TensorRT 多线程推理
tensorrt 多流推断概念理解?
- 同步:就是调用某个东西是,调用方得等待这个调用返回结果才能继续往后执行
- 异步: 和同步相反 调用方不会理解得到结果,而是在调用发出后调用者可用继续执行后续操作,被调用者通过状体来通知调用者,或者通过回调函数来处理这个调用
- FPS: Frames Per Second 更确切的解释是 “每秒钟处理图像的帧数(帧 / 秒)“
- Host Latency (本机推断耗时):单个推断请求的耗时
- Throughput (吞吐量):指系统在单位时间内处理请求的数量, 对于无并发的应用系统而言,吞吐量与响应时间成严格的反比关系,实际上此时吞吐量就是响应时间的倒数, 对于并发系统,通常需要用吞吐量作为性能指标
tensorrt 是否支持 1 个引擎的上下文实例进行多线程推理?
- 不支持
tensorrt 是否支持 1 个引擎的多个上下文实例进行多线程推理?
- 支持,但不是 100% 并行,tensorrt 内有并行瓶颈
如何使用 TensorRT 进行大规模上线?
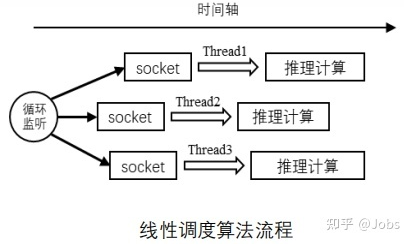
- 每个线程各自做各自的,互不影响。只适合 CPU 与小数据
![]()
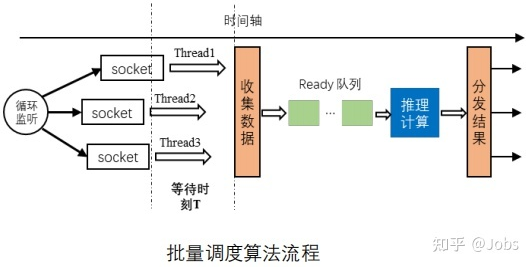
- 收集数据,重复利用 GPU 数据推理计算,分发结果。适合 GPU 与大数据
![]()
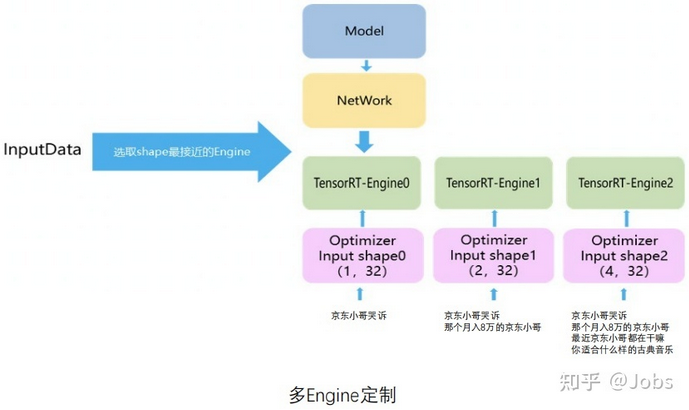
- 多 Engine 定制
![]()
参考: