深度学习的正则化操作
在训练神经网络时,以使神经某些神经元失活的方式增强模型的泛化能力,还要掌握 Dropout 在训练时和推理时的差异
什么是正则化 (regularization)?
- 常见的正则化有 L1 正则化、 L2 正则化、 丢弃正则化 (Dropout) ,其中 L1 正则化倾向稀疏权重 (减少参数)、L2 正则倾向缩小权重 (减小参数)、Dropout 倾向减小神经元之间共适应性,相当于在原来模型基础上加入先验信息,也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度
什么是丢弃正则化 (Dropout)?
![]()
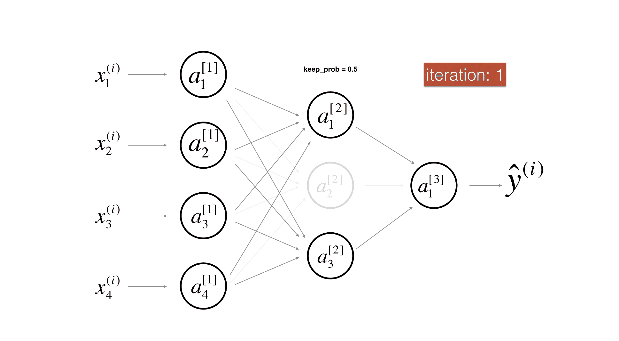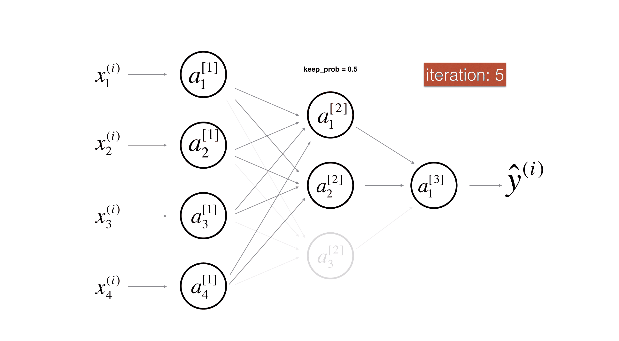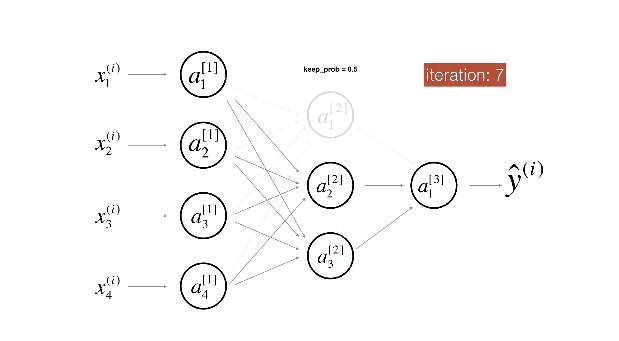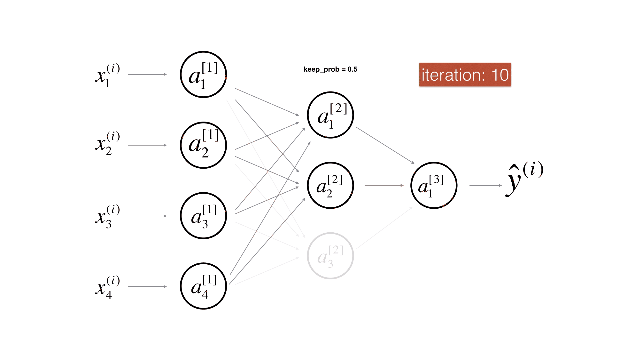
- 丢弃正则化 (Dropout) 旨在防止神经网络中单元 “共同适应” 的方法。换句话说,我们希望神经元独立地从其输入中提取特征,而不是依赖其他神经元来这样做
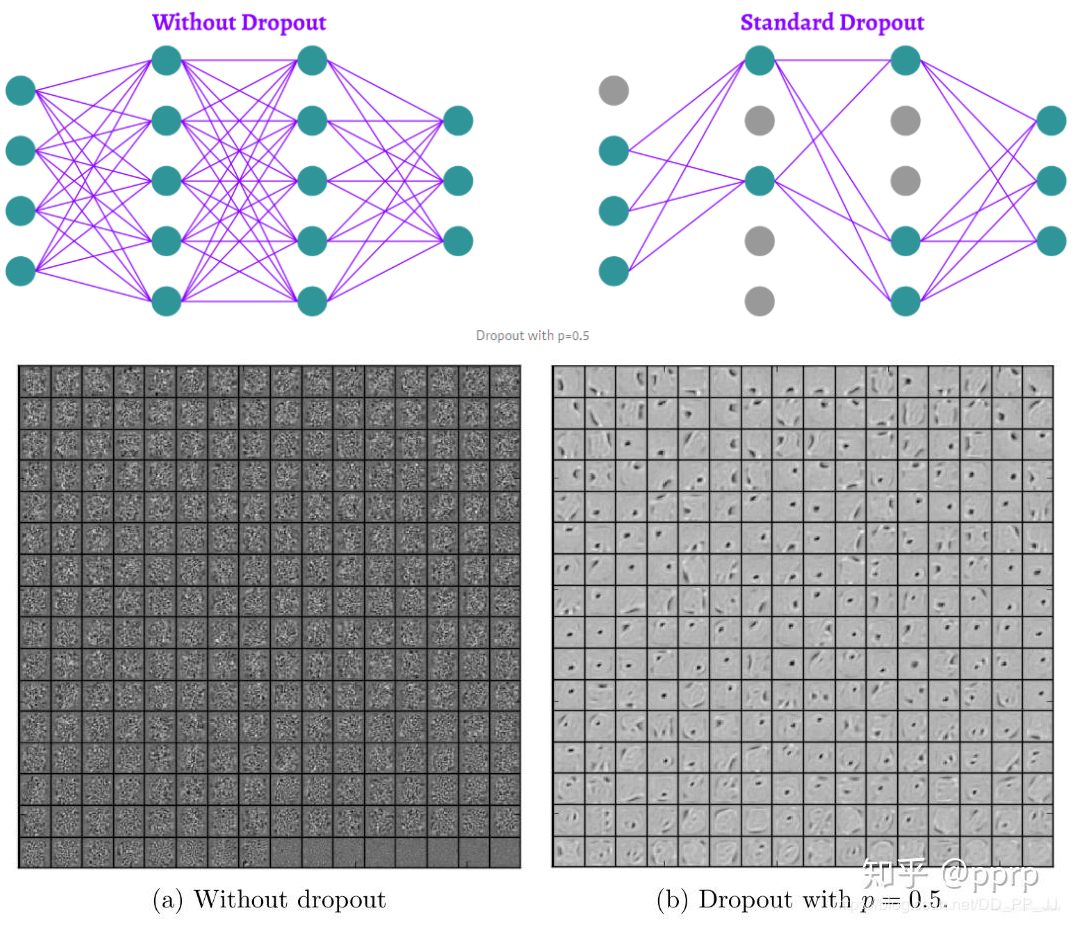
- 上图是在 MNIST 数据集上进行的 Dropout 实验,可以看到 Dropout 可以破坏隐藏层单元之间的协同适应性,使得在使用 Dropout 后的神经网络提取的特征更加明确,增加了模型的泛化能力
dropout 的原理?
![]()
- 训练过程:Dropout 的实现是让神经元以超参数 p 的概率停止工作或者激活被置为 0,可以被认为是对完整的神经网络的一些子集进行训练,每次基于输入数据只更新子网络的参数
- 测试过程:不进行随机失活,而是将 Dropout 的参数 p 乘以输出
- 训练时的删除,即指定该该隐单元的输出都为 0,如下公式,x 是层输入,W 是权重矩阵,y 是层输出,m 是层 dropout 掩码,遵从概率为 P 的伯努利分布 (bernoulli),测试时没有 dropout。所有的神经元都是活跃的。为了补偿与训练阶段相比较的额外信息,我们用出现的概率来衡加权权重
Dropout 如何进行反方向传播?
正向传播: 考虑一个输入向量 x , 经丢弃概率为 p 的 dropout 函数变换后得到向量 d, 往前 forward 传播得到误差值 error (标量 e), 求在训练过程中 e 对 x 的梯度
反向传播
梯度向量
Dropout 应用到全连接层?
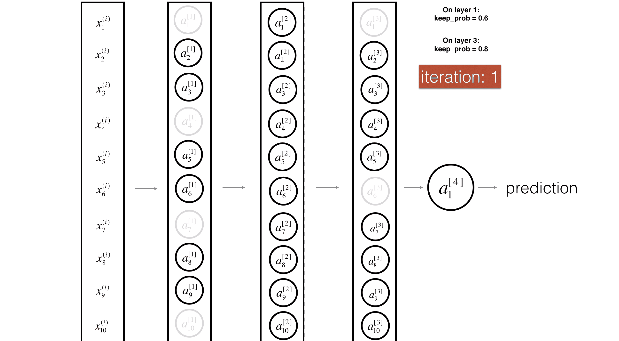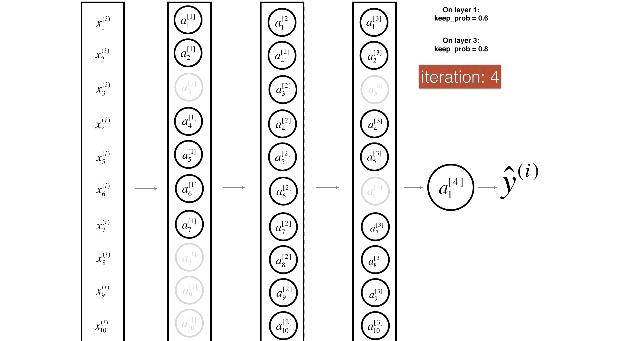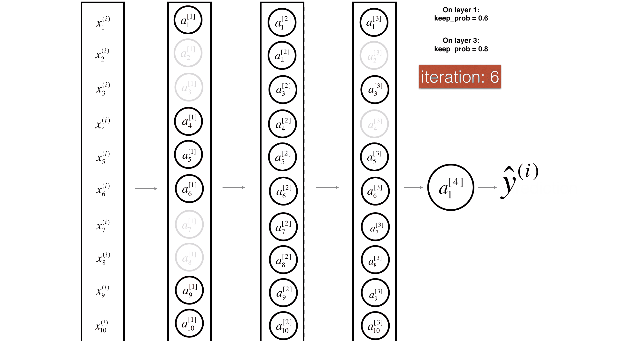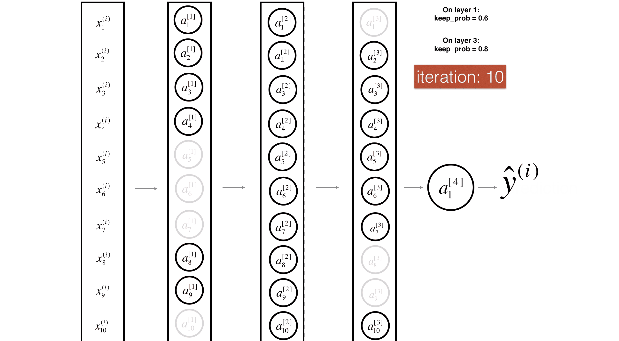
Dropout 应用到卷积层?
![]()
- 卷积神经网络 (CNNs) 的朴素 dropout 定义为特征图或输入图像中随机丢弃像素,并没有显著减少过拟合,主要是因为被丢弃像素的相邻像素具有高度相关性,DropBlock 正则化、Cutout 可应用于卷积神经网络
- 一般很少用普通的 Dropout 来处理卷积层,这样效果往往不会很理想,原因可能是卷积层的激活是空间上关联的,使用 Dropout 以后信息仍然能够通过卷积网络传输
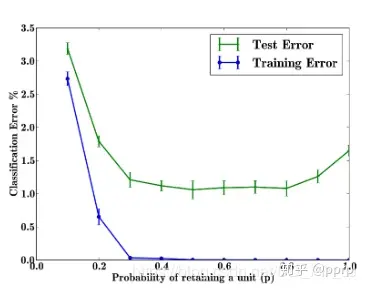
dropout 率的选择?
![]()
- 以上实验是对 MNIST 数据集进行的实验,随着 p 的增加,测试误差先降后升,p 在 [0.4, 0.8] 之间的时候效果最好,通常 p 默认值会被设为 0.5,如果希望在 input 层的添加噪声,可设置为 0.8
- 对参数 w 的训练进行球形限制 (max-normalization),对 dropout 的训练非常有用, 球形半径 c 是一个需要调整的参数,可以使用验证集进行参数调优
为什么不推荐同时在神经网络中使用 Dropout 和 BN?
![]()
- 当丢弃正则化 (Dropout) 和 批规范化 (Batch Normalization,BN) 结合在一起时并不能获得额外的增益。事实上,当一个网络同时使用这两者时,甚至会得到更差的结果
- BN 在某些情况下会削弱 Dropout 的效果。他们揭露了两者之间的不相容性,从而推测 BN 提供了与 Dropout 相似的正则化功能。很多现代模型 如 Resnet,Densenet 等为这一观点添加佐证,它们在只使用 BN 的情况下得到更好的结果
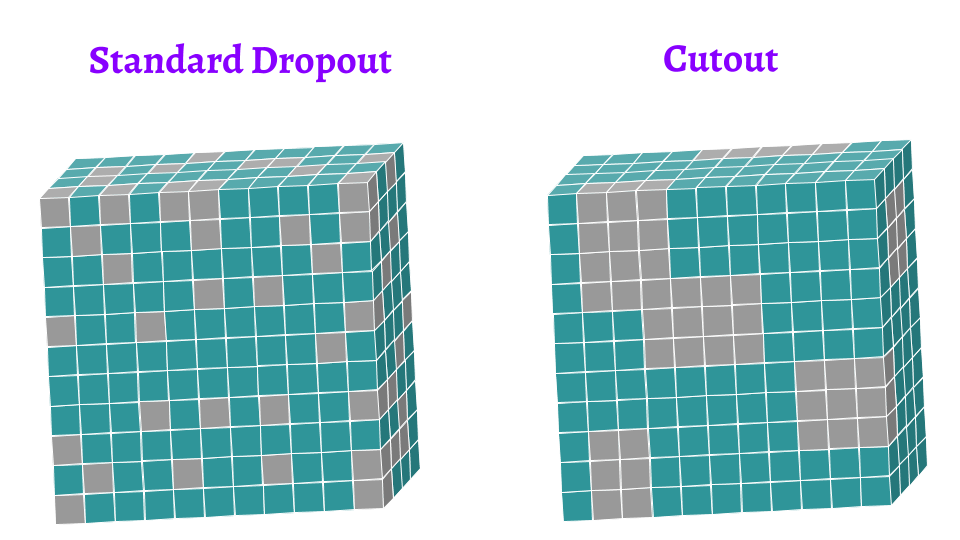
Dropout 与 Cutout 数据增强的区别?
![]()
- dropout 随机丢弃每个像素,Cutout 可以通过对图像的隐藏区域进行泛化从而限制过拟合
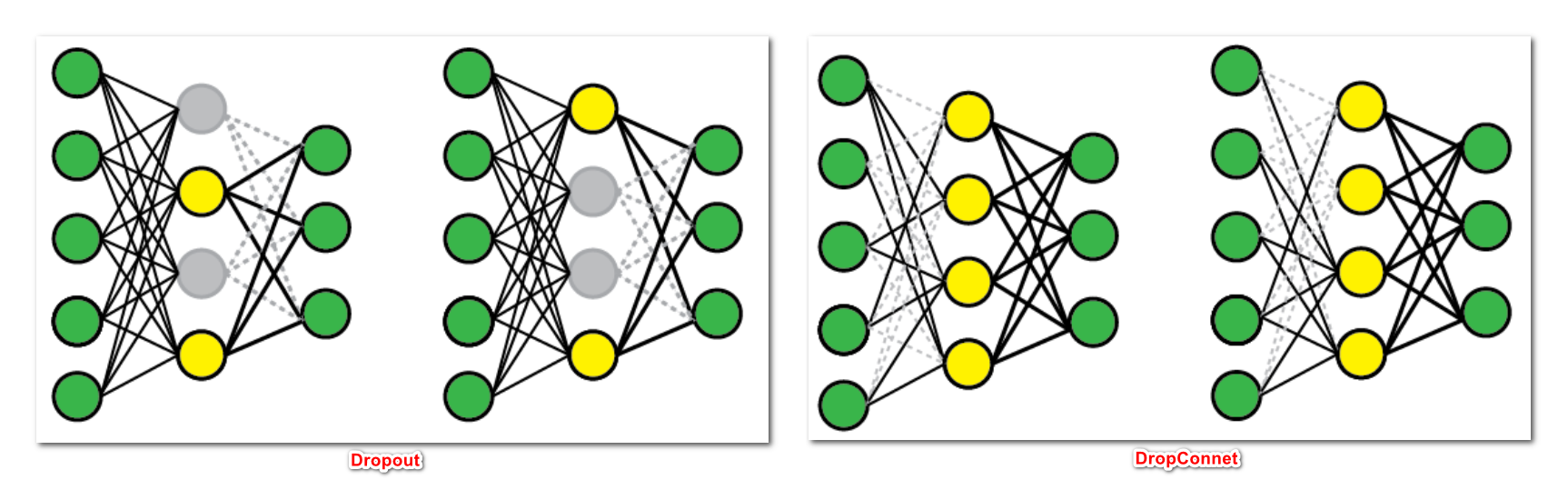
什么是 DropConnect?
![]()
dropout 最早变种之一,它将神经元的权重和偏差以一定概率设置为 0,而不是将神经元输出设置为 0,其训练时的计算公式为,其中 M 是掩码矩阵,测试阶段使用与标准 Dropout 方法相同的逻辑。输出乘以出现的概率
DropConnect 是标准 Dropout 的泛化,因为它产生了更多可能的模型,因为几乎权重总是连接多于单元
注意: 和 dropout 一样,DropConnect 只能用于全连接的网络层
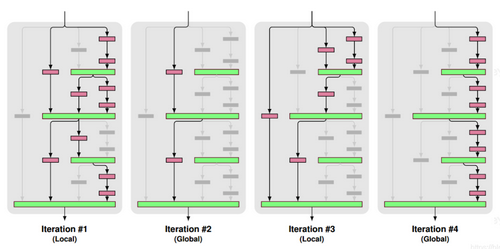
什么是 DropPath?
![]()
- 将深度学习模型中的多分支结构随机失活的一种正则化策略
- 局部丢弃,以一定的概率随机丢弃 Join 层,但必须保证起码有一条分支是通的
- 全局丢弃,随机选择一条分支
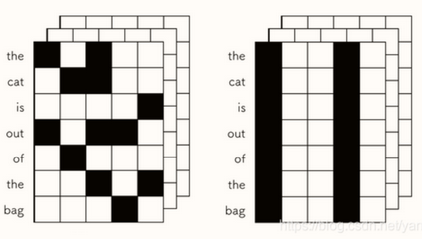
什么是 Spatial DropOut?
![]()
- 普通的 Dropout 会将部分元素失活,而 Spatial Dropout 则是随机将部分区域失失活,简单理解就是通道随机失活。一般很少用普通的 Dropout 来处理卷积层,这样效果往往不会很理想,原因可能是卷积层的激活是空间上关联的,使用 Dropout 以后信息仍然能够通过卷积网络传输。而 Spatial Dropout 直接随机选取 feature map 中的 channel 进行 dropout,可以让 channel 之间减少互相的依赖关系
- Spatial Dropout 常用于 NLP 中(Embedding 中)
什么是 Cutout 数据增强?
![]()
- Cutout 的出发点和 Random Erasing 一样,也是模拟遮挡,目的是提高泛化能力,实际上比 Random Erasing 简单,随机选择一个固定大小的正方形区域,然后采用全 0 填充
- Cutout 区域的大小比形状重要,所以 Cutout 只要是正方形就行。具体操作是利用固定大小的矩形对图像进行遮挡,在矩形范围内,所有的值都被设置为 0,或者其他纯色值,而且擦除矩形区域存在一定概率不完全在原图像中(文中设置为 50%)
- Cutout 可以理解为 Dropout 的一种扩展操作,不同的是 Dropout 是对图像经过网络后生成的特征进行遮挡,而 Cutout 是直接对输入的图像进行遮挡,相对于 Dropout,Cutout 对噪声的鲁棒性更好

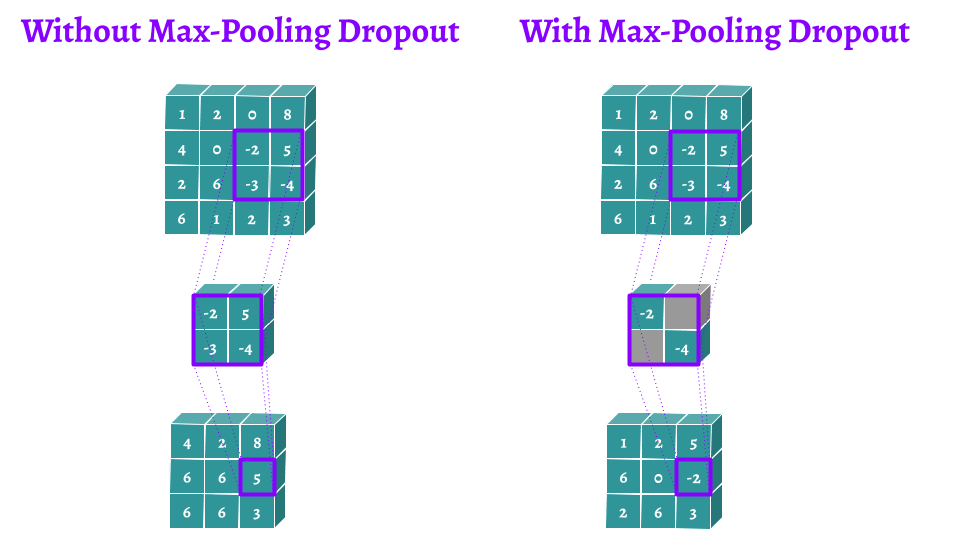
什么是 DropBlock?
![]()
- Dropout 对卷积层的效果没那么好(图 (b))。文章认为是由于每个 feature map 中的点都对应一个感受野范围,仅仅对单个像素位置进行 Dropout 并不能降低 feature map 学习的特征范围,网络依然可以通过失活位置相邻元素学习对应的语义信息
- DropBlock 有三个重要的参数:1)block size 控制 block 的大小;2)γ 控制有多少个 channel 要进行 DropBlock;3)keep prob 类别 Dropout 中的 p,以一定的概率失活
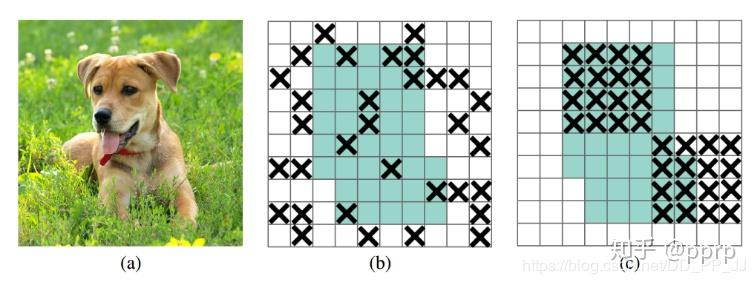
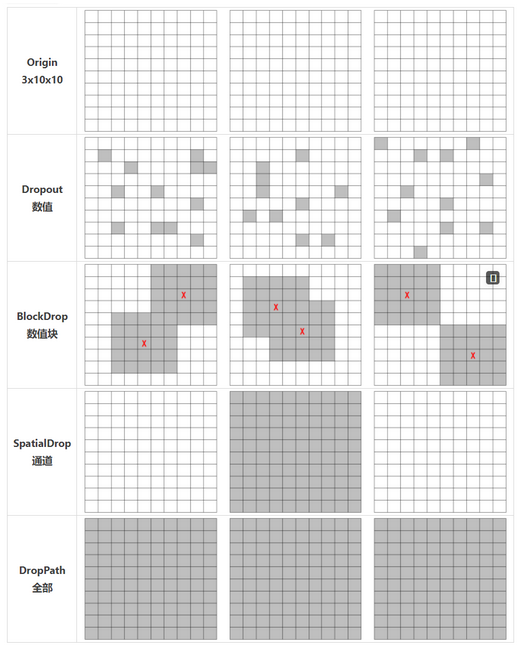
Dropout、DropBlock、SpatialDrop、DropPath 的联系?
![]()
- DropOut:对 NCHW 中所有的特征进行随机失活,以像素为单位,用在全连接层较多,在卷积层基本不用(BN 代替)
- DropBlock:随机对 进行失活,用在卷积层,效果很好,比如 YOLOv4
- Spatial Dropout:随机将 CHW 的特征进行随机失活,以 channel 为单位,常用在 NLP 的 Embedding 中
- DropPath:随机跳过一个 Res Block, 单位更大,用在 Block 支路比较多的模型中
- DropConnect:让 Weight 随机失活,而不是 unit
参考: