CUDA 基础知识
CUDA 软件的基础知识
什么是 CUDA?
- CUDA(Compute Unified Device Architecture,** 统一计算架构)** 是由英伟达 NVIDIA 所推出的一种集成技术
- 一种并行计算平台和编程模型,可通过利用图形处理单元 (GPU) 的强大功能来显着提高计算性能
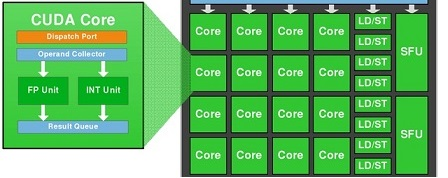
CUDA 核心是什么?
- 一个 GPU 芯片里,会很几千个 CUDA 核心,被分布在多个流处理单元(SM)中,比如上面提到早期的 GTX980 中的 16 个 SM 中各包含了 128 个 CUDA 核心
- 作为 GPU 架构中的最小单元,其实它的设计和 CPU 有着非常类似的结构,其中包括了一个浮点运算单元和整型运算单元,和控制单元。同一个流处理器中,所有的 CUDA 核心将同步执行同一个指令,但是作用于不同的数据点上
![]()
- 一般来说,更加多的 CUDA 核心意味着有更多的并行执行单元,所以也就可以片面地认为是有更加高的性能。但是,其实这个也是取决于很多方面,最重要的是算法在并行实现的时候有没有高效地调度和内存的使用优化。在现在我们使用的大部分 GPU 加速的深度学习框架里,包括 Tensorflow,PyTorch 等都是依赖于底层的 GPU 的矩阵加速代码的实现。为此 Nvidia 公司也是制定和实现了统一的接口,比如 cuDNN,方便上层框架更好的利用 GPU 的性能
当下一个新的 GPU 架构发布时,我是否必须重新编写我的 CUDA 内核?
- 不。CUDA C/C++ 提供了一个抽象; 它是您表达您希望程序如何执行的一种方式。 编译器生成的 PTX 代码也不是硬件特定的。 在运行时,为特定目标 GPU 编译 PTX - 这是驱动程序的责任,每次发布新 GPU 时都会更新驱动程序。 寄存器数量或共享内存大小的变化可能会为进一步优化提供机会,但这是可选的。所以现在写你的代码,享受它在未来的 GPU 上运行的乐趣
CUDA 是否支持一个系统中的多个显卡?
- 是的。 应用程序可以跨多个 GPU 分配工作。 但是,这不是自动完成的,因此应用程序可以完全控制。 有关对多个 GPU 进行编程的示例
CUDA 如何构建计算?
- CUDA 广泛遵循数据并行计算模型。 通常,每个线程对数据的不同元素并行执行相同的操作
- 数据被分成 1D、2D 或 3D 块网格。 每个块的形状可以是 1D、2D 或 3D,并且可以由当前硬件上的超过 512 个线程组成。 线程块中的线程可以通过共享内存进行协作。
- 线程块作为称为 “warp” 的较小线程组执行
CPU 和 GPU 可以并行运行吗?
- CUDA 中的内核调用是异步的,因此驱动程序将在启动内核后立即将控制权返回给应用程序
- 执行内存复制和控制图形互操作性的 CUDA 函数是同步的,并且隐式等待所有内核完成
可以并行传输数据和运行内核(用于流式应用程序)吗?
- 是的,CUDA 支持使用 CUDA 流的重叠 GPU 计算和数据传输
是否可以从其他 PCI-E 设备直接 DMA 进入 GPU 内存?
- GPUDirect 允许您直接 DMA 到 GPU 主机内存
CPU 和 GPU 之间的峰值传输速率是多少?
- 内存传输的性能取决于许多因素,包括传输的大小和使用的系统主板类型
- 在 PCI-Express 2.0 系统上,我们测得高达 6.0 GB / 秒的传输速率
CUDA 中数学运算的精度是多少?
- 当前所有的 NVIDIA GPU 以及 GT200 之后的所有系列都具有双精度浮点, 所有具有计算能力的 NVIDIA GPU 都支持 32 位整数和单精度浮点运算
为什么我的 GPU 计算结果与 CPU 计算结果略有不同?
- 有很多可能的原因。 浮点计算不能保证在任何一组处理器架构中给出相同的结果。 在 GPU 上以数据并行方式实现算法时,操作顺序通常会有所不同
是否可以同时执行多个内核?
- 是的。 计算能力 2.x 或更高的 GPU 支持并发内核执行和启动
如何选择每个块的最佳线程数?
- 为了最大限度地利用 GPU,您应该仔细平衡每个线程块的线程数、每个块的共享内存量以及内核使用的寄存器数量
- 可以使用 CUDA 占用率计算器工具来计算 多处理器占用率给定 CUDA 内核对 GPU 这包含在最新的 CUDA Toolkit 中
内核执行的最大时间是多少?
- 在 Windows 上,单个 GPU 程序启动的最长运行时间约为 5 秒。 超过此时间限制通常会导致通过 CUDA 驱动程序或 CUDA 运行时报告启动失败
什么是 CUFFT?
- CUFFT 是 CUDA 的快速傅里叶变换 (FFT) 库
CUFFT 支持哪些类型的变换?
- 当前版本支持复数到复数 (C2C)、实数到复数 (R2C) 和复数到实数 (C2R)
什么是 CUBLAS?
- CUBLAS 是 BLAS(基本线性代数子程序)在 CUDA 驱动程序之上的实现。 它允许访问 NVIDIA GPU 的计算资源。 该库在 API 级别是自包含的,也就是说,不需要与 CUDA 驱动程序直接交互