MobileNetv1:Efficient Convolutional Neural Networks for Mobile Vision Applications
在 VGG 的基础上,引入深度可分离卷积,降低模型参数量;并设计宽度因子、分辨率因子控制整个网络的规模
什么是 MobileNetv1?
![MobileNetv1-20230408140355]()
- 在 VGG 的基础上,引入深度可分离卷积,降低模型参数量
- 设计宽度因子和分辨率因子两个超参数的控制模型规模
MobileNetv1 的网络结构?
![MobileNetv1-20230408140356]()
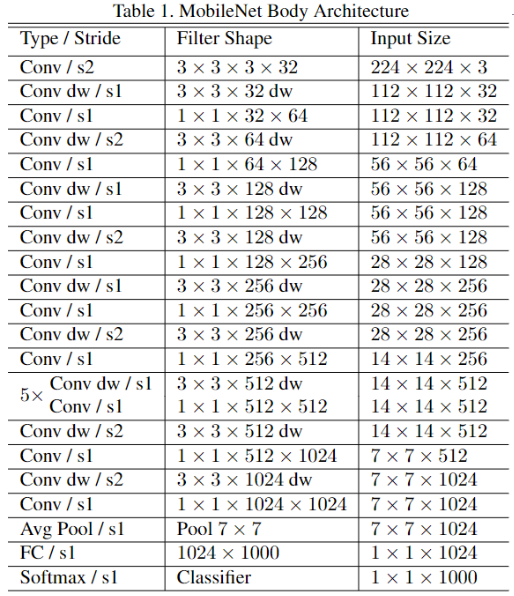
- 224x224x3 输入,1x1x1000 输出
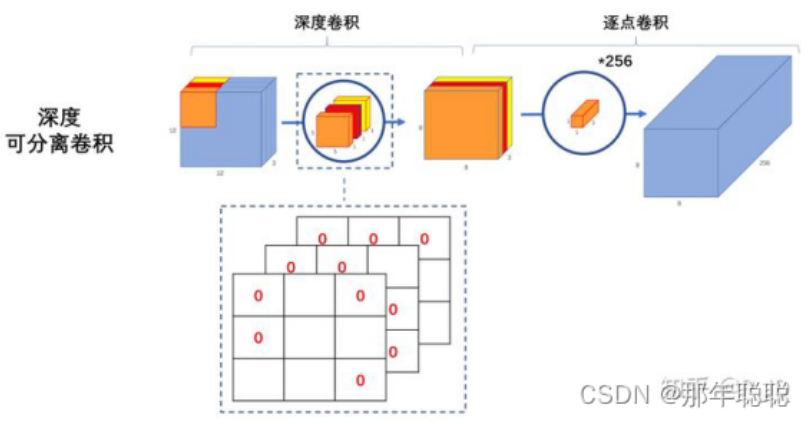
- VGG 中的标准卷积层换深度可分离卷积 (depthwise separable convolution) 就可以了。其核心思想是采用深度可分离卷积操作。在相同的权值参数数量的情况下,相较标准卷积操作,可以减少数倍的计算量,从而达到提升网络运算速度的目的
MobileNetv1 的宽度因子 (Width Multiplier)、分辨率因子 (Resolution Multiplier)?
![]()
- 上图左边是标准卷积和深度可分离卷积的过程,右边是使用宽度因子 、分辨率因子 后对网络计算量的影响
- 宽度因子:影响经过深度分离卷积 (DWConv) 后的通道数,通过影响点卷积输出的通道数实现,比如原始输出 16 个通道,现在假定 ,那么这个的输出通道变为 8 了。相比较原始输出,经过因子简化后的 DWConv 成本是原来的 1/ 倍
- 分辨率因子:影响经过 DWConv 后的分辨率,通过影响通道卷积的分辨率做到,比如原始输出分辨率 128 x 128,现在假定 ,那么 DWConv 的输出变为 64 x 64,相比较原始输出,经过因子简化后的 DWConv 成本是原来的 1/ 倍

MobileNetv1 的缺点?
![]()
- 深度可分类卷积存在很多值为 0 的卷积核:这是因为 Relu 的 “死亡神经元” 特点导致的
- 深度可分离卷积核的 Kernel 数取决于上一层的 Depth,无法随意改变