NNLM
创新性提出可训练的词向量,为后续词向量发展提供基础
什么是 NNLM ?
![]()
- 用了一个三层的神经网络来构建语言模型,同样也是 n-gram 模型。目的是利用前 n-1 个词预测第 n 个单词
- NNLM 创新之处在于:不使用 one-hot 的方式去构建词向量,而是使用可学习的 embeding 方式。通过构建一个权重矩阵 C (nxm),这个权重矩阵在神经网络中更新
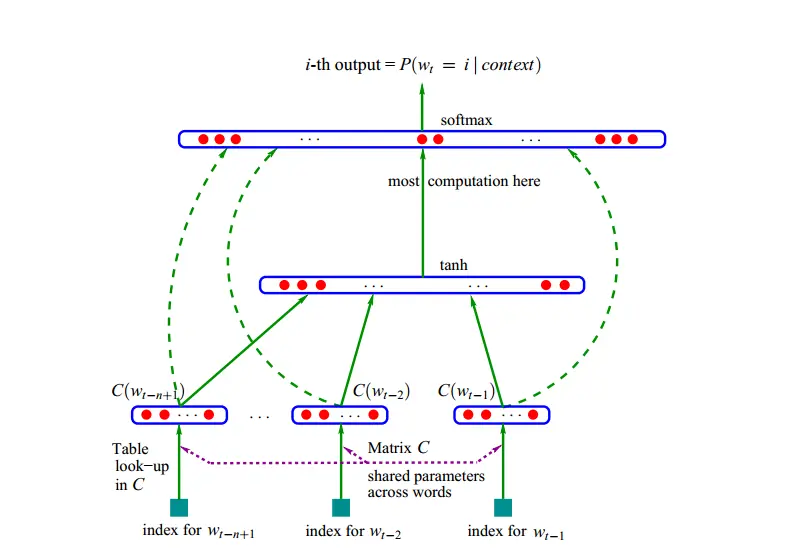
NNLM 的网络结构?
![]()
- NNLM 包含 3 层网络:C->tanh->softmax,其中矩阵 C 是一个 n * m 的矩阵,行数 n 等于词库数量,列数 m 表示一个词的变量表示。首先输入在矩阵 C 中找到词的向量表示,然后将这些向量表示拼接在一起,并使用激活 tanh 和分类层 softmax 处理,最后输出下一个单词的概率
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# NNLM parameters
n_step = 2 # 根据前两个单词预测第3个单词
n_hidden = 2 # 隐藏层神经元的个数
m = 2 # 词向量的维度
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, embedding_dim=m)
self.H = nn.Parameter(torch.randn(n_step * m, n_hidden).type(dtype))
self.W = nn.Parameter(torch.randn(n_step * m, n_class).type(dtype))
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype))
self.b = nn.Parameter(torch.randn(n_class).type(dtype))
def forward(self, x):
x = self.C(x)
x = x.view(-1, n_step * m)
# x: [batch_size, n_step*n_class]
tanh = torch.tanh(self.d + torch.mm(x, self.H))
# tanh: [batch_size, n_hidden]
output = self.b + torch.mm(x, self.W) + torch.mm(tanh, self.U)
# output: [batch_size, n_class]
return output
NNLM 的损失函数?
- 类似于分类,使用交叉熵计算即可
参考: