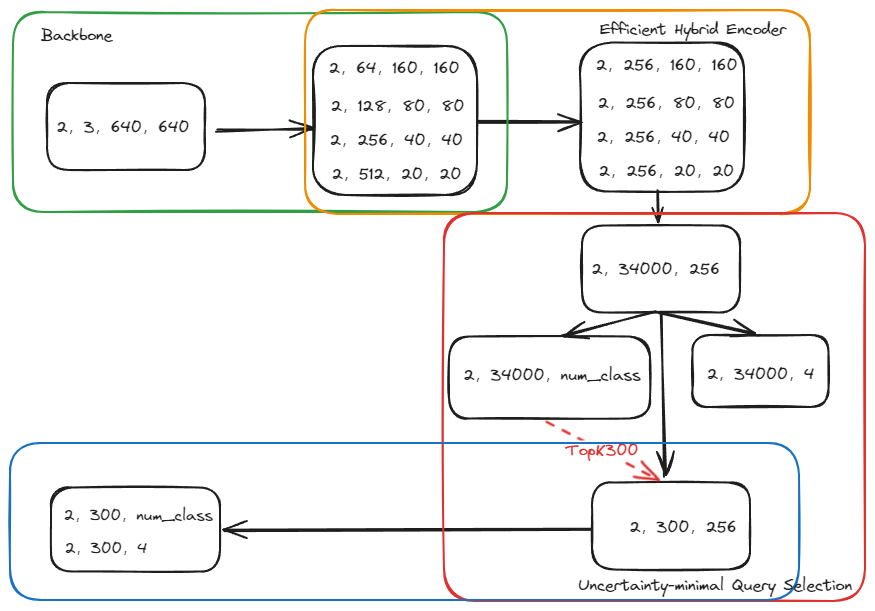
RT-DETR 的网络结构?
![]()
![Drawing-20240529142916.excalidraw]()
- Backbone:主干网络,用于提取 S 3 级别的特征
- Efficient Hybrid Encoder:高效的特征混合网络,其中 AIFI 是 transformer 设计的图 crop 学习模块,CCFF 是特征混合模块
- Uncertainty-minimal Query Selection:最小化不确定性查询
- Decoder & head:解码器
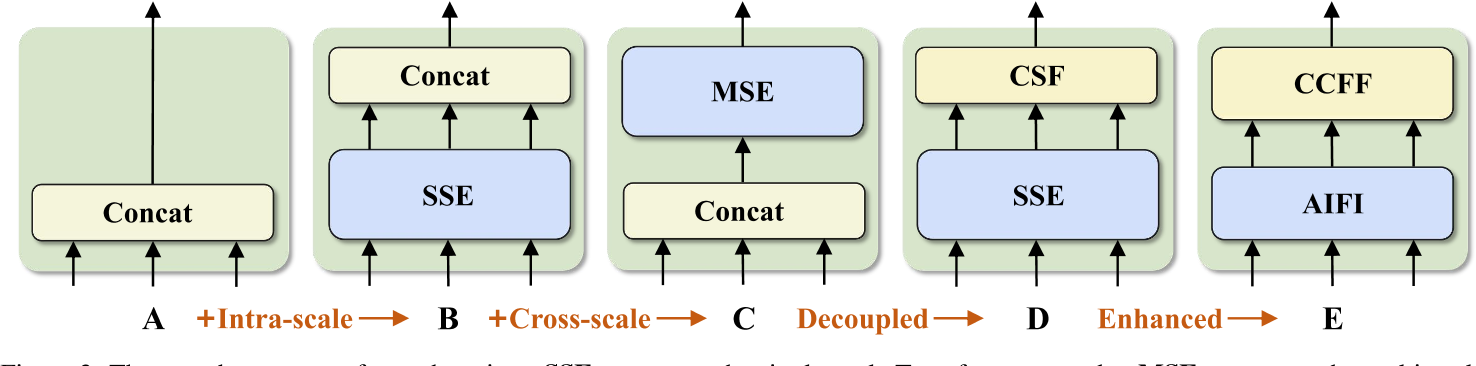
RT-DETR 的高效特征混合编码器?
![]()
![]()
- A:原始的特征融合,直接 Concat
- B:单尺度的 transformer encoder
- C:多尺度的 transformer encoder
- D:单尺度的 transformer encoder + 跨尺度的特征融合
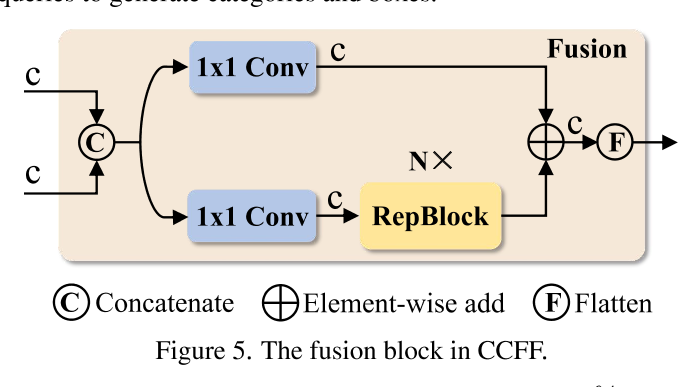
- E:优化 D 得到,其中 CCCF 借鉴 RepVGG 使用 N 个 RepBlock 实现,
RT-DETR 的最小化不确定查询选择? ^vrehjv
![Drawing-20240529142916.excalidraw]()
- 原始 DETR 直接随机 N 个查询变量进解码器,配合编码器的输出,得到最终结果,由于查询变量是在训练中学习,导致训练不稳定,效率低下
- RT-DETR 先将编码器的输出解析为预测结果,然后从其中取出预测概率最大的前 N 个作为解码器的查询变量
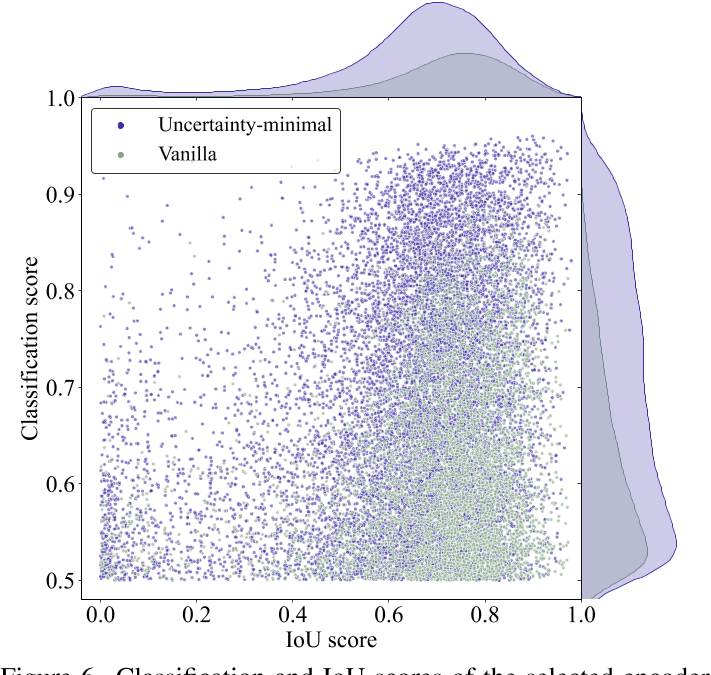
RT-DETR 的如何做样本对齐?
![]()
- RT-DETR 和 DETR 的样本分配一样,均是采样 “二部图” 的思想
- 由于 RT-DETR 采样了最小化不确定查询选择的策略,可以看出其预测的 box 集中在高 classfication score 和 IoU score
RT-DETR 的损失函数?
- RT-DETR 使用了三部分损失进行训练,(1)直接损失:类别损失及位置损失,分别使用交叉熵及 GIOU loss(2)辅助损失 aux_loss;(3) 辅助损失 dn_aux_loss,其中辅助损失用于加速收敛