DFANet:Deep Feature Aggregation for Real-Time Semantic Segmentation
DFANet 和当下多尺度融合模块设计不同,通过设计衔接上级网络输出的子网络,不断精修预测结果
什么是 DFANet?
![DFANet-20230408142801]()
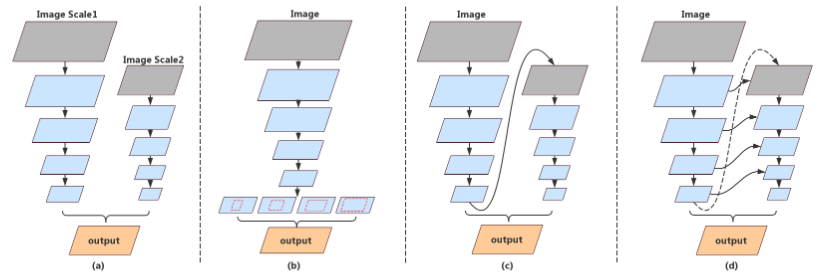
- 关于如何提升语义分割网络的多尺度能力,现有 4 种方法
- (a) 使用不同尺度的图片,改进网络的多尺度预测能力
- (b) 使用空间金字塔池化,提取高级语义上下文并增加感受野。但是通常很耗时
- © 首先通过对网络输出进行上采样,然后使用另一个子网完善特征图,类似多阶段精细花分割结果。但是,随着整个结构深度的增加,高维特征和感受野通常会遭受精度损失
- (d) c 的基础上增加同分辨率的跨连接,确保位置信息得到保留。相当于子网络不断接收上一级的输出,可以看成对结果不断精修
DFANet 的网络结构?
![DFANet-20230408142802]()
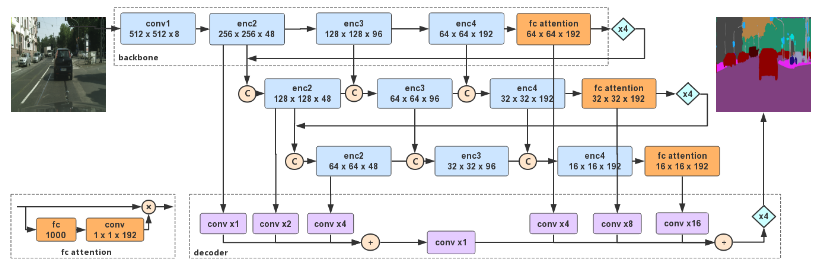
- Backbone:基本的主干是轻量级的 Xception 模型
- Decoder:对于实时推断,不会过多地专注于设计复杂的解码器模块。首先从编码器的三个主干网络浅层融合,然后再和高级表示融合。最后将高级特征双线性上采样 4 倍
DFANet 的深度特征融合?
![DFANet-20230408142804]()
- 聚合策略由子网聚合和子阶段聚合方法组成,上图第 2-3 行分别是 3 个子网络的输出,可以看出其结果越来越准确
- 子网聚合:将前一个主干的输出馈送到下一个主干,子网聚合可以看作是一种完善的过程
- 子阶段聚合:子阶段聚合的重点是在多个网络之间的阶段级融合语义和空间信息
