RNNsearch
在 seq 2 seq 的基础上,引入注意力机制
什么是 RNNsearch ?
![]()
- RNNsearch 在 Seq 2 Seq 的基础上,引入了 Attention 机制,大概思想是:decoder 层在每次输出前,遍历一遍输入序列,计算一个权重,决定哪些输入词对当前时刻的输出更重要
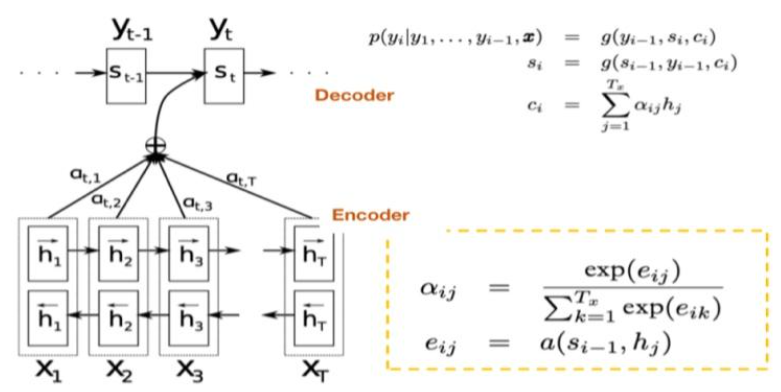
RNNsearch 的网络结构?
![]()
- Encoder:这里直接是双向多层的 LSTM,已知 LSTM 是 3 输入 3 输出模型,即输入隐状态 h + 上下文 c 和当前使时刻输入 x,输出是下一时刻的输入隐状态 + 上下文 + 输出 o。所以 Encoder 计算如下,其中 W,V 是权重矩阵, 是上一时刻的隐状态和上下
- Decoder:第一步是根据以前时刻的隐状态 和 encoder 以前的隐状态 生成当前时刻的上下文 ,其中 是 encoder 在 i 时刻 encoder 隐状态 对 decoder 中 t 时刻隐状态 的影响程
\begin {aligned}&c_t =\sum_{i=1}^{T}\alpha_{ti} h_{i} \\&\alpha_{ti} =\frac {exp (e_{ti})}{\sum_{k=1}^Texp (e_{tk})} \\&e_{ti} =v_{a}^{\top} tanh (W_{a} s_{i-1},h_{i}]) \end {aligned}$$,第二步是传递隐藏层的信息,并预 $$\begin {array}{l} s_t=tanh (W [s_{t-1},y_{t-1},{\color {red}{c_t}}])\\o_t=softmax (Vs_t)\end {array}
参考: