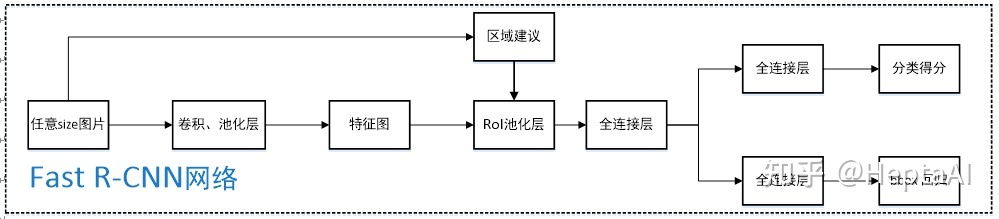
Fast R-CNN
一种 two-stage 的目标检测算法,设计感兴趣区域池化 (RoIPooling),并去掉 SVM 训练的获选框分类器;最终,在选择性搜索 (SelectiveSearch,SS) 之后,神经网络可以进行端到端训练
什么是 Fast RCNN?
![]()
- 是一种 two-stage 的目标检测算法,借鉴 SPPNet 设计感兴趣区域池化 (RoIPooling),并去掉 SVM 训练的获选框分类器;最终,在选择性搜索 (SelectiveSearch,SS) 之后,神经网络可以进行端到端训练
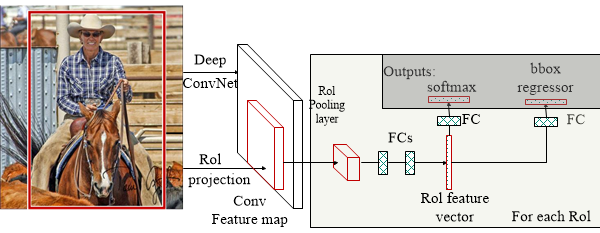
Fast RCNN 的目标识别任务步骤?
![FastRCNN-20230408141502]()
- 1)获得候选框:利用选择性搜索 (Selective Search, SS) 在图像提取 2000 个左右建议窗口 (Region Proposal)
- 2)网络学习整张图片:将整张图片输入 CNN,进行特征提取
- 3)获得获选框最后一层特征:把候选框映射到 CNN 的最后一层卷积 feature map 上
- 4)获得获选框固定长度特征:通过 RoI pooling 层使每个获选框特征变为固定长度
- 5)获选框的分类与回归:利用 Softmax Loss (探测分类概率) 和 Smooth L1 Loss (探测边框回归) 对分类概率和边框回归 (Bounding box regression) 联合训练
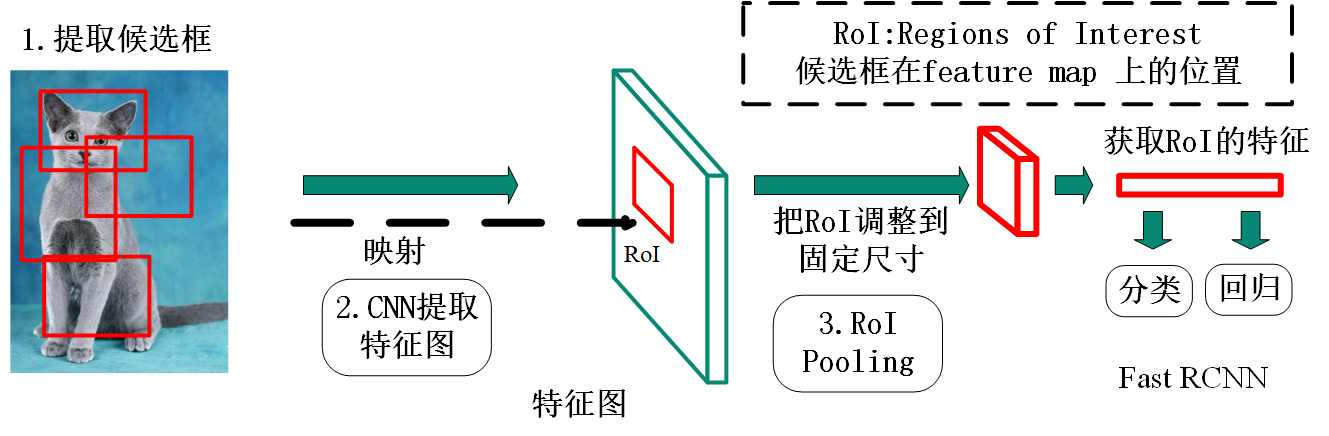
什么是感兴趣区域池化 (RoIPooling)?
- RoIPooling 是 Pooling 层的一种,而且是针对感兴趣区域 (RoI) 的 Pooling,其特点是输入特征图尺寸不固定,但是输出特征图尺寸固定
![]()
![]()
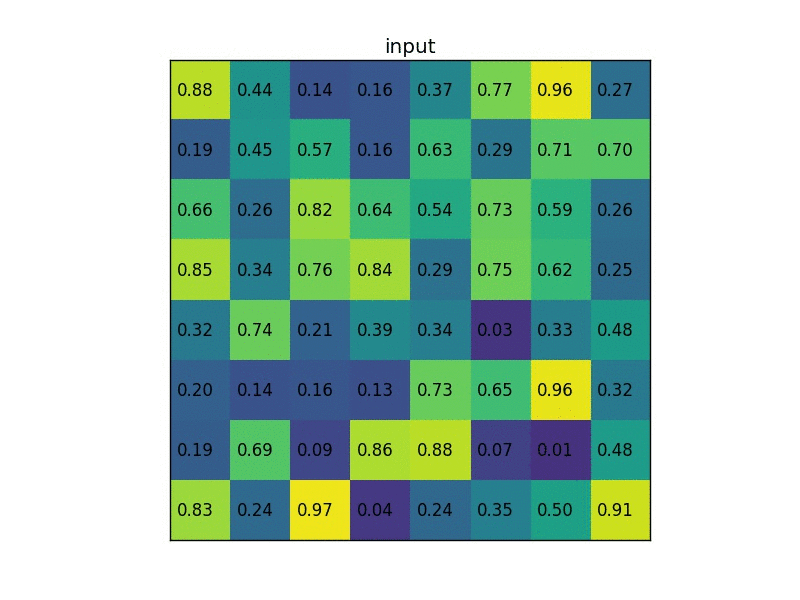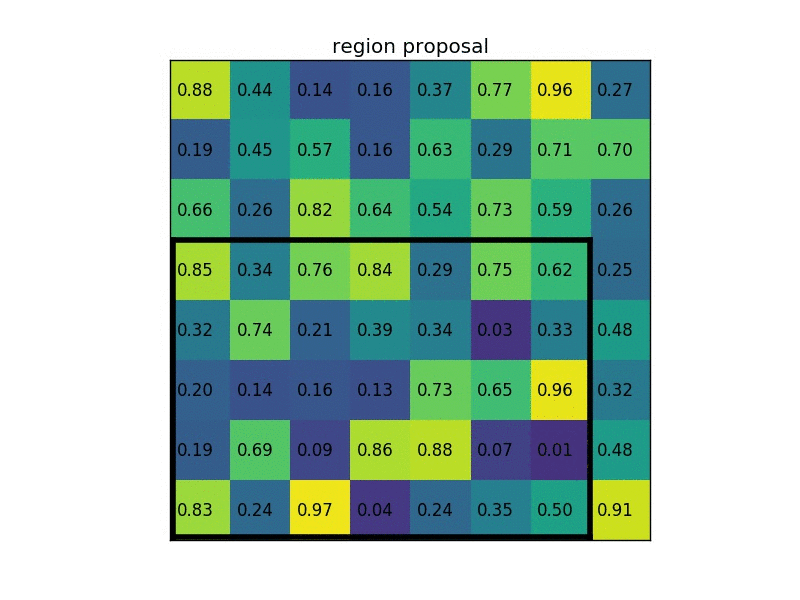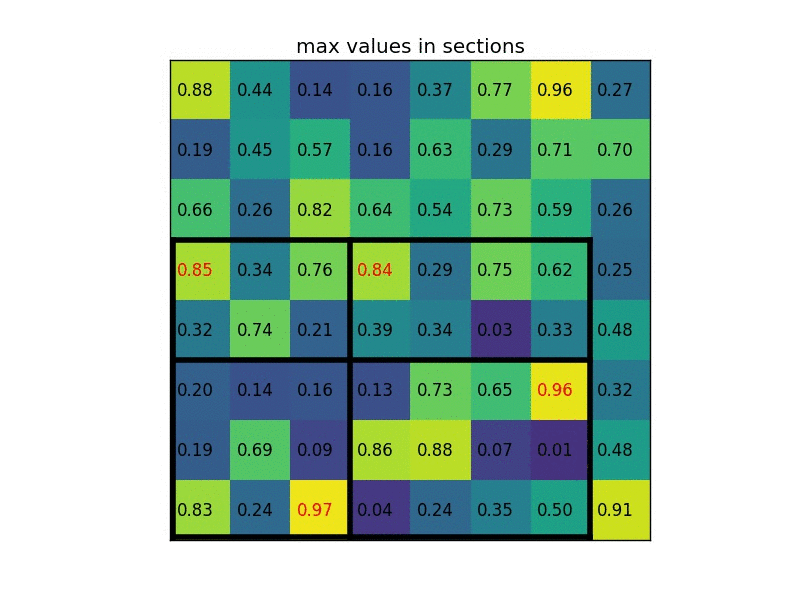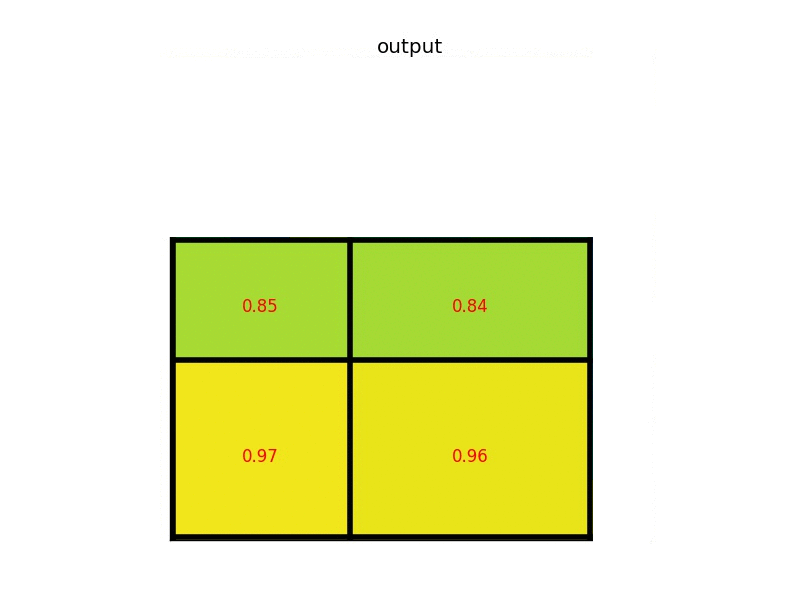
ROIPooling 如何计算池化结果?
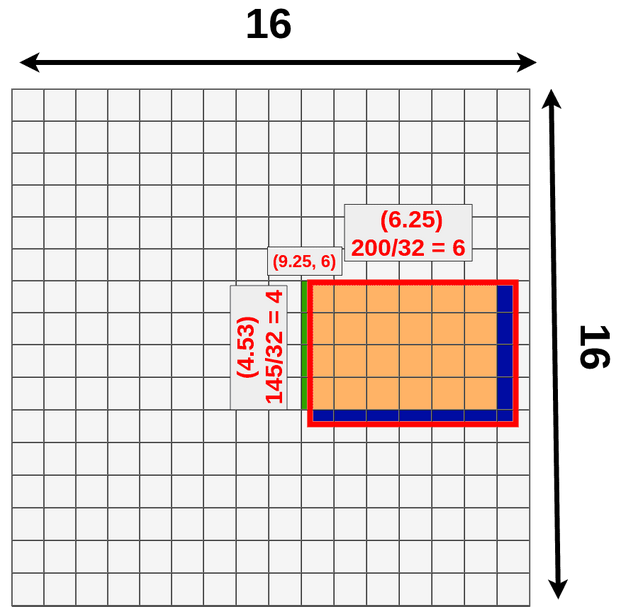
- 假设模型输入是:3x512x512,经过特征提取得到 512x16x16 的特征,即数据下采样 512/16=32 倍,现有目标位置 (192,296),大小 145x200
![]()
- ROI 映射: 计算得到该目标在特征图上位置为:(296/32=9.25,192/32=6),大小为 (200/32=6.25,145/32=4.53),ROIPooling 会将小数舍去,如此将使用下图黄色 + 绿色的区域下采样,舍弃蓝色区域
![]()
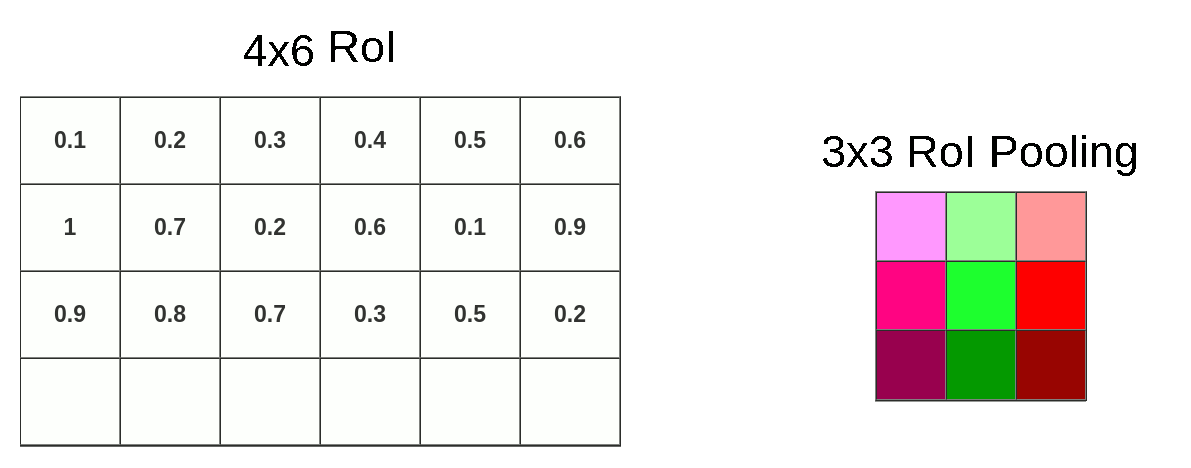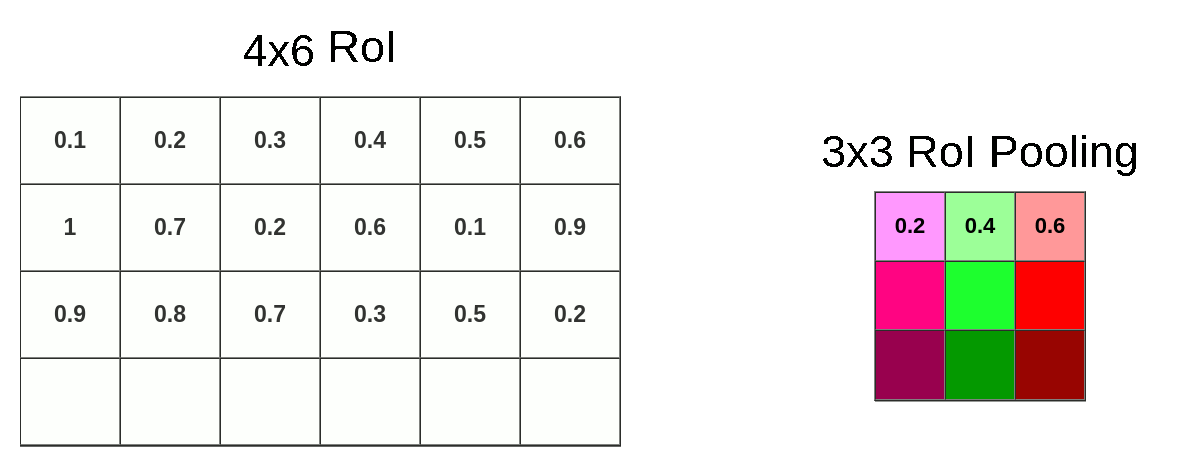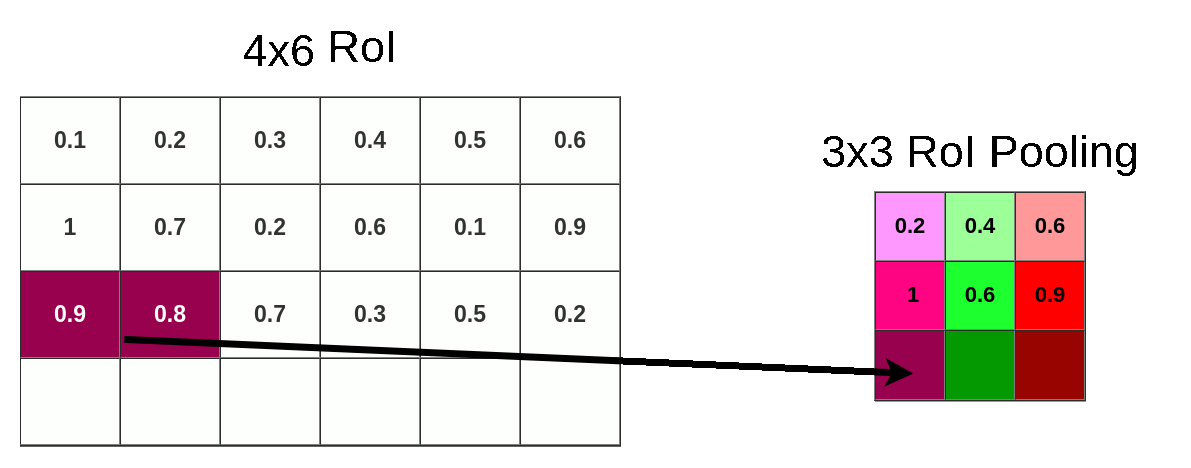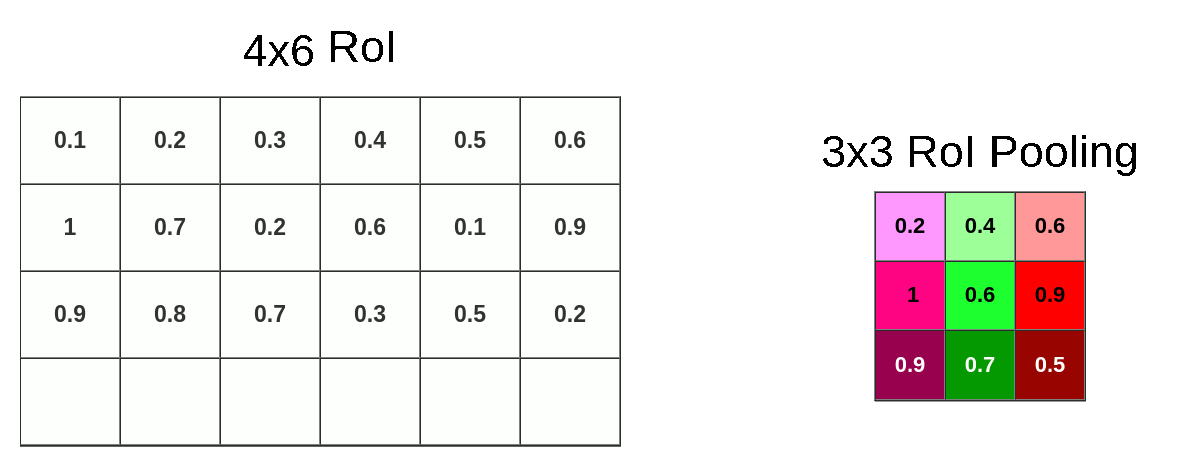
- ROI 区域池化: 假设特张图上的值如下图,对上图黄色 + 绿色区域进行 3x3 的 ROI pooling,由于 4/3=1.3, 所以每个 bin 为 1 行数据下采样,最终得到绿色 3x3 新特征图,由图可知我们彻底失去最后一行
![]()

ROIPooling 的反向传播?
- 类比最大池化层做反向传播 ,不同在于,最大池化前
Fast RCNN 中 ROI Pooling 的输入是什么?
- 输入包含两部分
- 特征图(feature map): 指的是上面所示的特征图,在 Fast RCNN 中,它位于 RoI Pooling 之前,在 Faster RCNN 中,它是与 RPN 共享那个特征图,通常我们常常称之为 “share_conv”
- RoIs: 其表示所有 RoI 的 N* 5 的矩阵。其中 N 表示 RoI 的数量,第一列表示图像 index,其余四列表示其余的左上角和右下角坐标。在 Fast RCNN 中,指的是选择性搜索 (Selective Search, SS) 的输出;在 Faster RCNN 中指的是 Region Proposal Networks (RPN) 的输出,一堆矩形候选框,形状为 1x5x1x1(4 个坐标 + 索引 index)
Fast RCNN 的 ROI Pooling 与 SPPNet 的 Spatial Pyramid Pooling 有什么区别?
- ROI (Region of Interest) Pooling 是 Pooling 的一种, 是针对 RoIs 的 Pooling,其特点是输入特征图尺寸不固定,但是输出特征图尺寸固定
- ROI Pooling 的思想来自于 SPPNet 中的空间金字塔池化 (SpatialPyramidPooling,SPP),将 SPPNet 中多尺度的池化简化了为单尺度,且按原始位置排列(不像 SPP 将特征排成一行)
Fast RCNN 如何进行训练?为什么比 SPPNet 快?
- 没有单独训练 SVM 分类器:Fast RCNN 将候选框的分类及定位任务都在卷积网络中完成,
- Fast RCNN 能够使用反向传播来更新训练所有的网络权重。SPPNet 不能更新所有的权重,不能更新 spp 之前层的参数。 根本原因是当每个训练样本(即 RoI)来自不同的图像时,通过 SPP 层的反向传播是非常低效的
Fast RCNN 的输入中,多个感兴趣区域,如何产生最后的输出?
- 输入的维度是 [N, C, H, W],表示 N 张图片累加的 C 个感兴趣区域,论文 N=2,C=128,表示每个 batch 使用 2 张图片,每张图片拟合 64 个感兴趣区域
- 就一张图片而言,虽然其目标的数量不定,但是感兴趣区域却被固定为 64,所以输出也是固定为 64
Fast RCNN 的 ROI 池化时,选择单尺度还是多尺度?
- 这里多尺度的 5 表示输入图像采用 5 中不同的尺寸,比如 [480,576,688,864,1200],在测试的时候发现多尺度虽然能在 mAP 上取得一点提升,但是时间代价也比较大,直接原因是:深度卷积网络可以学习尺度不变性
![FastRCNN-20230408141505]()
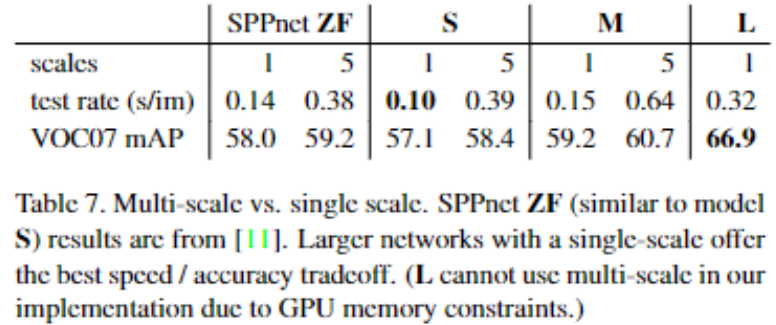
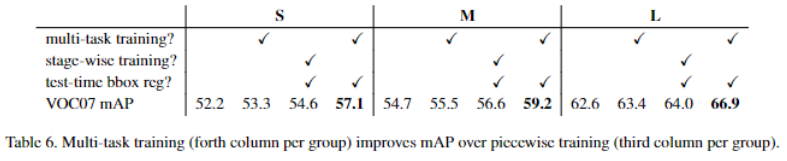
Fast RCNN 的直接在卷积神经网络进行多任务训练有用吗?
- 一共有 S,M,L 三个组,每个组有 4 列,分别表示:1、仅采用分类训练,测试也没有回归;2、采用论文中的分类加回归训练,但是测试时候没有回归;3、采用分段训练,测试时候有回归;4、采用论文中的分类加回归训练,且测试时候有回归 ,可以看出多任务训练有效
![FastRCNN-20230408141506]()
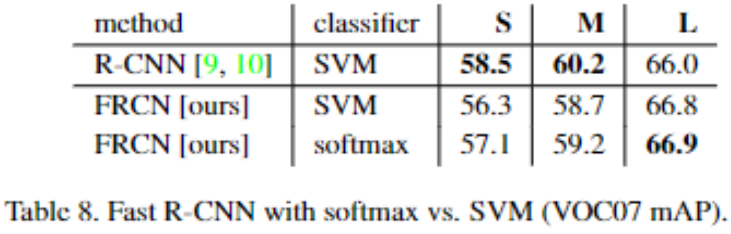
Fast RCNN 使用 softmax 替换 SVM 分类,有什么作用?
- softmax 略微优于所有三个网络的 SVM。这种效果很小,但表明与以前的多阶段训练方法相比,“一次性” 微调就足够了。我们注意到,softmax 与二分类的 svm 不同,在 scorin 时引入了 class 之间的竞争
![FastRCNN-20230408141506-1]()
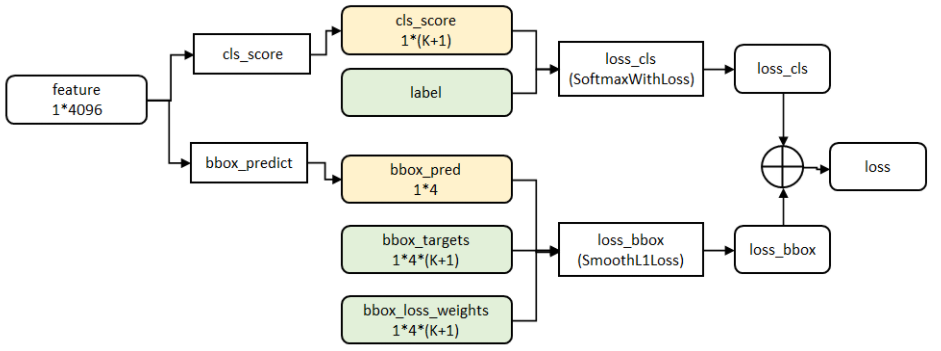
Fast RCNN 的损失函数?
![]()
- losscls 层评估分类代价:由真实分类 u 对应的概率决定
- lossbbox 评估检测框定位代价:比较真实分类对应的预测参数 和真实平移缩放参数为 v 的差别 ,g 为平滑绝对值损失 (Smooth L1 Loss),对 outlier 不敏感
- 总代价为两者加权和,如果分类为背景则不考虑定位代价
Fast RCNN 相比较 R-CNN,有什么不同?
- 最后一层卷积层后加了一个 ROI pooling layer
- 损失函数使用了多任务损失函数 (multi-task loss),将边框回归直接加入到 CNN 网络中训练
Fast RCNN 相比较 R-CNN、SPPNet,有哪些改进?
- SPPNet 算法来解决 RCNN 中重复卷积的问题,但是 SPPNet 依然存在和 RCNN 一样的一些缺点比如:训练步骤过多,需要训练 SVM 分类器,需要额外的回归器,特征也是保存在磁盘上
- Fast RCNN 相当于全面改进了原有的这两个算法,不仅训练步骤减少了,也不需要额外将特征保存在磁盘上
- Fast RCNN 算法在训练速度上比 RCNN 快了将近 9 倍,比 SPPNet 快大概 3 倍;测试速度比 RCNN 快了 213 倍,比 SPPNet 快了 10 倍