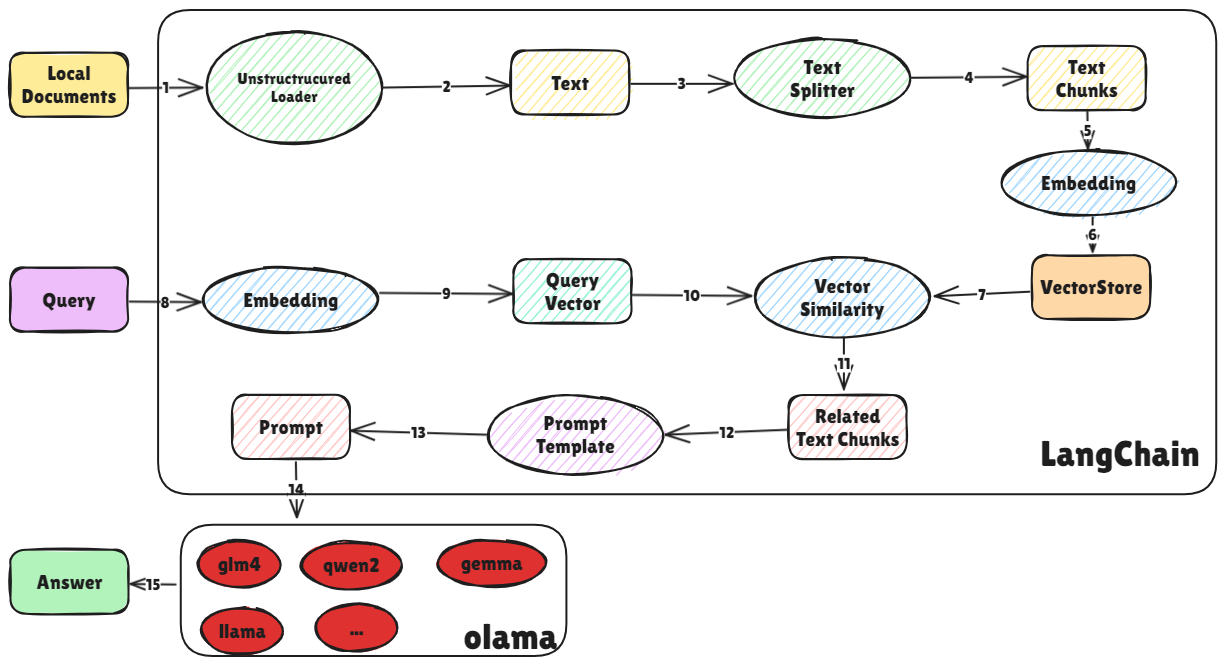
使用 langchain 搭建 RAG 的过程
与仅依赖模型预训练知识不同,这种方法可以进一步整合用户自有数据,实现更加个性化和专业的问答服务 ,以下是 langchian 构建 RAG 的过程
对外挂知识库进行切割,并通过 embedding 模型将其向量化,最后将其存储到向量矩阵
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from langchain.document_loaders import DirectoryLoaderdirctory='/home/wushaogui/MyCodes/langchain-chatglm/documents' loader=DirectoryLoader(dirctory) documents=loader.load() from langchain.text_splitter import CharacterTextSplittertext_spliter=CharacterTextSplitter(chunk_size=256 ,chunk_overlap=0 ) split_docs=text_spliter.split_documents(documents) from langchain.embeddings.huggingface import HuggingFaceEmbeddingsencode_kwargs = {"normalize_embeddings" : False } model_kwargs = {"device" : "cuda:0" } embeddings= HuggingFaceEmbeddings( model_name='/mnt/wushaogui/huggingface/shibing624/text2vec-base-chinese/' , model_kwargs=model_kwargs, encode_kwargs=encode_kwargs ) from langchain.vectorstores import Chromapersist_directory="VectorStore" db = Chroma.from_documents(split_docs, embeddings, persist_directory=persist_directory) db.persist()
通过 3 种方式接入大模型,分别是 url、自定义 LLM 类及 ollama
通过 url 的方式 :基于项目 https://github.com/THUDM/ChatGLM-6B.git 将 chatglm 以服务的形式提供出去,然后 langchain 使用以下代码接入大模型
1 2 3 4 5 6 7 from langchain.llms import ChatGLM llm = ChatGLM( endpoint_url='http://127.0.0.1:8000' , max_token=80000 , top_p=0.9 ) llm.invoke("你好,给个回复" )
自定义 LLM 类 : 继承 langchain.llms.base,追加实现模型加载功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from typing import Optional , List , Any from transformers import AutoTokenizer, AutoModelfrom langchain.llms.base import LLMfrom langchain.callbacks.manager import CallbackManagerForLLMRunclass ChatGLM (LLM ): tokenizer: AutoTokenizer = None model: AutoModel = None @property def _llm_type (self ) -> str : return "ChatGLM3" def load_model (self, model_dir ): self .tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True ) self .model = AutoModel.from_pretrained(model_dir, trust_remote_code=True ).quantize(4 ).half().cuda().eval () def _call ( self, prompt: str , stop: Optional [List [str ]] = None , run_manager: Optional [CallbackManagerForLLMRun] = None , **kwargs: Any , ) -> str : if stop is not None : raise ValueError("stop kwargs are not permitted." ) print ('prompt:' ,prompt) response, history = self .model.chat(self .tokenizer, prompt, history=[]) return response llm = ChatGLM() llm.load_model("/mnt/wushaogui/huggingface/THUDM/chatglm-6b-int4" )
ollama :通过 ollama 开放大模型服务,然后 langchain
langchain 已经将 RAG 的流程封装为 RetrievalQA 的 chain,直接初始化即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from langchain.prompts import PromptTemplateQA_CHAIN_PROMPT=PromptTemplate.from_template("""根据下面的上下文内容回答问题。如果你不知道答案,就回答不知道,不要试图编造答案。 答案最多3句话,保持答案简介。总是在答案结束时说“谢谢你的提问!” {context} 问题:{question} """ )from langchain.chains import RetrievalQAretriever=db.as_retriever() qa=RetrievalQA.from_chain_type( llm=llm, retriever=retriever, verbose=True , chain_type_kwargs={"prompt" : QA_CHAIN_PROMPT} ) message='孙悟空打白骨精了吗' response = qa({"query" : message})
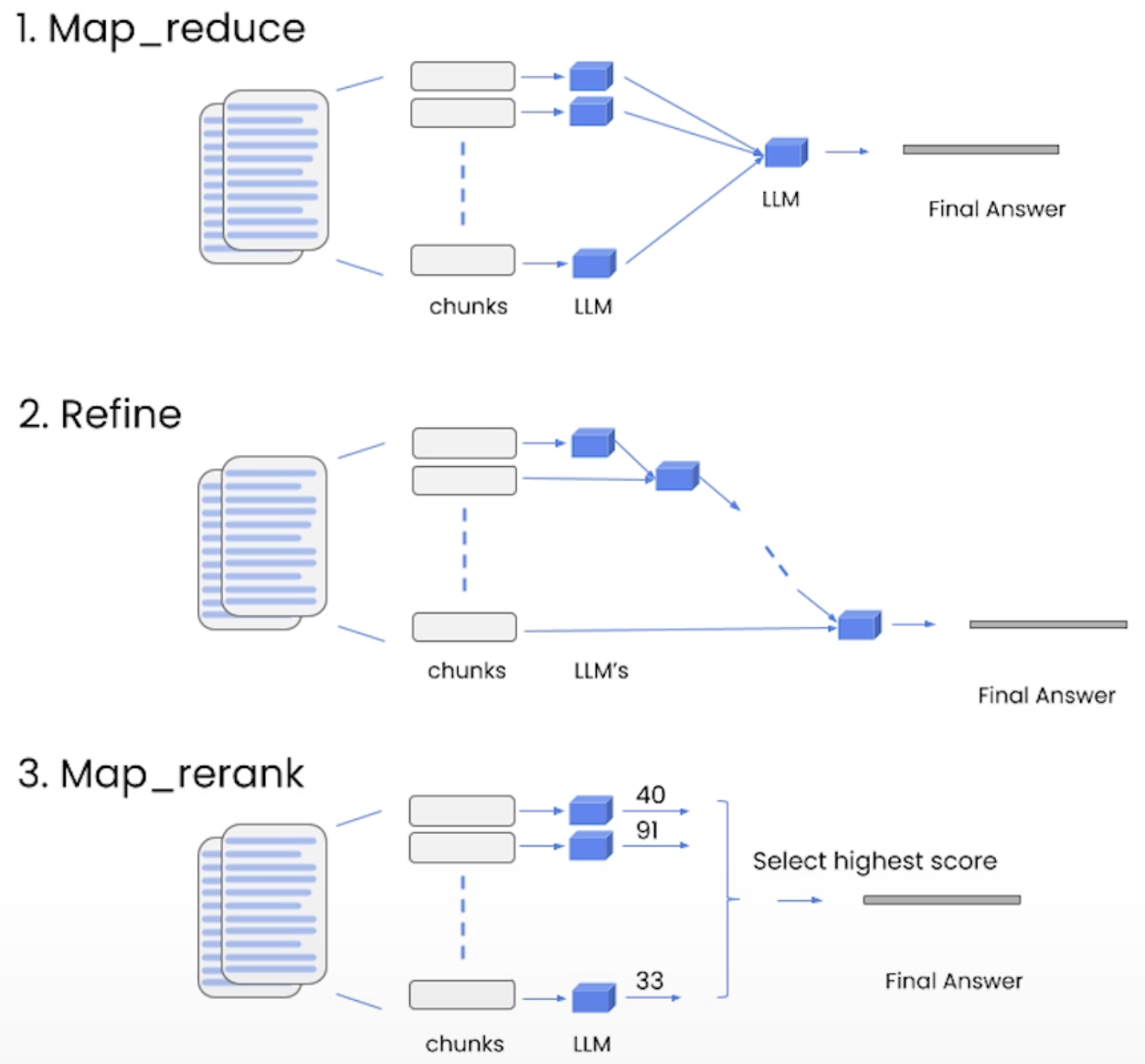
RetrievalQA 的参数 chian_type 指定了组织外挂知识库的方式
也可以使用以下自定义的 chain 实现 RAG 的过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from langchain.prompts import PromptTemplateprompt=PromptTemplate.from_template("""根据下面的上下文内容回答问题。如果你不知道答案,就回答不知道,不要试图编造答案。 答案最多3句话,保持答案简介。总是在答案结束时说“谢谢你的提问!” {context} 问题:{question} """ )retriever=db.as_retriever() def format_docs (docs ): return "\n\n" .join(doc.page_content for doc in docs) from langchain_core.runnables import RunnablePassthroughfrom langchain_core.output_parsers import StrOutputParserchain = ( {"context" : retriever|format_docs, "question" : RunnablePassthrough()} | prompt | llm | StrOutputParser() ) question = "关羽失败后去了哪里?" response = chain.invoke(question) print (response)
参考:
构建检索增强生成 (RAG) 应用 | 🦜️🔗 LangChain 中文