CCNet:Criss-Cross Attention for Semantic Segmentation
对于每个位置的空间注意力,Non-local 建立的是所有点与其的注意力,而 CCNet 仅建立与其十字架内点的注意力,可以大幅点降低构建注意力的成本,并通过堆叠 2 个交叉注意力模块,实现双向空间注意力
什么是 CCNet?
![CCNet-20230408142244]()
- CCNet 设计 criss-cross attention(CCA) 模块获取交叉路径上其周围像素的上下文信息。通过采取进一步的循环操作,每个像素最终可以捕获所有像素的远程依赖关系
- 与 non-local 相比,recurrent CCA 模块所需的 GPU 内存使用量减少且计算效率提高
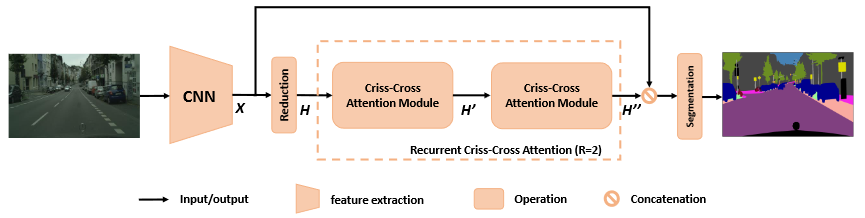
CCNet 的网络结构?
![CCNet-20230408142244]()
- BackBone:输入图像经过深度卷积神经网络(DCNN),该深度卷积神经网络是全卷积网络,然后生成特征图 X
- CCA 注意力模块:将降维后的特征图 H 送入 CCA 模块,生成的新特征图 H’,仅在水平和垂直方向上聚合上下文信息。为了获取更丰富和更密集的上下文信息,将特征图 H’再次输入到 CCA 模块中,这样得到的特征图 H’' 中的每个位置就收集了所有像素的信息
- 分割:将密集的上下文特征 H’' 和局部表示特征 X 连接起来,将融合的特征图送入分割网络层
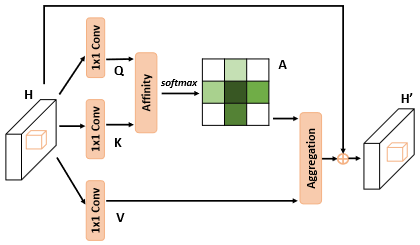
CCNet 的交叉注意力模块?
![BiSeNetv3-20230408142304]()
- 产生关联矩阵 A:输入 H 为 CxWxH,通过 1 x 1 卷积得到 C’xWxH (C’设置为 C 的 1/8) Q 和 K,用 Q 和 K 生成 (H+W-1) xWxH 的 A 。具体地,提取 Q 的某一像素位置 1 xC’的值,然后提取 K 上十字位置的特征向量,则其大小为 (H+W-1) xC’,进行 affinity 操作得到 (H+W-1) xWxH,再对 (H+W-1) 维度进行 softmax 操作,得到 A (H+W-1) xWxH
- 聚合特征 aggregation:将 CxWxH 大小的 V 取十字特征向量与 A 特征图进行对应元素按位相乘,得到 H’ (CxWxH),这里是利用前一步学习到的十字权重,对十字权重位置的值进行加权处理
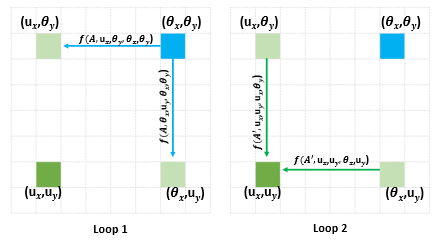
- 为什么需要重复执行两次 CCA? Loop 1 是十字计算权重,所以深绿和深蓝位置并没有关联;但是经过 loop 2,浅绿位置已经有了深绿和深蓝位置的上下文信息,就可以将深蓝和深绿位置关联起来,两次 CCA 任意一个位置都可以感知矩阵所有位置的信息
![BiSeNetv3-20230408142305]()
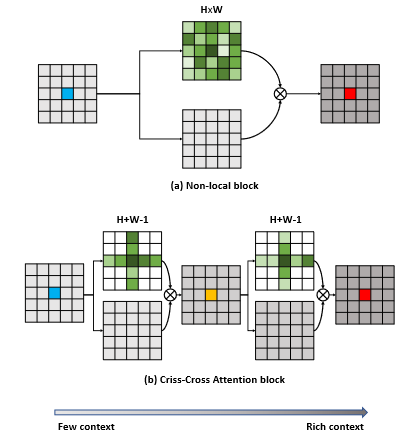
CCNet 的注意力模块和 Non-local 注意力模块差异?
![BiSeNetv3-20230408142305-1]()
- Non-local 模块:每个位置都会生成密集的注意力图,该图的权重为 H×W(绿色)
- criss-cross 模块:每个位置会生成一个稀疏的注意图,该图仅具有 H+W-1 个权重。循环操作后,最终输出特征图中的每个位置(例如红色)都可以捕获所有像素的远程依赖关系
- 与 non-local 相比,recurrent CCA 模块所需的 GPU 内存使用量减少且计算效率提高