ONNX 入门学习
什么是 ONNX?
![]()
- 开放神经网络交换 ONNX(Open Neural Network Exchange)是一套表示深度神经网络模型的开放格式,由微软和 Facebook 于 2017 推出,然后迅速得到了各大厂商和框架的支持
- ONNX 是一个开放的生态系统,支持不同框架之间的互操作性,简化研究到生产的流程。它支持多种框架(如 TensorFlow、Pytorch、Keras、MxNet、MATLAB 等),这些框架中的模型可以转换为标准 ONNX 格式。采用 ONNX 格式的模型可以在各种平台和设备上运行。
- ONNX 定义了一组与环境和平台无关的标准格式,为模型之间的相互转换提供基础。如此,硬件和软件厂商只需针对 ONNX 进行优化模型性能,让所有兼容 ONNX 标准的框架受益。最终,开发者根据框架的特点及不同的开发阶段选择不同的架构,在部署时统一转换为 ONNX,速度更快

ONNX 文件 的数据结构分析?
- ONNX 文件是基于 Protobuf 进行序列化,在工程实践中,导出一个 ONNX 模型就是导出一个 ModelProto,它包含网络结构,网络权重等信息
- ModelProto:模型的定义,包含版本信息,生产者和 GraphProto
- GraphProto: 包含很多重复的 NodeProto, initializer, ValueInfoProto 等,这些元素共同构成一个计算图,在 GraphProto 中,这些元素都是以列表的方式存储,连接关系是通过 Node 之间的输入输出进行表达的
- NodeProto: onnx 的计算图是一个有向无环图 (DAG),NodeProto 定义算子类型,节点的输入输出,还包含属性
- ValueInforProto: 定义输入输出这类变量的类型
- TensorProto: 序列化的权重数据,包含数据的数据类型,shape 等
- AttributeProto: 具有名字的属性,可以存储基本的数据类型 (int, float, string, vector 等) 也可以存储 onnx 定义的数据结构 (TENSOR, GRAPH 等)
什么是 opset number?
- ONNX 的 opset number 是指操作符版本,ArgMin 在 opset 1 中被添加,在 opset 11, 12, 13 中被改变。有时,它被更新以扩展它支持的类型列表,有时,它将一个参数移动到输入列表中
- 用于部署模型的运行时不实现新版本,在这种情况下,模型必须通过通常使用运行时支持的最新的 opset 进行转换,我们称该 opset 为目标 opset。一个 ONNX 图只包含一个唯一的 opset,每个节点必须按照目标 opset 下最新的 opset 定义的规范进行描述
Pytorch 模型如何转为 ONNX?
- 使用 torch. Onnx. Export
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30model = test_model()
state = torch.load('test.pth')
model.load_state_dict(state['model'], strict=True)
model.eval()
# 单输入单输出
example = torch.rand(1, 3, 128, 128)
torch_out = torch.onnx.export(model,example,"test.onnx",
opset_version=9,
do_constant_folding=True,
export_params=True,
input_names = ['X'],
output_names = ['Y'])
# 多输入多输出()
input_tensor1 = torch.randn(1,4,400, 400).cuda()
input_tensor2 = torch.randn(1,2,3).cuda()
torch_onnx_out = torch.onnx.export(model,
(input_tensor1,input_tensor2), "hrocr.onnx",
export_params=True,
input_names=['input_tensor1','input_tensor2'],
output_names=["output0","output1"],
opset_version=12)
# 单输入单输出,动态维度
data = torch.rand(1, 3, 224, 224)
data = data.cuda()
torch.onnx._export(model, data, "xxx.onnx",
export_params=True,
opset_version=12,
input_names=["input"] ,
output_names=["output"] ,
dynamic_axes={'input':{0 : 'batch_size'}, 'out': {0 : 'batch_size'}})
Caffe 2 模型如何转为 ONNX?
1
2
3
4
5import caffe2.python.onnx.backend as backend
import numpy as np
rep = backend.prepare(model, device="CUDA:0") # or "CPU"
outputs = rep.run(np.random.randn(10, 3, 224, 224).astype(np.float32))
print(outputs[0])
Tensorflow 模型如何转为 ONNX?
- 导出 pb 文件
1 | # network |
- 使用 tf 2 onnx 将. Pb 转为 onnx
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24from tf2onnx import tfonnx
graph_def = tf.compat.v1.GraphDef()
with open(modelPathIn, 'rb') as f:
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def, name='')
inputs[:] = [i+":0" for i in inputs]
outputs[:] = [o+":0" for o in outputs]
newGraphModel_Optimized = tf_optimize(inputs, outputs, graph_def)
tf.compat.v1.reset_default_graph()
tf.import_graph_def(newGraphModel_Optimized, name='')
with tf.compat.v1.Session() as sess:
g = process_tf_graph(sess.graph,input_names=inputs,
output_names=outputs, inputs_as_nchw=inputs)
model_proto = g.make_model(modelPathOut)
checker = onnx.checker.check_model(model_proto)
tf2onnx.utils.save_onnx_model("./", "saved_model",
feed_dict={}, model_proto=model_proto)
# python -m tf2onnx.convert --graphdef model.pb --inputs=input:0
# --outputs=output:0 --output model.onnx
if(args.validate_onnx_runtime):
print("validating onnx runtime")
import onnxruntime as rt
sess = rt.InferenceSession("saved_model.onnx") - ONNX 转 pb
1 | import sys |
Keras 模型如何转 ONNX?
1
2
3
4
5
6
7
8
9
10from keras2onnx import convert_keras
# network
net = (..)
# convert model to ONNX
onnx_model = convert_keras(net,
name="example",
target_opset=9,
channel_first_inputs=None
)
onnx.save_model(onnx_model, "example.onnx")
使用 onnx. Helper 自定义网络?
- 以下根据 ONNX 的数据结构,尝试完全用 ONNX 的 Python API 构造一个描述线性函数
output=a*x+b的 ONNX 模型![]()
- 1)构造描述张量信息的
ValueInfoProto对象1
2
3
4
5
6
7import onnx
from onnx import helper
from onnx import TensorProto
a = helper.make_tensor_value_info('a', TensorProto.FLOAT, [10, 10])
x = helper.make_tensor_value_info('x', TensorProto.FLOAT, [10, 10])
b = helper.make_tensor_value_info('b', TensorProto.FLOAT, [10, 10])
output = helper.make_tensor_value_info('output', TensorProto.FLOAT, [10, 10]) - 2)构造算子节点信息
NodeProto对象1
2mul = helper.make_node('Mul', ['a', 'x'], ['c'])
add = helper.make_node('Add', ['c', 'b'], ['output']) - 3)构造计算图
GraphProto对象1
graph = helper.make_graph([mul, add], 'linear_func', [a, x, b], [output])
- 4)把计算图
GraphProto封装进模型ModelProto里1
2model = helper.make_model(graph)
check_model(model)
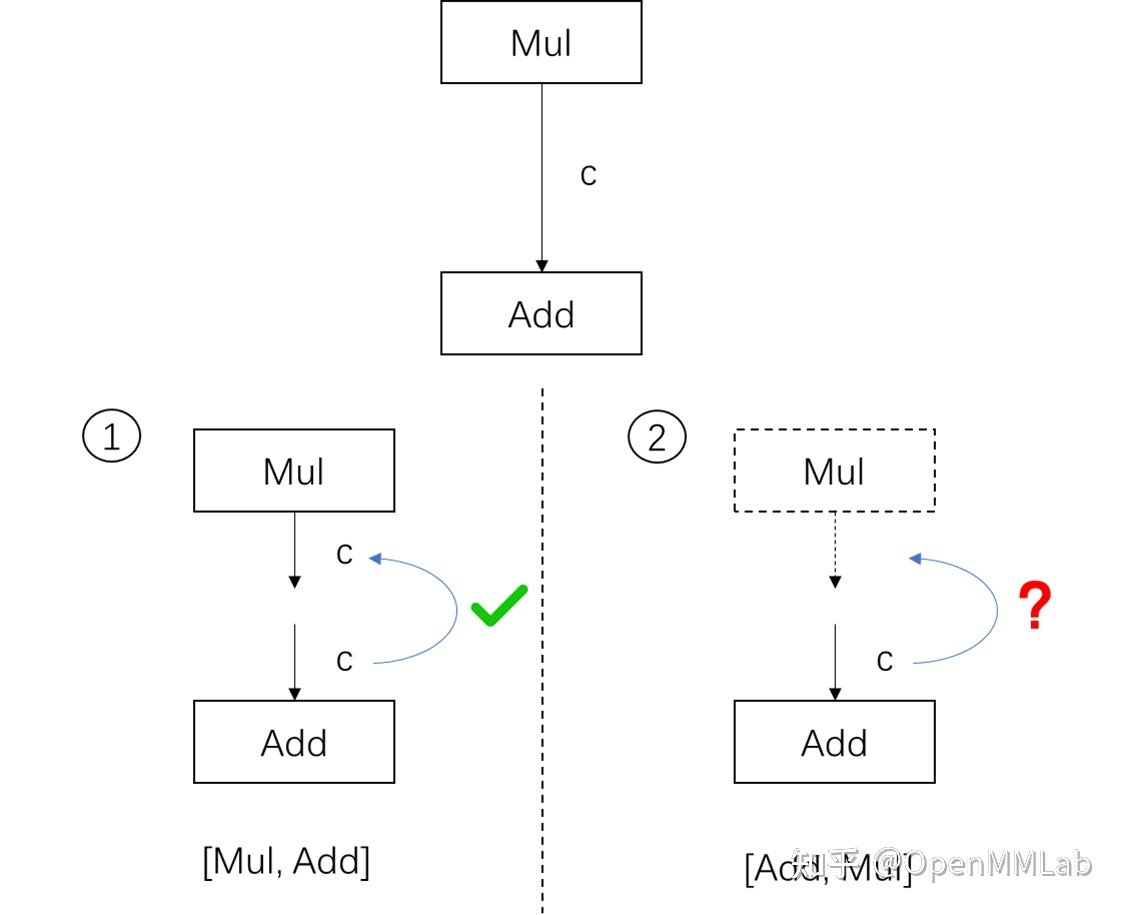
ONNX 的 infershape 接口的使用?
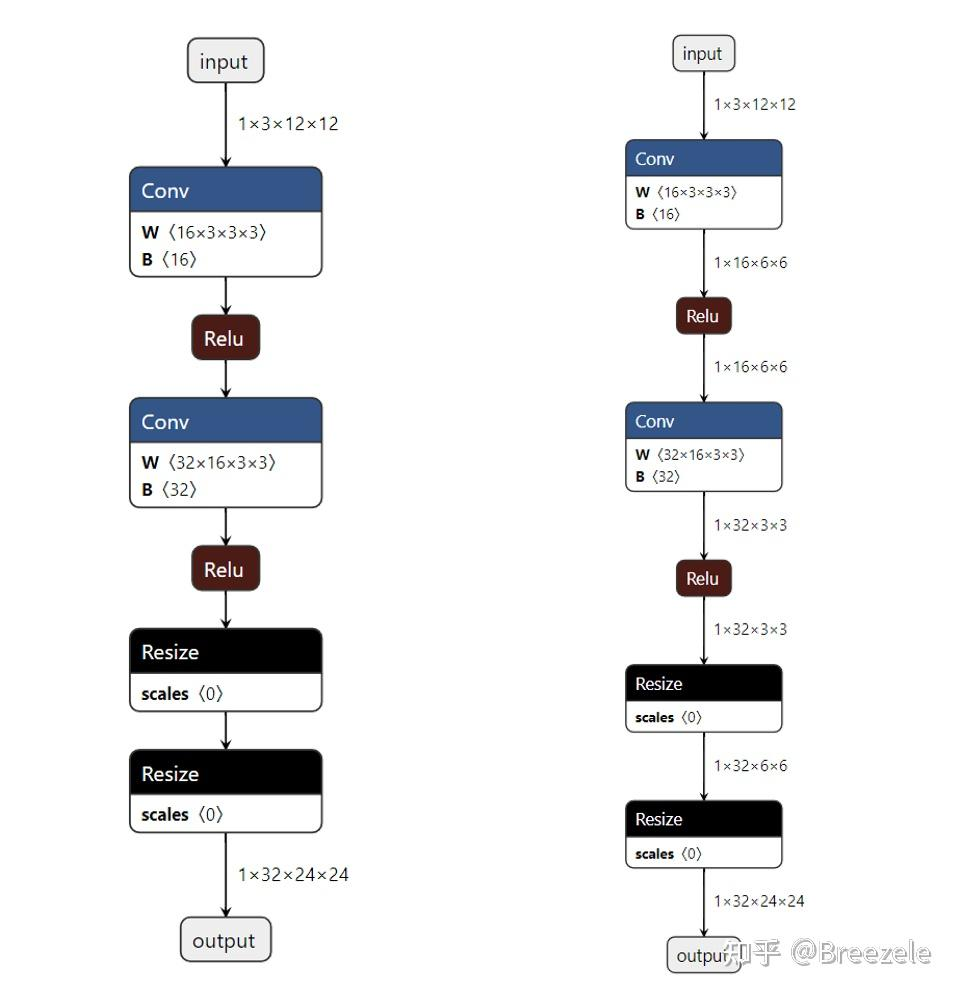
![]()
- 导出 ONNX 模型后,虽然可以通过 Netron 可视化该模型,能够看到模型的输入和输出尺寸,但是复杂的神经网络结构只显示整个网络输入输出的的尺寸,如果想观察 "每一层" 的尺寸,需要借助 infershape 接口
- 上图是调用 infer_shapes 接口前后的 onnx 结构,可以看出经过 infer_shapes 的 onnx 的没错输入输出都显示
- 先采用 Pytorch 框架搭建一个卷积网络,使用 torch.onnx.export () 将该模型导出,该例导出一个定长输入模型。直接调用 onnx 中的 infer_shapes 方法,将重新加载的模型进行形状推理,最后保存成一个新的模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25from onnx.shape_inference import infer_shapes
from onnx import load_model, save_model
import torch
import torch.nn as nn
class TestNet(nn.Module):
def __init__(self):
super(TestNet,self).__init__()
...
def forward(self, x):
...
return x
x=torch.randn((1,3,12,12))
model=TestNet()
model.eval()
output_onnx_name = 'test_net.onnx'
torch.onnx.export(model,
x,
output_onnx_name,
input_names=["input"],
output_names=["output"],
opset_version=11,
)
onnx_model = load_model(output_onnx_name)
onnx_model = infer_shapes(onnx_model)
save_model(onnx_model, "infered_test_net.onnx")
ONNX 支持 FP32 模型转换为 FP16 模型?
- FP16 又称半精度浮点数,不是 C++ 内置类型,详细查看: TensorRT 支持哪几种权重精度?
- Pytorch 导出时设置:FP16 导出只支持 GPU,改导出可在 tensorrt 生成引擎,且保持准确度
1
2
3
4
5
6
7
8input = torch.rand(1, 3, 513, 513).cuda().half()
model=model.cuda().half()
torch.onnx._export(model, input, "test.onnx",
export_params=True,
opset_version=12,
input_names=["input"] ,
output_names=["output"] ,
dynamic_axes={'input':{0 : 'batch_size'}, 'out': {0 : 'batch_size'}}) - 使用 onnxmltools 工具转换:转换过程是对 ONNX 模型上的权重进行截断处理,截断逻辑为:(1) 小于最小精度(默认 1e-7)映射为最小精度;(2) 大于最大范围(默认 1e4)映射为最大值;(3) NaN/0/inf/-inf 保持原值。该转换不确保在 tensorrt 生成推理引擎
1
2
3
4
5
6
7
8
9
10
11
12import onnxmltools
from onnxmltools.utils.float16_converter import convert_float_to_float16
# Update the input name and path for your ONNX model
input_onnx_model = 'model.onnx'
# Change this path to the output name and path for your float16 ONNX model
output_onnx_model = 'model_f16.onnx'
# Load your model
onnx_model = onnxmltools.utils.load_model(input_onnx_model)
# Convert tensor float type from your input ONNX model to tensor float16
onnx_model = convert_float_to_float16(onnx_model)
# Save as protobuf
onnxmltools.utils.save_model(onnx_model, output_onnx_model)
如何优化 ONNX 模型?
- 使用官方优化工具 optimizer
1
2
3
4
5
6
7
8
9import onnx
from onnx import optimizer
model_path = 'path/to/the/model.onnx'
original_model = onnx.load(model_path)
print('The model before optimization:\n{}'.format(original_model))
passes = ['fuse_consecutive_transposes']
optimized_model = optimizer.optimize(original_model, passes)
print('The model after optimization:\n{}'.format(optimized_model))
optimized_model = optimizer.optimize(original_model)
什么是 Protobuf
- Protobuf 是一种平台无关、语言无关、可扩展且轻便高效的序列化数据结构的协议,可以用于网络通信和数据存储可
- 以通过 protobuf 自己设计一种数据结构的协议,然后使用各种语言去读取或者写入,通常我们采用的语言就是 C++
参考: