DETR:End-to-End Object Detection with Transformers
将 transformers 运用到了 object detection 领域,取代了现在的模型需要手工设计的工作(非极大值抑制和 anchor generation),并且取得了不错的结果。在 object detection 上 DETR 准确率和运行时间上和 Faster RCNN 相当;将模型应用到全景分割任务上,DETR 表现甚至还超过了其他的 baseline
什么是 DETR?
![DETR-20230408152356]()
- 将 transformers 运用到了 object detection 领域,取代了现在的模型需要手工设计的工作(非极大值抑制和 anchor generation),并且取得了不错的结果。在 object detection 上 DETR 准确率和运行时间上和 Faster RCNN 相当;将模型应用到全景分割任务上,DETR 表现甚至还超过了其他的 baseline
- 图片经过 CNN 学习后,输出 (B, C, H, W) 特征,HxW=S 视为 token 的个数得到序列 (B, S, C),并使用 transformer 学习,然后产生 N (N 可以不等于 S,一般是 100) 个 grid 预测,分别预测其类别与 box,然后使用双边匹配算法(匈牙利算法)匹配预测结果与 gt,计算损失,训练网络

DETR 的模型结构?
![DETR-20230408152356-1]()
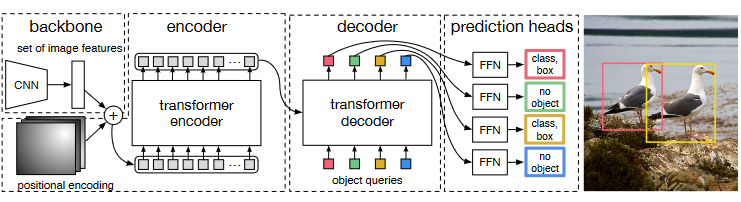
- CNN:图像经过 CNN 学习后,得到 的输出,然后和 position encoding 相加,输入 transformer-encoder
- transformer-encoder:将 作为 token 数量,然后使用 transfor 进行学习,输出
- transformer-decoder:包括两部分输入,来自 transformer-encoder 的输出 和 N 个 object queries,object queries 是训练时随机初始化,训练完成后直接得到该值。在两个输入下的 transformer-decoder 输出 N 个预测结果
- FFN:前向计算网络,用于产生所有 token 的类别及 box 预测
DETR 的 transformer 部分的结构?
![DETR-20230408152357]()
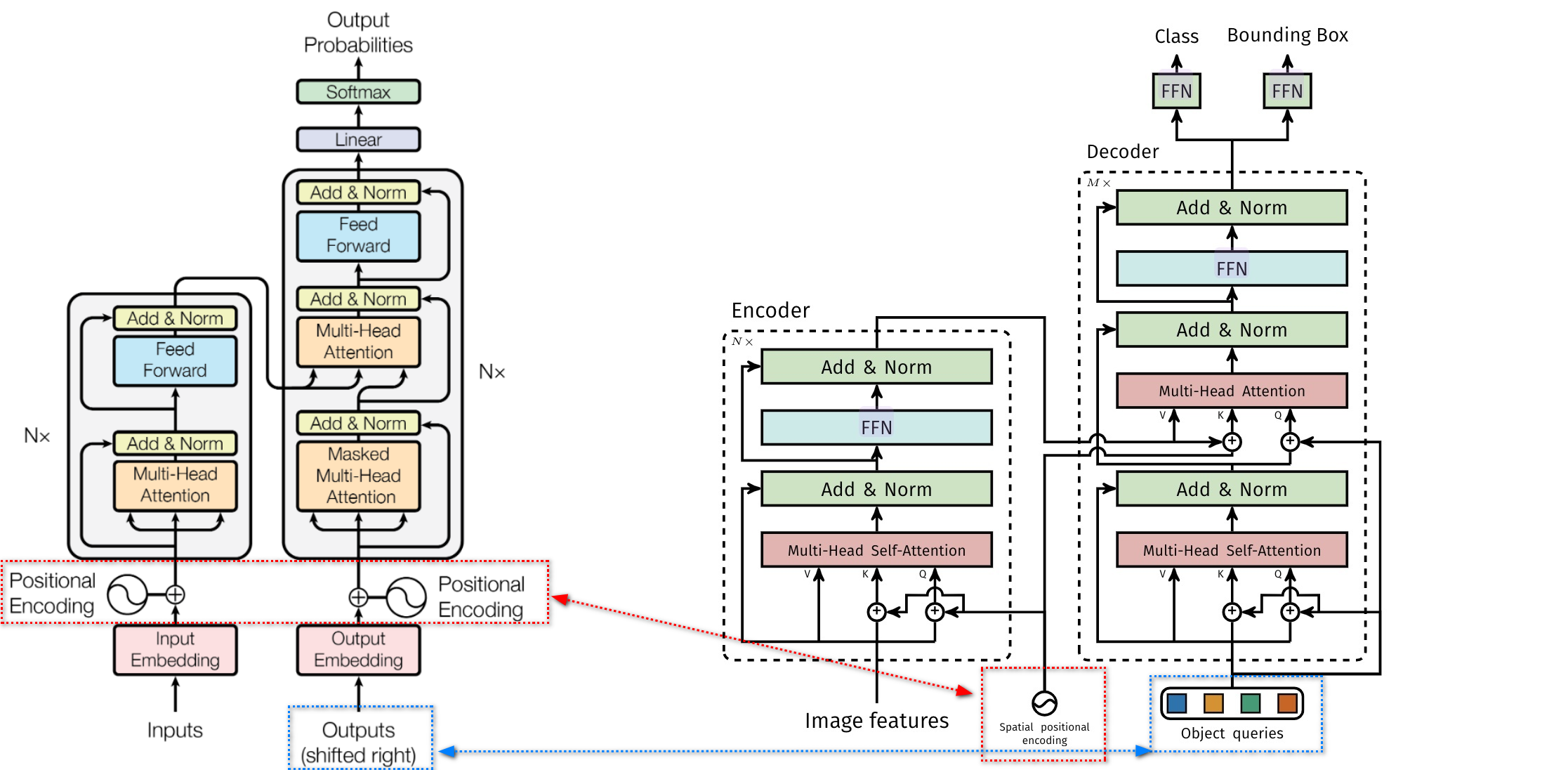
- 不同于原始的 transformer ,DETR 在以下方面对其进行修改
- 1)positional embeding: DETR 的只作用于 encoder 的 Q 和 encoder-decoder K,原始 transformer 作用于所有的 Q、K、V
- 2)object queries:DETR 的 object queries 一次性全部输入 decoder,而原始 transformer 是通过 shifted right 一个一个地移动
DETR 的 transformer decoder 上 object queries 的作用?
![DETR-20230408152357]()
- Object queries 是 N 个 learnable embedding,训练刚开始时可以随机初始化,比如 transformer-encoder 输出是 (B, N’, C),则 Object queries 生成后得到大小为 (B, N, C) 数,相当于用 Object queries 去查询 transformer-encoder 输出的目标类别和 box,N 一般取 100
- 训练时随机初始化 Object queries,训练过程中学习这个 embedding,训练完成后,embedding 确定下来,后续推理直接使用
DETR 如何进行样本分配?
![]()
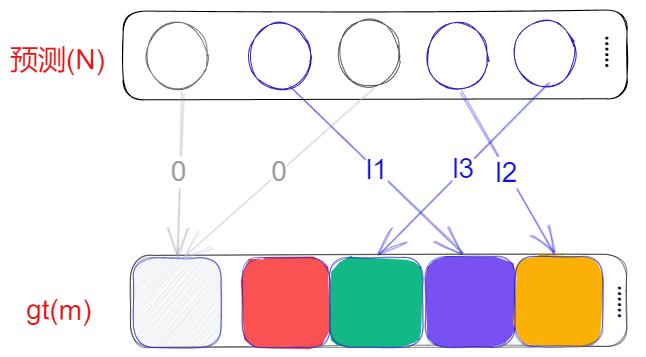
- DETR 的 transformer decoder 输出 N 个目标的预测集合,下一步是如何将这 N 个预测结果分配到 gt 目标上去,以便计算损失,驱使网络学习
- 假设真实目标有 m 个,DETR 认为样本是预测结果 (N) 和 GT(m+1) 的二分图匹配问题,分配的约束条件是最小化损失,之所以是 m+1,是因为 N 个预测结果大部分都是背景,所以增加一个背景目标,用于映射不需要计算损失的预测结果。比如上图有 5 个预测,图片上有 3 个目标,其中 2 个目标映射到背景上,其余目标映射到具体 gt 上
- 计算 gt 目标 与预测集合 的损失,对于那些要学习的预测,获得其对应的预测是目标类别的概率,然后计算框损失和概率损失。这也就是说不仅框要近,类别也要基本一致,是最好的
DETR 的损失函数?
- 样本匹配完成之后,使用以下公式计算损失,其中 为总损失,可以看到他计算了 N 个输出的类别损失和匹配 gt 输出的 box 损失,其中 box 损失 使用 GIOU loss+L1 loss 计算框损失,其中 IOU 损失对于 Scale 不敏感,L1 损失对于 Scale 敏感
DETR 为什么可以不使用 NMS?
![DETR-20230408152434]()
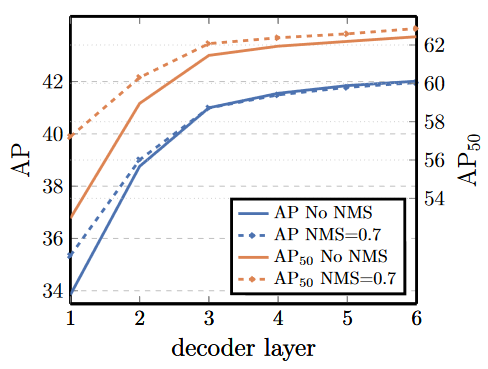
- 上图是每个编码器之后的 AP、AP 50 性能,可以看出当编码层大于 3 后,使用 NMS 和不使用 NMS 的效果是相近的,所以去掉 NMS
DETR 位置编码 (positional encodings) 的作用?
![DETR-20230408152435]()
- 生成方式:DETR 的 position encoding 采用原始 Transformer 论文的固定 position encoding,即对于每个 HW 维向量,用不同频率的 sin 函数对高 (H) 这个维度生成 d/2 维的 position encoding,用不同频率 cos 函数对宽 (W) 这个维度生成 d/2 维的 position encoding,然后将两个的 position encoding concat 成 d 维的 position encoding
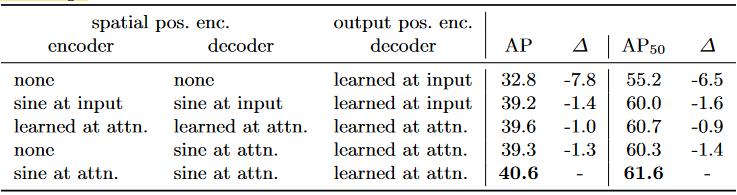
- 作用:看上表可知,对比不增加 positional encodings 的模型,增加了的模型效果更好,还有一种是增加可学习的 position encoding,其效果和 2D 嵌入差不多,因为 2D 嵌入成本更低,所以使用该方法。增加 position encoding 对目标检测这类位置敏感的模型提升较大
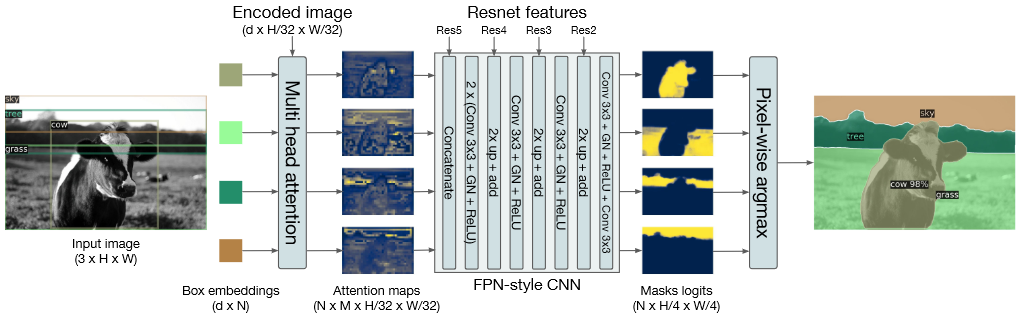
DETR 如何应用到全景分割?
![DETR-20230408152435-1]()
- 图片经过 CNN、transformer 后,得到 (N, M, H/32, W/32) 的输出,通过 Restnet featrues 模块预测每张图的 Mask 结果,一张图预测一个 Mask,即得到一张图的全景分割
- Restnet featrues 模块主要功能:还原分辨率及降低通道数 M
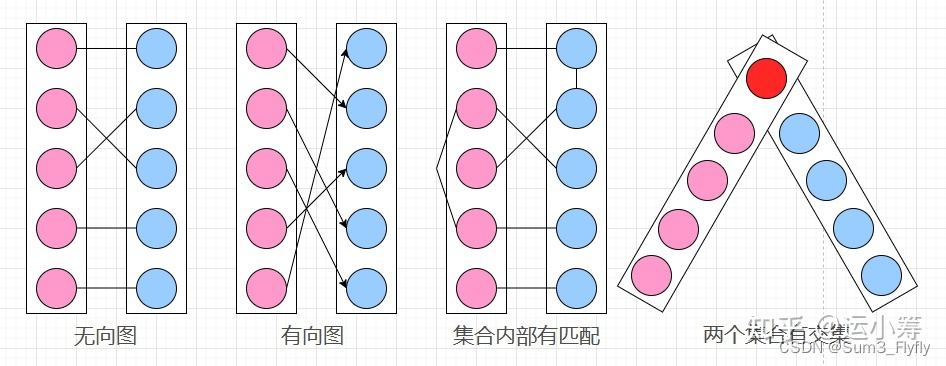
什么是二分图?
![DETR-20230408152436]()
- 设 G=(V, E) 是一个无向图,如果顶点 VV 可分割为两个互不相交的子集 (A, B),并且图中的每条边(i,j)所关联的两个顶点 i 和 j 分别属于这两个不同的顶点集 (i∈A, j∈B),则称图 G 为一个二分图。简而言之,就是顶点集 V 可分割为两个互不相交的子集,并且图中每条边依附的两个顶点都分属于这两个互不相交的子集,两个子集内的顶点不相邻
- 上图只有 1 满足二分图,其余都不是二分图
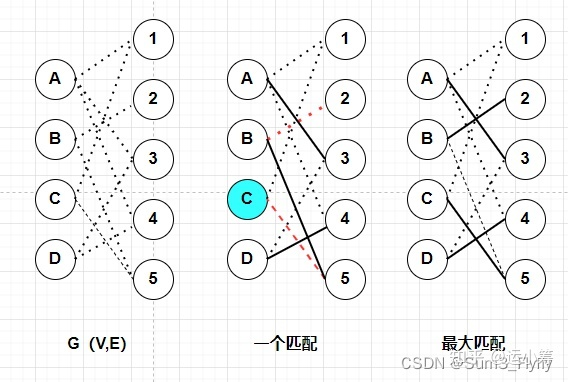
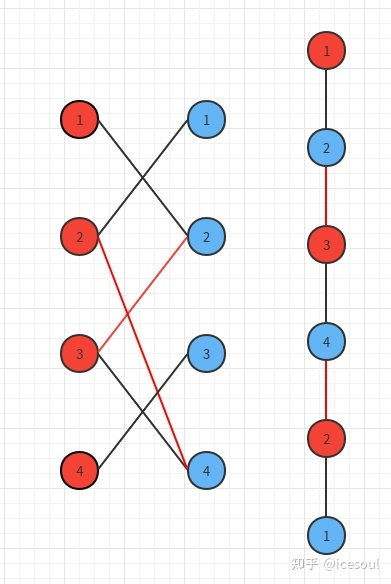
什么是二分图匹配?
![DETR-20230408152436-1]()
- 匹配:在图论中,一个 “匹配” 就是一个 “边” 的集合,其中任意两条边都没有公共顶点
- 最大匹配:一个图的匹配集合中,所含匹配边数最多的匹配,或者说覆盖的点最多,称为这个图的最大匹配
- 完美匹配:当一个图的匹配覆盖了所有的点,那么它就是一个完美匹配
- 上图中的 “一个匹配” 中就仅是一个普通的匹配,而且很容易发现一条增广路径:2-B-5-C,然后就得到了最后的 “最大匹配” 的结果
什么是匈牙利算法(KM Algorithm)?
![DETR-20230408152437]()
- 二分图匹配常用的算法,是在二分图中寻找增广路,并修改边的匹配情况,如果没有增广路了,那么这张图就达到最大匹配了
- 增广路:若 P 是图 G 中一条连通两个未匹配顶点的路径,并且属于 M 的边和不属于 M 的边 (即已匹配和待匹配的边) 在 P 上交替出现,则称 P 为相对于 M 的一条增广路径,上图右边就是增广路径
参考: