ResNeXt:Aggregated Residual Transformations for Deep Neural Networks
在 ResNet 的基础上引入分组卷积,降低模型参数量的同时,要求模型生成更鲁棒的特征
什么是 ResNeXt ?
![ResNeXt-20230408141106]()
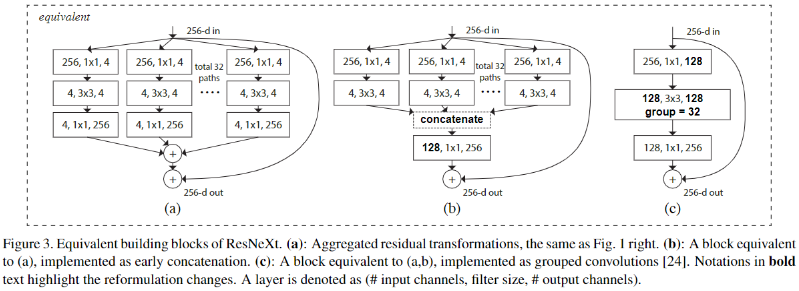
- ResNeXt 同时借鉴 ResNet 的 "堆叠相同 Shape 子结构" 和 Inception 的 "split-transform-merge",不过不同于 Inception,ResNeXt 不需要设计复杂的 Inception 模块,而是每个分支采用相同的拓扑结构
- ResNeXt 的本质是分组卷积,通过变量基数来控制组的数量
ResNeXt 的网络结构?
![ResNeXt-20230408141107]()
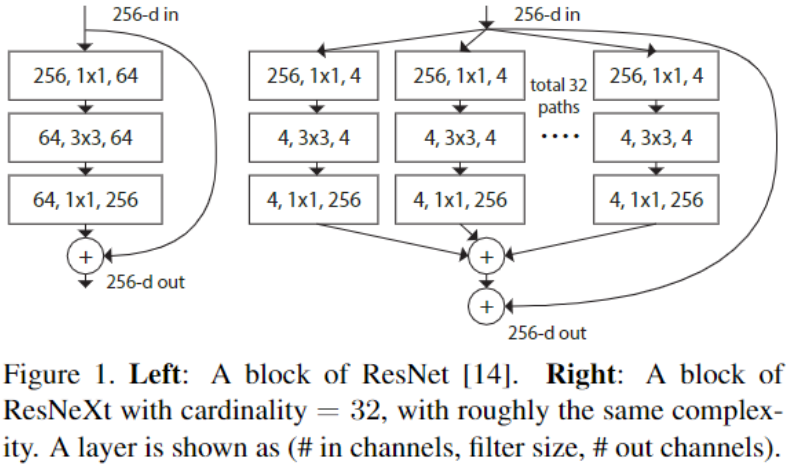
- 首选 ResNeXt 借鉴 VGGNet 网络结构特点 (堆叠块),然后再借鉴 GoogleNetv1 的 "split-transform-merge" 设计出 ResNeXt 的基本结构,图中 ResNeXt 每块采用 C 个相同分支进行变换,ResNeXt-50(32x4d)的 32 表示每块采用的分组数量,4d 表示每组卷积输出的通道数
- 由图可知,ResNet-50 与 ResNeXt-50(32x4d)参数相近,所需计算量也相近
ResNeXt 实现残差学习的原理
![ResNeXt-20230408141108]()
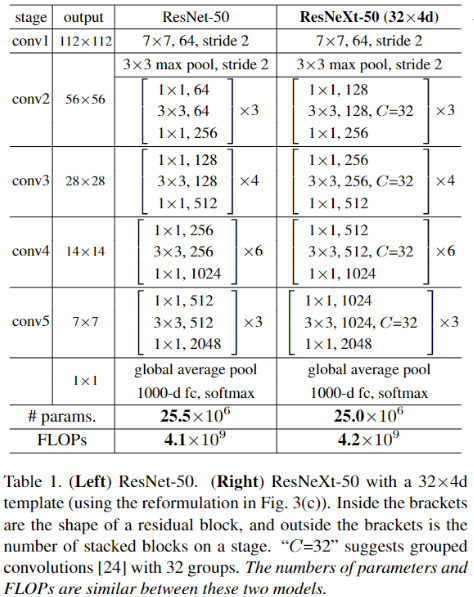
- 由 ResNet 学习残差原理可知,ResNet 学习残差的方式为
- ResNeXt 学习残差的公式为: ,这里的 指的是 ResNeXt 的多个相同拓扑的路径,其中的 C 指的是路径重复的数量,也即 ResNeXt 中的 “基数”
- 上图是 ResNet 及 ResNeXt 的基本块,在第一层转换中,ResNet 的 256 个特征图直接通过 1x1 卷积转为 64 个,而 ResNeXt 将卷积核分为 32 组 (每个卷积核大小为 256x1x1x4),每组生成 4 个特征图,每组特征 concatenation 得到 128 个特征图
ResNeXt、InceptionResNet、分组卷积的关系?
![ResNeXt-20230408141108-1]()
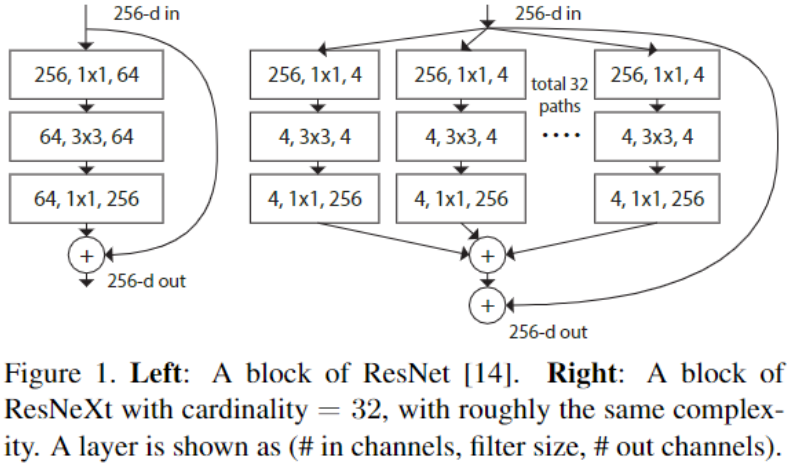
- 上图 a、b、c 分别是 ResNeXt、InceptionResNet 相似块、分组卷积,通过计算分析,上图三种结构确实等价,b 与 c 等价是显然的
- a 与 b 等价的原因是:在 a 中,4 维特征图通过 1\1 卷积变为 256 维,然后 32 个 256 维数据求和,而在 b 中,是先将 4 维数据 concat 成 128 维,在利用 1x1 卷积,实际上也就是求和过程
- 第三种结构较为简单且具有较高的效率,所以作者在实验中选择第三种结构