YOLACT:Real-time Instance Segmentation
YOLACT (You Only Look At CoefficienTs) 是第一个用于实例分割的实时模型,首先通过类似目标检测模型生成 anchor 的预测结果 + 一批 prototype mask,然后根据 anchor 的结果线性组合 prototype mask 得到当前目标的 mask
什么是 yolact ?
![]()
- YOLACT (You Only Look At CoefficienTs) 是第一个用于实例分割的实时模型,首先通过类似目标检测模型生成 anchor 的预测结果 + 一批 prototype mask,然后根据 anchor 的结果线性组合 prototype mask 得到当前目标的 mask
- YOLACT 通过双分支预测目标位置、全局 Mask,然后通过目标检测分支的 mask coefficients 去关联全局 Mask,所以两个分支可以同时训练,所以是一个 one-satge 模型
- 如图所示,YOLACT 比 two-satge 的实例分割模型精度差,但是其在速度上有优势
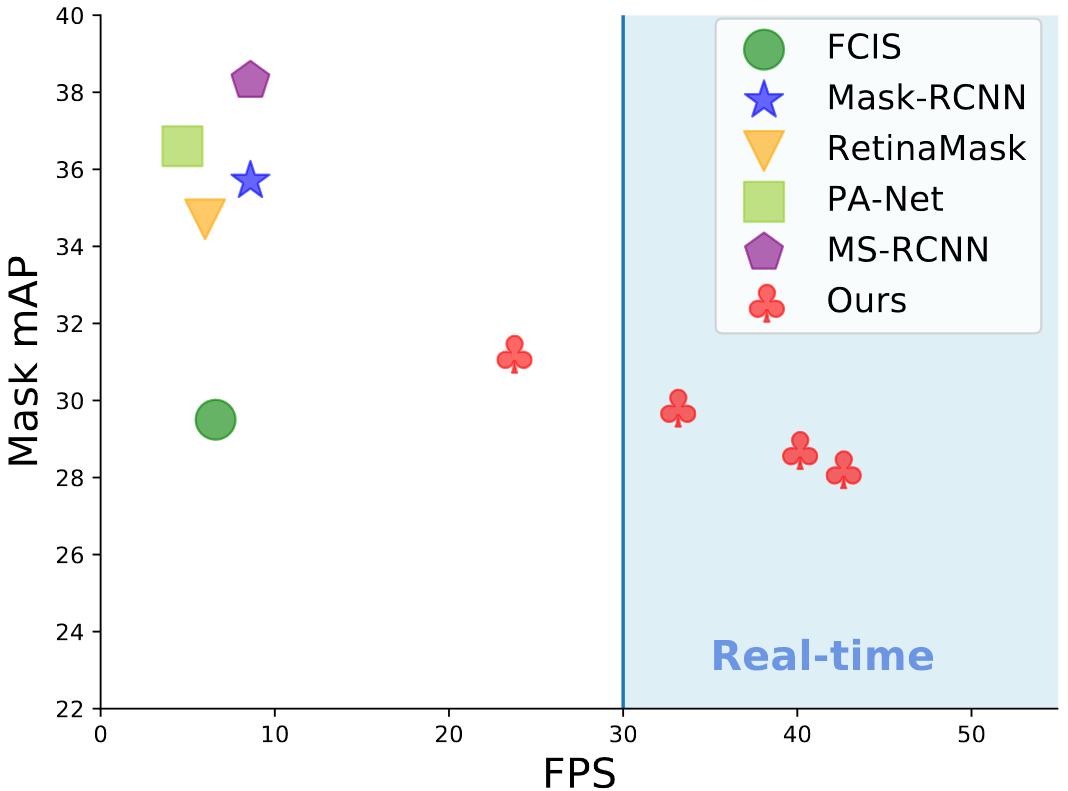
yolact 的网络结构?
![]()
- Featrue Backbone&Featrue Pyramid:使用 ResNet101 提取图片特征,然后使用 FPN 结构进行特征融合
- prototypes:从 P3 级别的特征生成全局的 prototype mask (138,138,32),这里固定是 32 个 mask,后续所有实例的 mask 是这 32 个 mask 的线性组合
- Mask coefficients:为每个 anchor 预测长度为 32 的向量,用于加权 prototypes,得到当前 anchor 的 mask 预测
- corp&Threashold:根据定位结果和 Mask 预测结果,裁剪目标区域,并使用二值化求得目标的 Mask
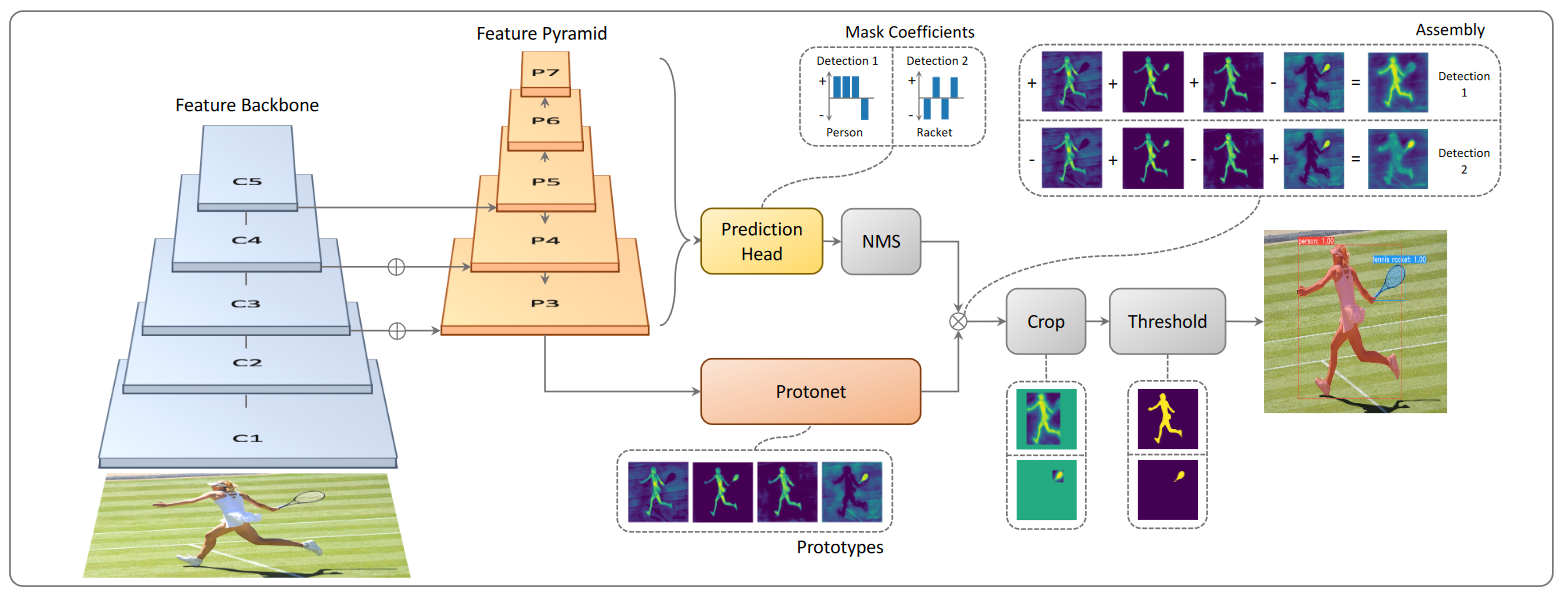
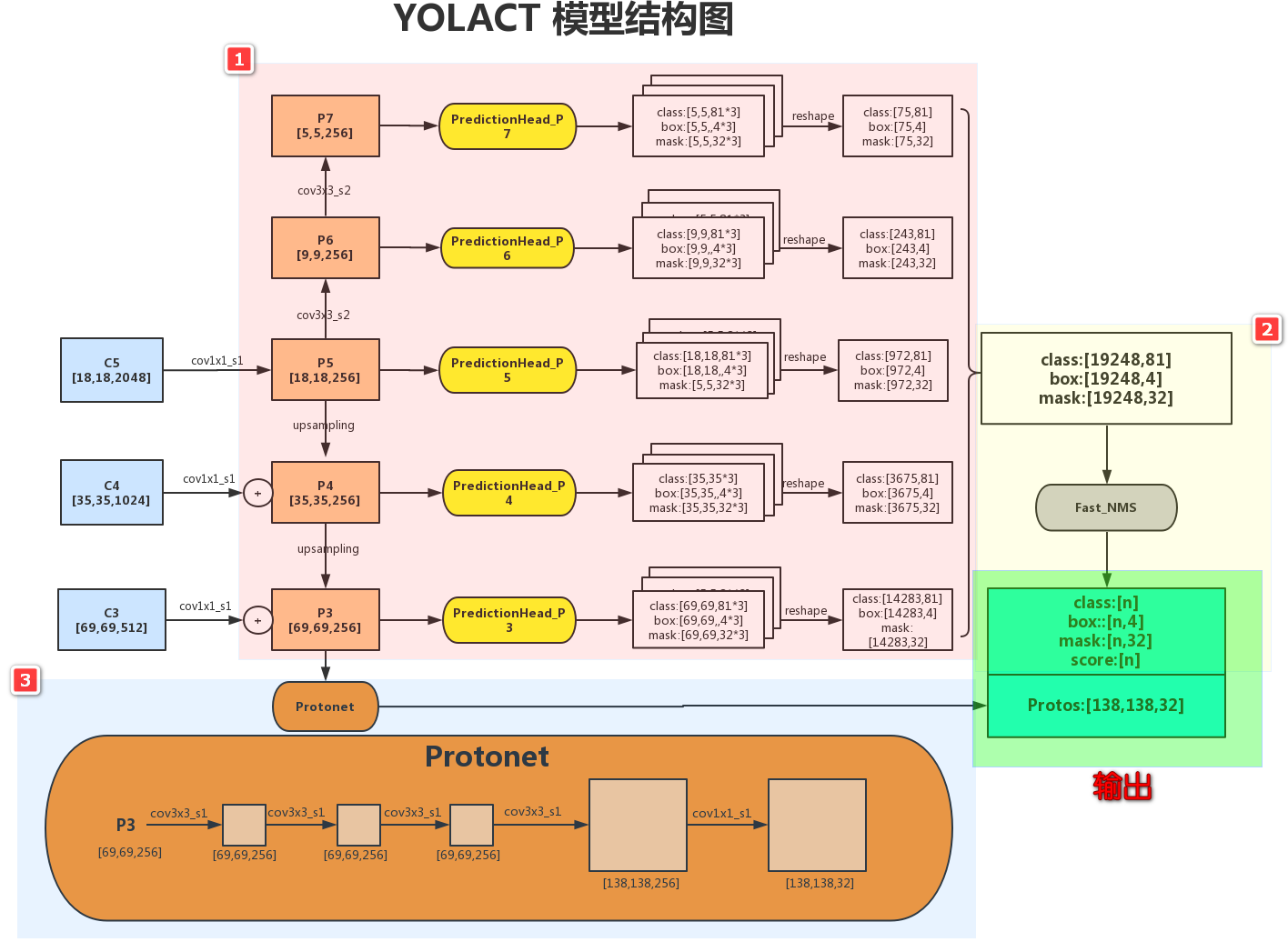
yolact 的数据流过程?
![]()
- 1)目标检测分支:对 P3-P7 的 5 个级别特征进行目标检测,每个位置检测 3 个 anchor。总计输出 19248 个 anchor 的预测结果
- 2)Fast NMS 处理:对 19248 个 anchor 进行快速非极大值抑制,假设最终保留 n 个预测 box
- 3)全局 Mask (prototypes) 生成:基于 P3 的特征,生成全局的 Mask (138,138,32)
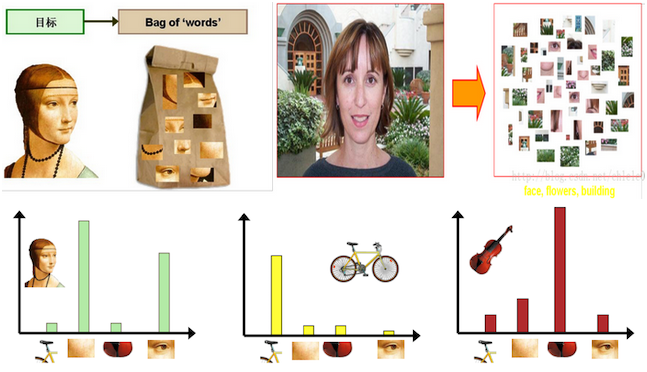
yolact 的 prototype masks 解析?
![]()
- YOLACT 实际上是学习了一种分布表示,在一张图片中可能有多个类别,但不同类别之间的物体共享 prototypes 的组合,如上图所示,每个 mask 激活图像的不同区域。除此之外,prototype masks 的数量与物体类别无关 (类别数量可能多于 prototypes 的数量)
- YOLACT 是针对每张图片学习 prototypes,即:不同图片生成的 prototypes 会有差异; BoF 对整个数据集所学习的全局共享的 prototypes,BOF 是一种图像特征提取方法,假设图像相当于一个文本,图像中的不同局部区域或特征可以看作是构成图像的词汇,根据得到的图像的词汇,统计每个单词的频次,即可得到图片的特征向量
![]()

yolact 的 Fast nms?
![]()
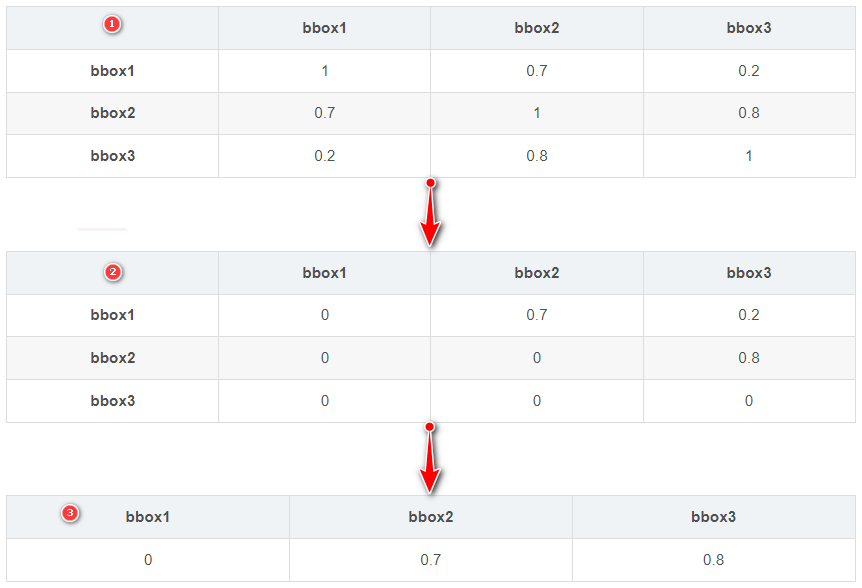
- 假设属于狗这一类目前有 3 个预测框,并且已经按得分降序排列,1 是预测框之间的
IoU值 - NMS:使用原始 NMS 时,首先选择 bbox1,然后根据 0.7>0.5 去掉 bbox2,最后选择 bbox3,因此最终输出 bbox1、bbox3
- Fast NMS:得到 1 的 IOU 阈值后,将 IOU 矩阵的下三角置 0,然后按列取最大值,如果列最大值超过阈值则去掉,否则保留,最终只有 bbox 1 保留。所以
fast-NMS倾向去掉更多的框 - Fast NMS 精度上比 NMS 有损失,但是速度却有很大提升
yolact 的模型输出解析?
![]()
- 1)获得 n 个目标的全局 Mask:模型最终输出如图所示,现在已经有 n 个目标的位置,后续需要解析出 n 个目标的 mask?首先已有全局 prototypes (M,138x 138 x 32) 和 Mask coefficients (C,nx 32),执行 ,也就是 n 个目标的全局 Mask 结果
- 2)细化目标 Mask:目标的全局 Mask 存在很多非目标区域的激活,因此为了准确,结合 box(n, 4)提取 M 目标区域的 Mask 值,然后通过 0.5 阈值对该区域二值化,即得到目标的 Mask
- 3)生成实例:结合目标位置 box 及目标 Mask 可以得到一张图片的所有实例
yolact 的损失函数?
- 根据 yolact 的输出,损失函数包含 3 部分,即类损失、box 定位损失、mask 损失
- 其中类别损失使用 smooth L1,box 损失使用 smooth L1,mask 损失使用二值化交差熵
参考: