lanChian 构建 RAG03 - 向量数据库
本文介绍如何利用切分文档创建向量数据库
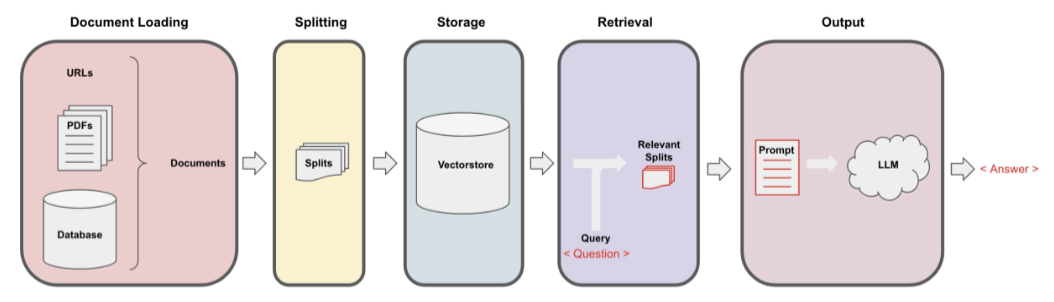
以上是 RAG 的过程,其中向量数据库位于 RAG 的中心,其作用的通过用户输入去检索向量数据库,找到和向量数据库语义相近的 Chunk
构建向量数据库需要两个步骤:
- 定义嵌入模型:将 chunk 编码为向量
- 构建向量库
定义嵌入模型
1 | # 加载embedding模型 |
LangChain 中的基 Embeddings 类提供了两种方法:一种用于嵌入文档,另一种用于嵌入查询。前者 .embed_documents,接受多个文本作为输入,而后者 .embed_query,接受单个文本作为输入
1 | embeddings = embeddings_model.embed_documents( |
可以看出,每句话被编码为长度为 768 的固定长度向量,这里和原始的词向量有区别,原始的词向量是一个分词使用固定向量表示,而这里是一句话用一个向量表示,这是怎么回事?
- 在传统的序列到序列(seq2seq)模型中,编码器(Encoder)会将不定长的输入文本编码为一个固定长度的向量,这个过程通常通过循环神经网络(RNN),如长短期记忆网络(LSTM)或门控循环单元(GRU)来实现。这个固定长度的向量通常是一个隐藏状态(hidden state),它能够捕捉输入序列的上下文信息,并为解码器(Decoder)提供必要的信息来生成输出序列
- 对于一句话,虽然每个词被编码为固定长度的向量,但整个句子并不是简单地编码为一个矩阵。相反,句子中的每个词都有自己的向量表示,并且这些向量会通过模型进行处理,以生成最终的固定长度的向量表示。这个向量表示可以用于各种下游任务,如文本分类、情感分析等
也可以单独编码一句话
1 | sentence1_chinese = "我喜欢狗" |
已知句子的向量表示后,可以通过点积计算相似程度
1 | import numpy as np |
使用向量数据库
Langchain 集成了超过 30 个不同的向量存储库。我们选择 Chroma 是因为它轻量级且数据存储在内存中,这使得它非常容易启动和开始使用。
首先我们指定一个持久化路径:
1 | from langchain.vectorstores import Chroma persist_directory_chinese = 'docs/chroma/matplotlib/' |
接着从已加载的文档中创建一个向量数据库:
1 | vectordb_chinese = Chroma.from_documents( documents=splits, |
基于向量数据库进行相似的搜索
1 | question_chinese = "Matplotlib是什么?" |
1 | 第⼀回:Matplotlib 初相识 ⼀、认识matplotlib Matplotlib 是⼀个 Python 2D 绘图库,能够以多种硬拷⻉格式和跨平台的交互式环境⽣成出版物质量的 图形,⽤来绘制各种静态,动态, 交互式的图表。 Matplotlib 可⽤于 Python 脚本, Python 和 IPython Shell 、 Jupyter notebook , Web 应⽤程序服务器和各种图形⽤户界⾯⼯具包等。 Matplotlib 是 Python 数据可视化库中的泰⽃,它已经成为 python 中公认的数据可视化⼯具,我们所 熟知的 pandas 和 seaborn 的绘图接⼝ 其实也是基于 matplotlib 所作的⾼级封装。 为了对matplotlib 有更好的理解,让我们从⼀些最基本的概念开始认识它,再逐渐过渡到⼀些⾼级技巧中。 ⼆、⼀个最简单的绘图例⼦ Matplotlib 的图像是画在 figure (如 windows , jupyter 窗体)上的,每⼀个 figure ⼜包含 了⼀个或多个 axes (⼀个可以指定坐标系的⼦区 域)。最简单的创建 figure 以及 axes 的⽅式是通过 pyplot.subplots命令,创建 axes 以后,可以 使⽤ Axes.plot绘制最简易的折线图。 import matplotlib.pyplot as plt import matplotlib as mpl import numpy as np fig, ax = plt.subplots() # 创建⼀个包含⼀个 axes 的 figure ax.plot([1, 2, 3, 4], [1, 4, 2, 3]); # 绘制图像 Trick: 在jupyter notebook 中使⽤ matplotlib 时会发现,代码运⾏后⾃动打印出类似 <matplotlib.lines.Line2D at 0x23155916dc0> 这样⼀段话,这是因为 matplotlib 的绘图代码默认打印出最后⼀个对象。如果不想显示这句话,有以下三 种⽅法,在本章节的代码示例 中你能找到这三种⽅法的使⽤。 •. 在代码块最后加⼀个分号 ; |
在此之后,我们要确保通过运行 vectordb. Persist 来持久化向量数据库,以便我们在未来的课程中使用
1 | vectordb_chinese.persist() |
向量数据集通过向量相似度检索相似的 chunk,可能存在以下失败情况:
重复快
1 | question_chinese = "Matplotlib是什么?" docs_chinese = vectordb_chinese.similarity_search(question_chinese,k=5) |
请注意,我们得到了重复的块(因为索引中有重复的第一回:Matplotlib 初相识. Pdf )
检索错误答案
1 | question_chinese = "他们在第二讲中对Figure说了些什么?" docs_chinese = vectordb_chinese.similarity_search(question_chinese,k=5) for doc_chinese in docs_chinese: print(doc_chinese.metadata) |
1 | {'source': 'docs/matplotlib/第一回:Matplotlib初相识.pdf', 'page': 0} |