SENet:Squeeze-and-Excitation Networks
通过在 ResNet 中引入通道注意力机制,实现对通道的动态学习加权
什么是 SENet?
![SENet-20230408141113]()
- 构建 SEBlock 对通道信息进行加权,相当于引入注意力机制 (Attension),把重要通道的特征强化,非重要通道的特征弱化
SENet 的网络结构?
![SENet-20230408141114]()
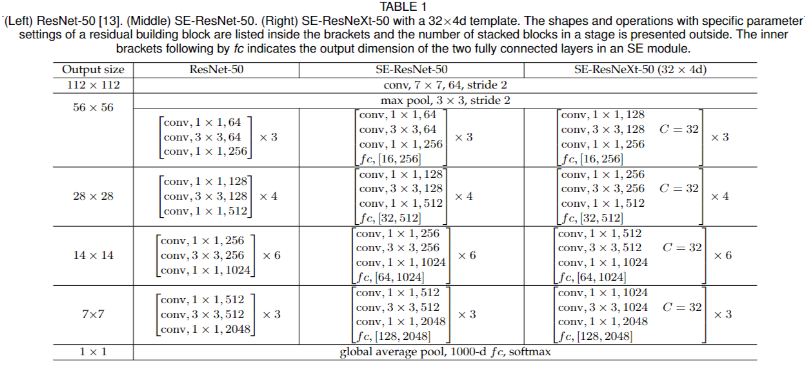
- 在 ResNet 上加入 SE Block 即可
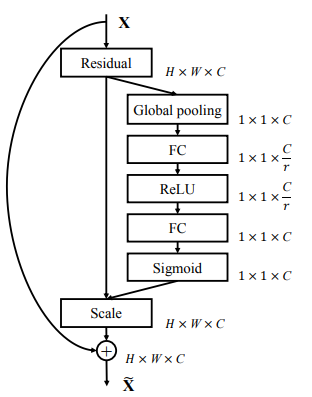
SENet 的 SEBlock 模块?
![SENet-20230408141115]()
![]()
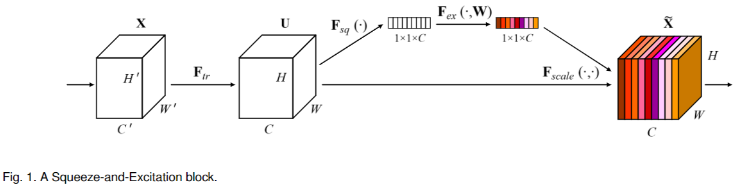
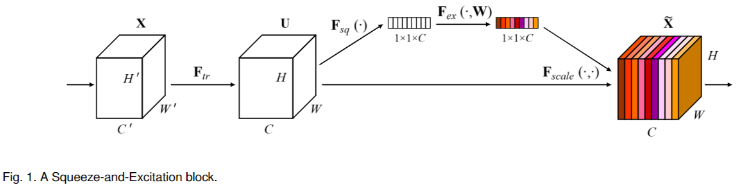
- 简称 SE 模块,U 矩阵 (HWC) 作为输入,生成对 U 矩阵各个通道的加权矩阵 (1x 1 xC ),然后原始特征与加权矩阵相乘得到加权后的特征
- SE 模块主要由挤压部分 (Squeeze) 和激活部分 (Excitation) 实现,其中 Squeeze 部分负责编码全局信息,Excitation 部分负责自适应激活
- Squeeze:使全局平均池化处理 U,输入 (H, W, C),输出 (1x1xC)
- Excitation,Squeeze 后得到各个通道的最大响应值矩阵 (1 x 1 xC),首先经过两层 fc 提取这个矩阵的特征,最后通过 sigmoid 生成通道的加权矩阵 (1 x 1 xC)。图中 r 是指压缩的比例,作为输入矩阵各个通道的 scale 值
为什么提出 SENet?
标准卷积本质是局部区域在空间及通道之间进行特征融合,为了提升卷积的特征质量,通常通过扩感受野 (receptive field) 或 融合空间多种特征实现,比 VGGNet 加深网络扩大感受野 GoogleNetv1 融合多个卷积的结果,以上基本是针对空间层面的改进
卷积对通道的关注只是简单融合,SENet 则通过关注通道之间的重要性,实现卷积对不同特征重要性的区分
神经网络不能自动学习到各个通道的重要性吗?为什么 SENet 要改变网络去做?
- 神经网络确实可以自动学习特征,也能区分各通道的重要性,但是 SENet 学习到的重要性可能更准确,因为 SENet 显式加入约束,就比喻 “为什么加正则化 (regularization) 的网络会比不加正则化的网络优秀” 一样
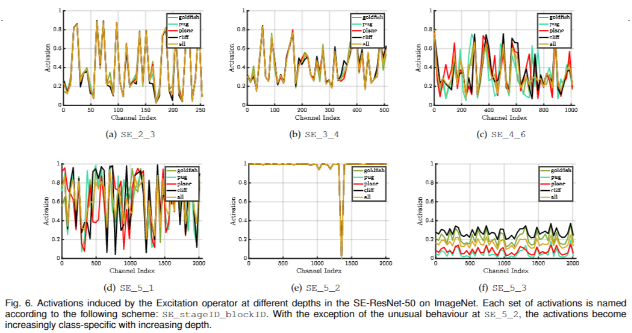
SENet 不同压缩比例的 SE Block 对结果的影响?
![SENet-20230408141116]()
- 靠前的层级(SE_2_3 和 SE_3_4):各个分类的曲线差异不大,这说明了在较低的层级中 scale 的分布和输入的类别无关;
- 靠后的层级(SE_4_6 和 SE_5_1):不同类别的曲线开始出现了差别,这说明靠后的层级的 scale 大小和输入的类别强相关;
- 到了 SE_5_2 后几乎所有的 scale 都饱和,输出为 1,只有一个通道为 0;而最后一层 SE_5_3 的通道的 scale 基本相同。最后两层的 scale 因为基本都相等,就没有什么用处了,为了节省计算量可以把它们去掉