深度学习的模型训练
本文介绍神经网络的训练关键设置,包括 batchsize、初始化和学习率,尤其需要把握网络初始方法,不正确的初始化甚至导致模型无法收敛
什么是 batch size?
- 在神经网络的训练过程中的超参数,决定在一次训练中,要选取多少样本喂给神经网络,这个要选择的样本个数,就是 batch size
- batch size 的可取值范围为 1 到全体样本数。举个例子,传统的批量梯度下降 (Batch Gradient Descent, BGD) 就是采用了全部样本来进行训练和梯度更新,而它的变体随机梯度下降 (stochastic gradient descent, SGD) ,则设定 batch size 为 1,即每次只将一个样本喂给神经网络,在小批量梯度下降 (Mini-Batch Gradient Descent, MBGD) 中,则采用了一个折中的方法,每次选择一部分数据用于训练
batch size 大小对网络训练的影响?
- 合理增大: 加速网络训练速度,提高了内存利用率,大矩阵乘法并行计算效率提高;在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,震荡比较小
- 不合理增大:内存利用率提高了,但是内存容量可能撑不住了
- 不合理减小: 会导致每次计算的梯度不稳定,引起训练的震荡比较大,很难收敛
- Batch_Size 增大到某个时候,达到时间上的最优:因为随着 batchsize 增大,处理相同的数据量的速度越快,并且达到相同精度所需要的 epoch 数量越来越多
为什么 10000 样本训练 1 次会比 100 样本训练 100 次收敛慢呢?
- 假设样本真实的标准差为,则 n 个样本均值的标准差为 ,表明使用更多样本来估计梯度的方法回报是低于线性的
- 10000 个样本训练一次和 100 个样本训练一次,由于计算量是线性的,前者的计算量是后者的 100 倍,但均值标准差只比后者降低了 10 倍,那么在相同的计算量下(同样训练 10000 个样本),小样本的收敛速度是远快于使用整个样本集的
如何选择合理的 batch size?
- 更大的 batch size 会得到更精确的梯度估计值,但其估计梯度的回报是低于线性的
- 如果训练集较小,可以直接使用梯度下降法,batch size 等于样本集大小
- 在某些硬件上使用特定大小的数组时,运行时间会更少。尤其是在使用 GPU 时,通常使用 2 的幂数作为 batch size 可以获得更少的运行时间,通常 10 到 100,当有足够算力时,选取 32,64,128 或更小一些的 batch_size。算力不够时,在效率和泛化性之间做权衡,选择更小的 batch size
什么是参数初始化?
- 在网络模型训练之前,对各个节点的权重和偏置进行初始化赋值的过程
- 目的: 防止模型在通过深度神经网络的正向传递过程中爆炸或消失。如果发生这种情况,损失梯度将太大或太小而无法向后流动,并且网络将需要更长的时间来收敛
理想的参数初始化应该满足什么条件?
![]()
- 梯度不为 “零”:激活值的方差是逐层递减的,这导致反向传播中的梯度也逐层递减。要解决梯度消失,就要避免激活值方差的衰减,最理想的情况是,每层的输出值(激活值)保持高斯分布。梯度不为 0,反推神经网络各层激活值不会出现饱和现象且激活值不为 0
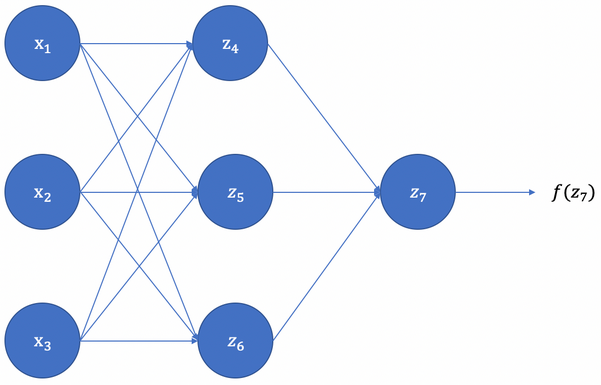
为什么权重零初始化不是一个好的初始化过程?
![]()
前向计算
z4、z5、z6 计算
由于权重和偏置的初始值都为 0,且同一层网络的激活函数相同,z4=z5=z6=0,也即激活值相等
神经网络的最终输出,
后向传播
根据反向传播算法和链式法则,计算损失函数对 的梯度
由于 , 则他们的梯度值相等
已知权重更新表达式为
所以,由于 均初始化为 0,则 ,同理,
由此可见,在反向传播的时候,不同维度的参数会得到相同的更新,因为他们的 gradient 相同,称之为 “对称失效”
为什么不能将权重全都初始化为同样的值?
- 如果每个权重都一样,那么在多层网络中,从第二层开始,每一层的输入值都是相同的了也就是 a1=a2=a3=…. ,既然都一样,就相当于一个输入了
- 更一般地说,如果权重初始化为同一个值,出现 神经网络的对称性 ,导致网络无法学习
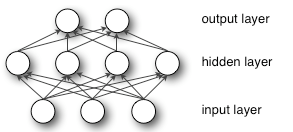
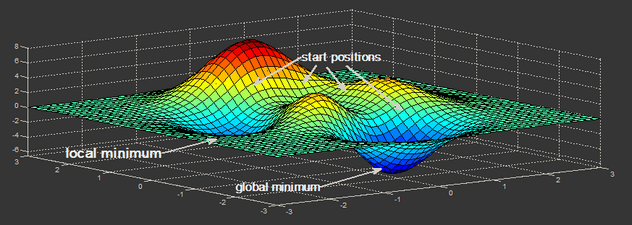
什么是神经网络的对称性?
![]()
- 假设现有多层感知器的前 2 层(输入层和隐藏层) ,在正向传播期间,隐藏层中的每个单元都会收到信号 ,假设您将所有权重初始化为相同的值(例如零或一)。在这种情况下,每个隐藏单元将获得完全相同的信号,初始化为 0 时甚至更糟,因为每个隐藏单位将获得零信号。无论输入什么,如果所有权重都相同这就是对称性
- 例子:想象一下有人将您从直升飞机上摔落到一个未知的山顶上,而您被困在那里。到处都是雾。您唯一知道的就是应该以某种方式下降到海平面。您应该朝哪个方向下降到最低点? 如果您找不到通往海平面的方法,那么直升机会再次将您带到山顶位置。您将不得不再次遵循相同的方向,因为您是在将自己 “初始化” 到相同的起始位置
![]()
- 将权重初始化为很小的数字是一个普遍的打破网络对称性的解决办法
神经元的参数之一偏差可以被初始化为 0 吗?
- 将偏差初始化为零是可能的,也是很常见的,因为破坏神经网络的对称性是由权重的小随机数解决的
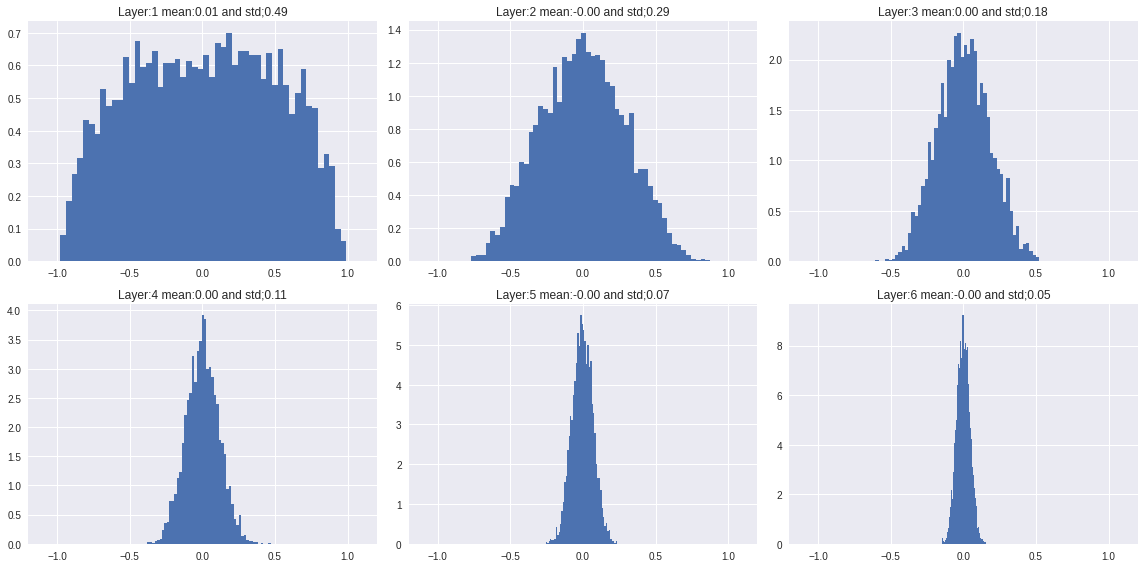
参数初始化的高斯正太分布?
![]()
- 按高斯正态分布 (normal) 初始化参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31linear1=torch.nn.Linear(2,3)
conv1.weight.data.fill_(0.00)
tensor([[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]]])
torch.nn.init.normal_(linear1.weight)
Parameter containing:
tensor([[-1.4311, 1.0712],
[ 1.2069, 0.1699],
[-0.2661, 0.1037]], requires_grad=True)
np.mean(linear1.weight.data.numpy()),np.std(linear1.weight.data.numpy())
(0.14242056, 0.8794779)
conv1 = torch.nn.Conv2d(2, 1, kernel_size=3)
conv1.weight.data.fill_(0.00)
tensor([[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]]])
torch.nn.init.normal_(conv1.weight,5)
Parameter containing:
tensor([[[[4.9785, 3.9322, 4.8189],
[5.5532, 5.1555, 4.9271],
[4.0945, 5.3474, 4.4982]],
[[4.7411, 5.6484, 5.8533],
[6.7415, 3.5681, 6.0705],
[5.2243, 5.6721, 5.5997]]]], requires_grad=True)
参数初始化的均匀分布?
- 按将参数初始化为均值为 0 的均匀分布 (uniform)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30linear1=torch.nn.Linear(2,3)
linear1.weight.data.fill_(0.00)
tensor([[0., 0.],
[0., 0.],
[0., 0.]])
torch.nn.init.uniform_(linear1.weight)
Parameter containing:
tensor([[0.8945, 0.9120],
[0.3414, 0.3397],
[0.2557, 0.9122]], requires_grad=True)
conv1 = torch.nn.Conv2d(2, 1, kernel_size=3)
conv1.weight.data.fill_(0.00)
tensor([[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]]])
torch.nn.init.uniform_(conv1.weight)
Parameter containing:
tensor([[[[0.0110, 0.4471, 0.0465],
[0.2804, 0.0238, 0.1004],
[0.3038, 0.6496, 0.4010]],
[[0.5599, 0.4826, 0.2687],
[0.0806, 0.8158, 0.6288],
[0.1309, 0.0462, 0.9910]]]], requires_grad=True)
np.mean(linear1.weight.data.numpy())
0.60925084
np.std(linear1.weight.data.numpy())
0.2983739
参数初始化的常量分布?
- 参数全部初始化为某个常数,意味着将所有计算单元初始化为完全相同的状态,无法破坏神经网络的对称性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29linear1=torch.nn.Linear(2,3)
conv1.weight.data.fill_(0.00)
tensor([[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]]])
torch.nn.init.constant_(linear1.weight,5)
Parameter containing:
tensor([[5., 5.],
[5., 5.],
[5., 5.]], requires_grad=True)
conv1 = torch.nn.Conv2d(2, 1, kernel_size=3)
conv1.weight.data.fill_(0.00)
tensor([[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]]])
torch.nn.init.constant_(conv1.weight,5)
Parameter containing:
tensor([[[[5., 5., 5.],
[5., 5., 5.],
[5., 5., 5.]],
[[5., 5., 5.],
[5., 5., 5.],
[5., 5., 5.]]]], requires_grad=True)
什么是 Xavier 参数初始化?
- 若 服从正态分布,则 ,d、u 为神经元输入、输出数量
- 若 服从均匀分布,则 ,d、u 为神经元输入、输出数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17linear1=torch.nn.Linear(2,3)
linear1.weight.data.fill_(0.00)
tensor([[0., 0.],
[0., 0.],
[0., 0.]])
torch.nn.init.xavier_normal(linear1.weight)
__main__:1: UserWarning: nn.init.xavier_normal is now deprecated in favor of nn.init.xavier_normal_.
Parameter containing:
tensor([[ 0.8893, 0.0135],
[ 0.7092, 0.3099],
[-0.0796, 0.3791]], requires_grad=True)
torch.nn.init.xavier_uniform(linear1.weight)
__main__:1: UserWarning: nn.init.xavier_uniform is now deprecated in favor of nn.init.xavier_uniform_.
Parameter containing:
tensor([[-1.0007, 0.0103],
[ 0.4184, 0.1838],
[-0.0314, 0.7926]], requires_grad=True)
什么是 Kaiming 参数初始化?
- Xavier 参数初始化的问题在于,它只适用于线性激活函数,但实际上,对于深层神经网络来说,今天的神经网络普遍使用 relu 激活函数,Kaiming 初始化就是针对 relu 的初始化
- 若 服从正态分布,则 ,d 为输入神经元的数量
- 若 服从均匀分布,则 ,d 为输入神经元的数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17linear1=torch.nn.Linear(2,3)
linear1.weight.data.fill_(0.00)
tensor([[0., 0.],
[0., 0.],
[0., 0.]])
torch.nn.init.kaiming_normal(linear1.weight)
__main__:1: UserWarning: nn.init.kaiming_normal is now deprecated in favor of nn.init.kaiming_normal_.
Parameter containing:
tensor([[ 0.1226, -1.1815],
[-2.3985, -0.9001],
[-0.2579, 1.1683]], requires_grad=True)
torch.nn.init.kaiming_uniform(linear1.weight)
__main__:1: UserWarning: nn.init.kaiming_uniform is now deprecated in favor of nn.init.kaiming_uniform_.
Parameter containing:
tensor([[-0.4304, -1.1726],
[-0.7944, 1.5579],
[-0.2283, 1.6357]], requires_grad=True)
什么是权重衰减 (weight decay)?
- 重衰减即 L2 正则化,目的是通过在 Loss 函数后加一个正则化项,通过使权重减小的方式,一定减少模型过拟合的问题
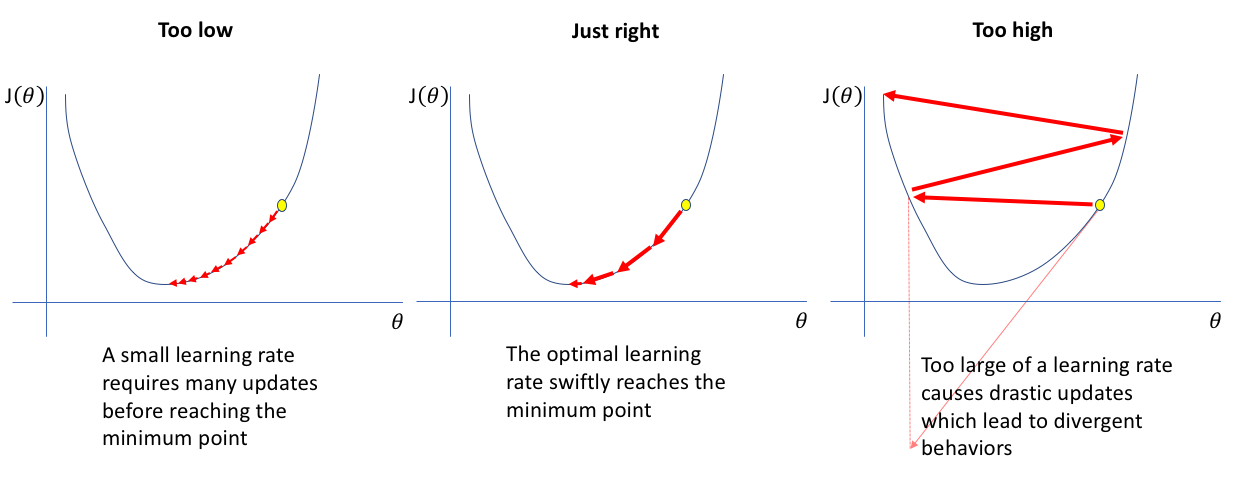
什么是学习速率 (learning rate)?
![深度学习的模型训练-20230704213133]()
- 学习率是训练神经网络的重要超参数之一,它代表在每一次迭代中梯度向损失函数最优解移动的步长(学习速率与梯度相乘称为梯度步长)
- 学习率过高过低,训练慢;过高,无法收敛,只有找到合适的学习率,才能保证代价函数以较快的速度逼近全局最优解
- 一般设置 0.1,0.01,0.001,0.0001,如果需要的话可以随着迭代次数增加而改变
什么是学习率预热 (warm-up)?
- 包括 Adam,RMSProp 等在内的自适应学习率优化器都存在陷入局部最优的风险 —— 初始学习率难以确定,较大的学习率可能导致模型训练不稳定
- ResNet 论文提出了一个对学习率的 warm-up 预热操作,在刚开始训练的时候先使用一个较小的学习率,训练一些 epoches,等模型稳定时再修改为预先设置的学习率进行训练
什么是学习率的 constant warmup?
- 这是 Resnet 论文训练模型的学习率优化方式,首先在 110 层的 ResNet 用 0.01 的学习率训练直到训练误差低于 80%(大概训练了 400 个 steps),然后使用 0.1 的学习率进行训练
- 不足: 从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大
什么是学习率的 gradual warmup?
- 克服 constant warmup 的学习率突变问题,从最初的小学习率开始,每个 step 增大一点点,直到达到最初设置的比较大的学习率时,采用最初设置的学习率进行训练
什么是学习率衰减?
- 在训练网络的前期过程中,会选取一个相对较大的学习率以加快网络的收敛速度。而随着迭代优化的次数增多,逐步减小学习率,以保证最终收敛至全局最优解,而不是在其附近震荡或爆炸,逐渐减小学习率的过程就是学习率衰减
- 常用到的学习率衰减方法:分段常数衰减 指数衰减 自然指数衰减 多项式衰减 余弦衰减
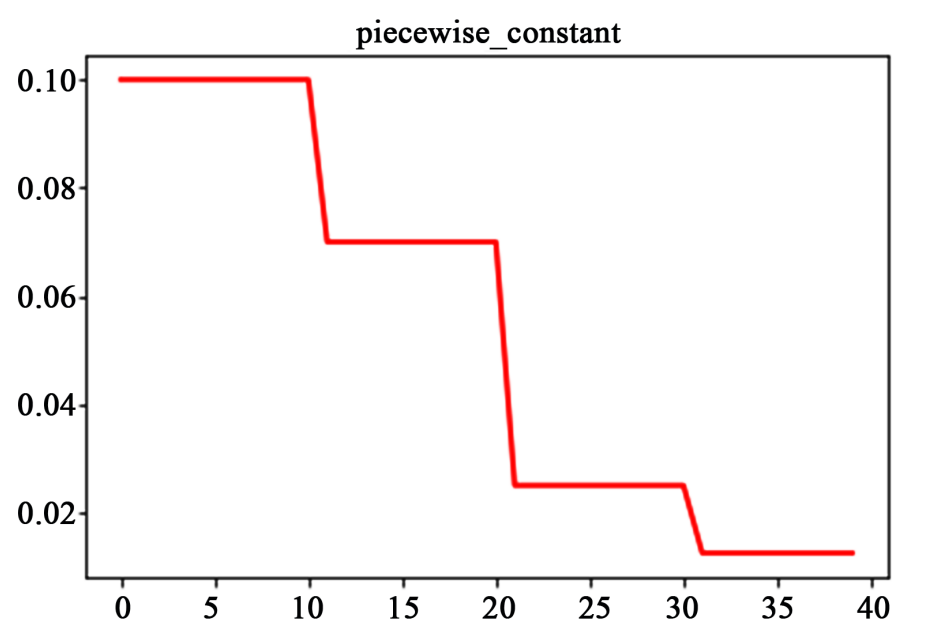
什么是学习率分段常数衰减?
![]()
- 按固定的训练 epoch 数进行学习率衰减
什么是多步段常数衰减?
- 当 epoch 数达到固定数值进行学习率衰减
什么是学习率指数衰减?
![]()
以指数衰减方式进行学习率的更新,学习率的大小和训练次数指数相关,其更新规则为
这种衰减方式简单直接,收敛速度快,是最常用的学习率衰减方式,如下图所示,绿色的为学习率随 训练次数的指数衰减方式,红色的即为分段常数衰减,它在一定的训练区间内保持学习率不变
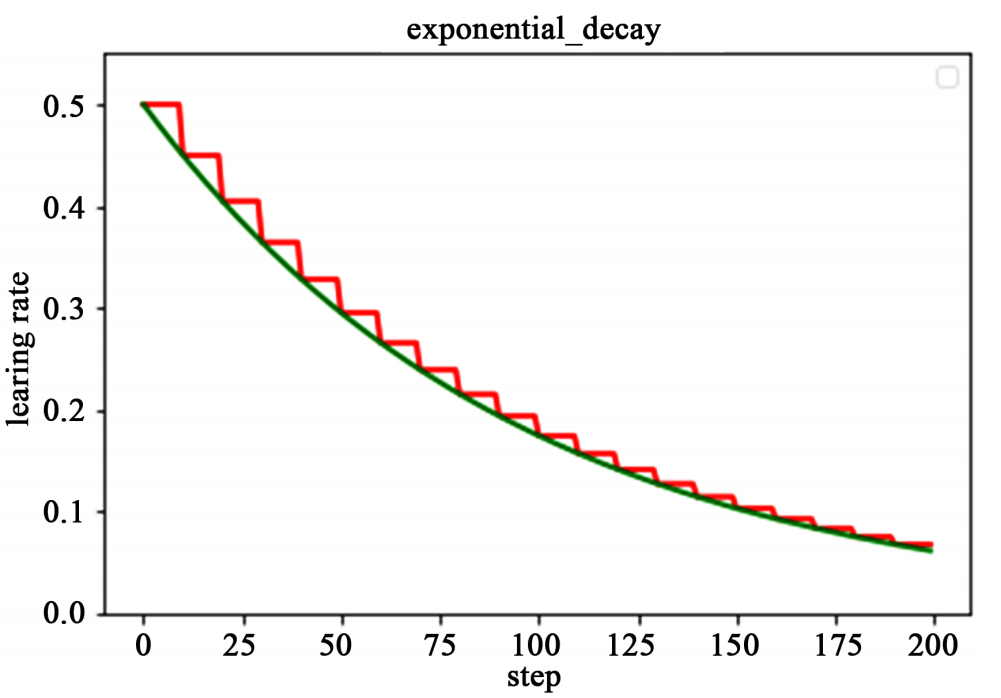
什么是学习率自然指数衰减?
![]()
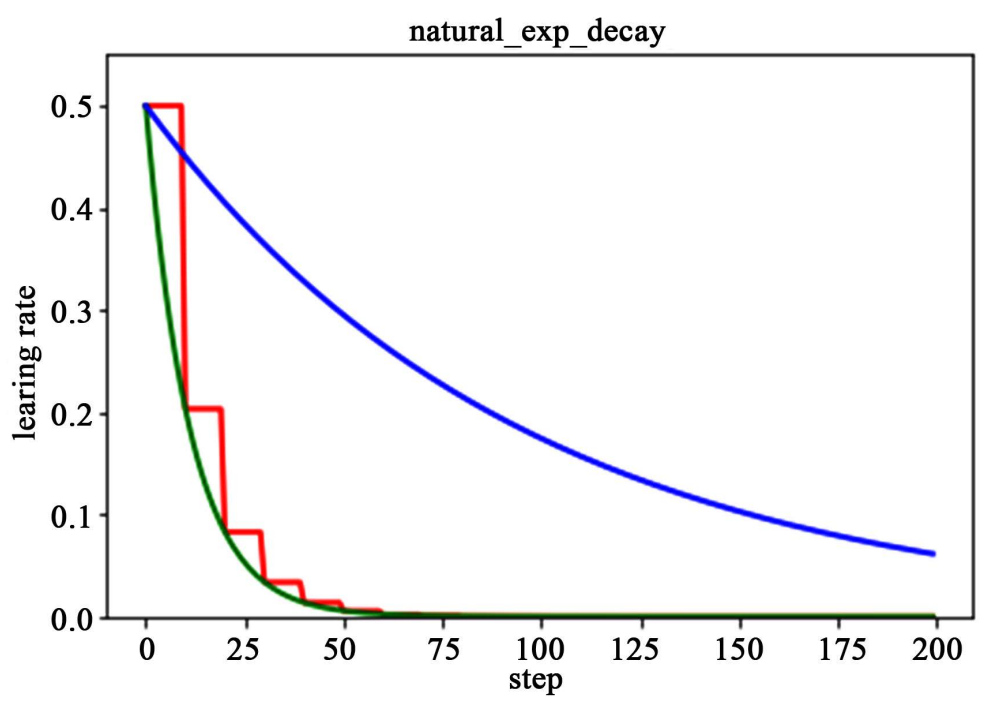
它与指数衰减方式相似,不同的在于它的衰减底数是,故而其收敛的速度更快,一般用于相对比较 容易训练的网络,便于较快的收敛,其更新规则如下
下图为为分段常数衰减、指数衰减、自然指数衰减三种方式的对比图,红色的即为分段常数衰减图,阶梯型曲线。蓝色线为指数衰减图,绿色即为自然指数衰减图,很明可以看到自然指数衰减方式下的学习率衰减程度要大于一般指数衰减方式,有助于更快的收敛
什么是学习率多项式衰减?
![]()
应用多项式衰减的方式进行更新学习率,这里会给定初始学习率和最低学习率取值,然后将会按照 给定的衰减方式将学习率从初始值衰减到最低值,其更新规则如下式所示
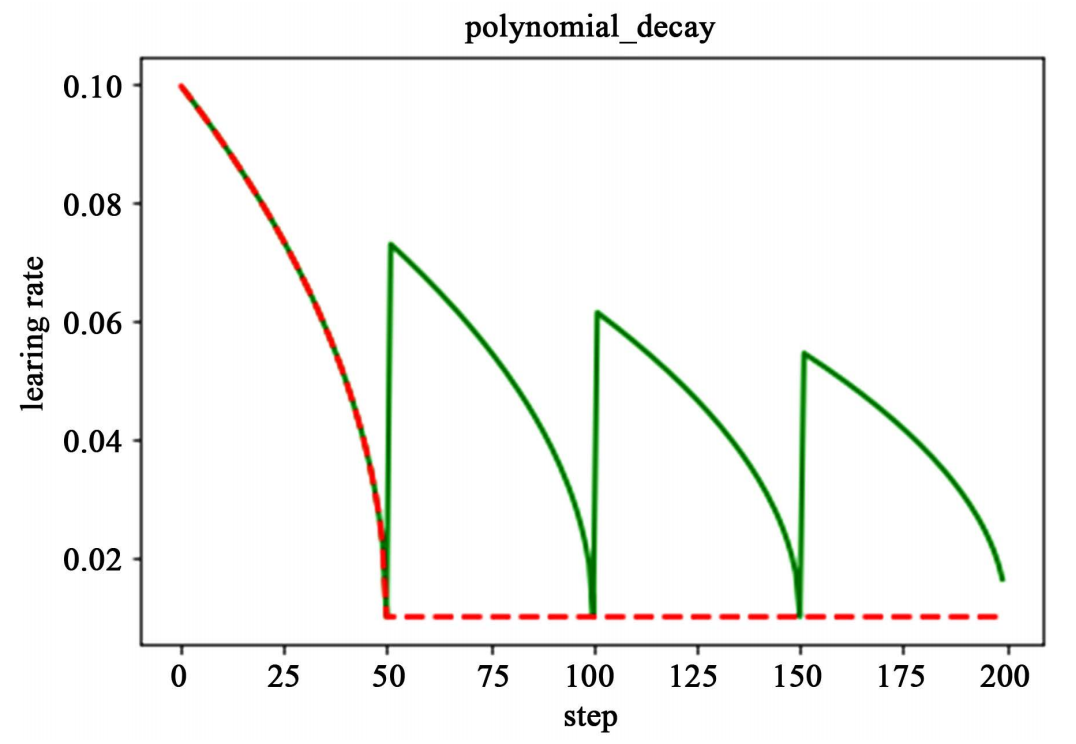
需要注意的是,有两个机制,降到最低学习率后,到训练结束可以一直使用最低学习率进行更新,另一个是再次将学习率调高,使用 decay_steps 的倍数,取第一个大于 global_steps 的结果,如下式所示。它是用来防止神经网络在训练的后期由于学习率过小而导致的网络一直在某个局部最小值附近震荡,这样可以通过在后期增大学习率跳出局部极小值
如下图所示,红色线代表学习率降低至最低后,一直保持学习率不变进行更新,绿色线代表学习率衰减到最低后,又会再次循环往复的升高降低
什么是学习率余弦衰减?
![]()
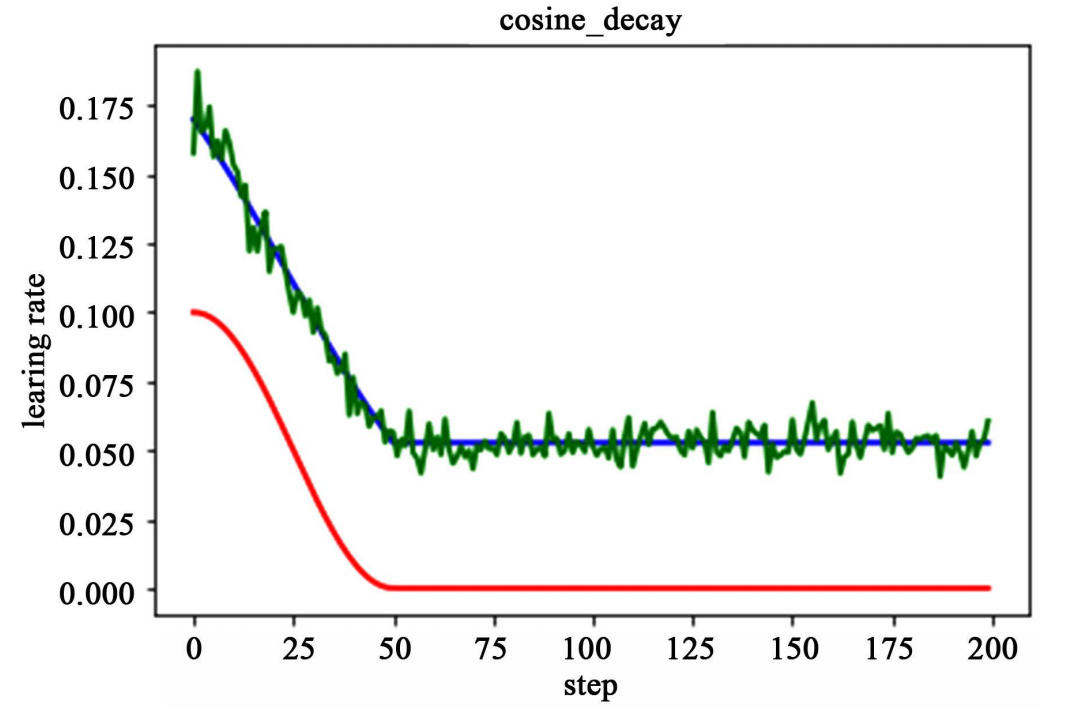
余弦衰减就是采用余弦的相关方式进行学习率的衰减,衰减图和余弦函数相似。其更新机制如下式所示
如下图所示,红色即为标准的余弦衰减曲线,学习率从初始值下降到最低学习率后保持不变。蓝色的线是线性余弦衰减方式曲线,它是学习率从初始学习率以线性的方式下降到最低学习率值。绿色噪声线性余弦衰减方式
什么是早停法 (early stopping)
- 一种正则化方法,是指在训练损失仍可以继续降低之前结束模型训练
- 使用早停法时,您会在验证数据集的损失开始增大(也就是泛化效果变差)时结束模型训练
什么是周期 (epoch)
- 在训练时,整个数据集的一次完整遍历,以便不漏掉任何一个样本。因此,一个周期表示(N / 批次大小)次训练迭代,其中 N 是样本总数
深度学习中常用的数据增强方法?
- Color Jittering:对颜色的数据增强:图像亮度、图像饱和度 (Saturation)、对比度变化(此处对色彩抖动的理解不知是否得当);
- PCA Jittering:首先按照 RGB 三个颜色通道计算均值和标准差,再在整个训练集上计算协方差矩阵,进行特征分解,得到特征向量和特征值,用来做 PCA Jittering;
- Random Scale:尺度变换;
- Random Crop:采用随机图像差值方式,对图像进行裁剪、缩放;包括 Scale Jittering 方法(VGG 及 ResNet 模型使用)或者尺度和长宽比增强变换;
- Horizontal/Vertical Flip:水平 / 垂直翻转;
- Shift:平移变换;
- Rotation/Reflection:旋转 / 仿射变换;
- Noise:高斯噪声、模糊处理;
- Label Shuffle:类别不平衡数据的增广;
小规模数据试炼?
- 在正式开始训练之前,可以先用小规模数据进行试练
- 可以验证自己的训练流程对否
- 可以观察收敛速度,帮助调整学习速率
- 查看 GPU 显存占用情况,最大化 batch_size (前提是进行了 batch normalization,只要显卡不爆,尽量挑大的)
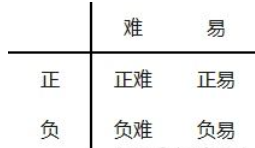
什么是难分负样本挖掘 (hard negative mining)?
![]()
- 根据难易和正负样本,可以将样本分成如下四类。难样本的 loss 大,但数量少,易样本的 loss 小,但数量多,loss 被易样本主导,从难样本上学习的少。模型稳定提升方向是提升对难样本的学习
- 难分负样本挖掘:选择最容易错误或错误最多的负样本加入训练集,相比加入全部负样本,这样训练更加容易
- 在目标检测方法中,无论是通过选择性搜索 (SelectiveSearch,SS) 还是 RPN,都会产生大量的先验框,这些先验框只有少部分被划分为正样本,所以存在大量的负样本,尤其是哪些靠近正样本的负样本很难区分,导致模型假阳率 (实际负样本被预测为正样本) 高
- 但是该方法不适合用于 end-to-end 模型,因为需要每次将网络冻结一段时间用来生成 hard negative,因此提出在线难负例挖掘 (Online hard negative mining,OHEM)
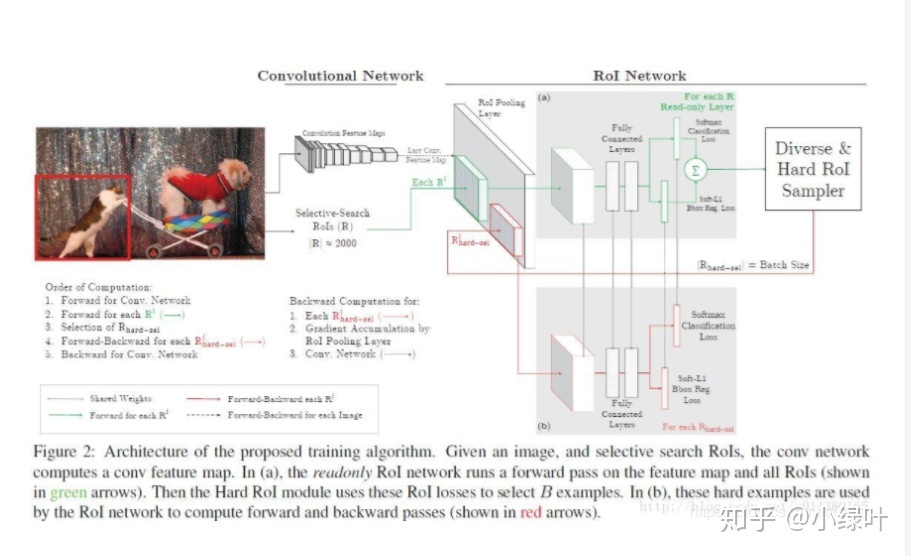
什么是在线难负例挖掘 (Online hard negative mining,OHEM)?
![]()
- 在模型训练中,大量的训练数据中会存在一些难以区分的负样本,找到这样的负样例再进行针对性地训练,能够对模型精度有一定的提升。例如 two-stage 目标检测中,往往生成大量的获选框,这些获选框负样本占大多数,所以正样本 -> 负样本的可能性更高,所以如果要 hard mining。通常使用的都是 hard negative mining
- 直接的 hard negative mining 不适用于 end-to-end 的模型。因为会大大降低模型的训练速度。OHEM 是一种线上的困难负样例挖掘解决方案,可以自动地选择 had negative 来进行训练,不仅效率高而且性能好
- 上图是 OHEM 应用到 Faster RCNN 的例子,即将原来的一个 ROI Network 扩充为两个 ROI Network,这两个 ROI Network 共享参数。其中前面一个 ROI Network 只有前向操作,主要用于计算损失;后面一个 ROI Network 包括前向和后向操作,以 hard example 作为输入,计算损失并回传梯度