SegNet:A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
SegNet 是典型的 encoder-decoder 语义分割网络,通过反池化进行上采样
什么是 SegNet?
![SegNet-20230408143607]()
- 基于编码器 - 解码器的语义分割网络,主要思想:使用编码器期池化 (Pooling) 的索引,通反池化 (UnPooling) 还原图像信息,并实现像素级分类
- 虽然 SegNet 没有完全领先 FCN、DeepLab、DeconvNet,但是精度和速度的平衡的条件下是更好的选择
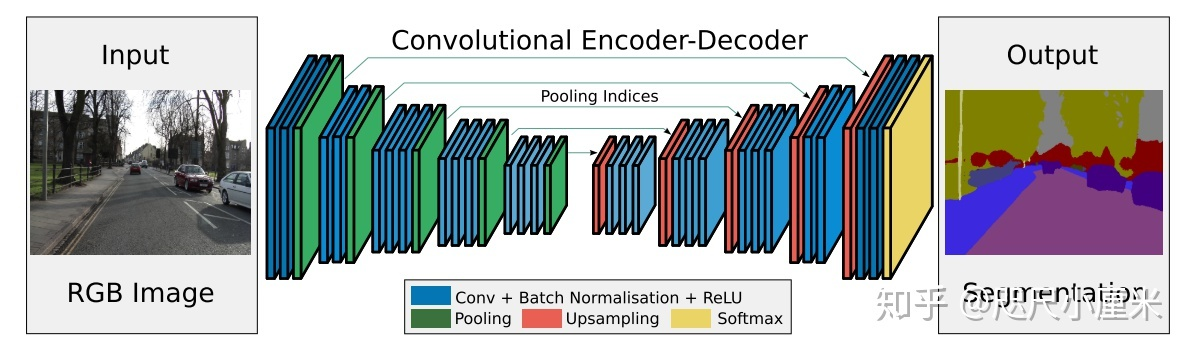
SegNet 的网络结构?
![SegNet-20230408143608]()
- 网络的输入 H* W* 3,输出是 H * W * C,C 为类别数量
- 编码器 (Encoder): VGG -16 有 13 个卷积层(除去全连接层)
- 解码器 (Decoder): 对应 decoder 也具有 13 层,其中 upsampling 使用 Encoder 期间 pooling 的位置索引,最后用 Softmax 做像素分类
SegNet 的损失函数?
- 输入标签的 h * w,分割后得到的输出是 h * w * C,其中 C 为每个像素的类别概率
- 将 h* w 拉成一维,如果网络输出包括 softmax,使交叉熵损失 (CrossEntropyLoss) 计算损失
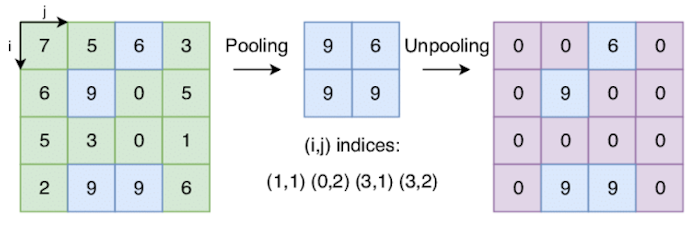
SegNet 的最大池化索引 (max-pooling indices)?
![SegNet-20230408143609]()
- 在 Encoder 阶段,保存每个 2x2 区域中最大特征的索引。考虑到整个网络是对称的,所以在解码器阶段的上采样期间,1x1 特征会到达相应池化索引显示的确切位置
- 作用:改善了边界划分,使边界轮廓更准确,减少了端到端训练的参数量,进而减少内存占用,提高推理速度
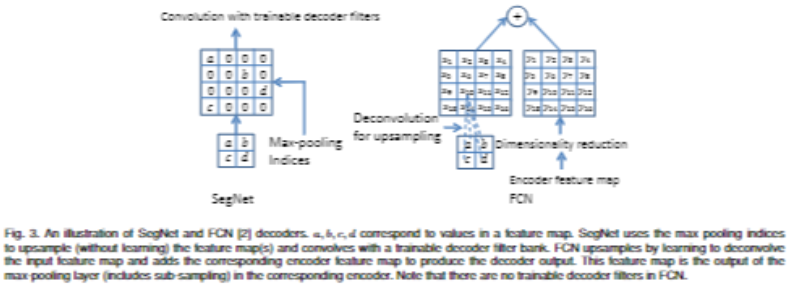
SegNet、FCN 的上采样差异?
![SegNet-20230408143609-1]()
- SegNet 保留 pooling 时的位置信息,通反池化 (UnPooling) 时直接将数据放在原先的位置
- FCN 采反卷积 (deconvolution) 双线性插值,每一个像素都是运算后的结果
SegNet 与 DeconvNet 的异同?
- 相同:(1)都使用 VGG16 作为特征提取网络;(2)都使用反池化 (UnPooling)
- 差异:(1)DeconvNet 上采样交替使反卷积 (deconvolution) 和反池化 (UnPooling) ,SegNet 上采样只使反池化 (UnPooling) ;DeconvNet 存在 VGG16 的全连接层,SegNet 去掉了全连接层
SegNet 与 UNet 的差异?
- U-Net 没有利用池化位置索引信息,而是将编码阶段的整个特征图传输到相应的解码器(以牺牲更多内存为代价),并将其连接,再进行上采样(通反卷积 (deconvolution)),从而得到解码器特征图