机器学习的数据预处理方法
进行机器学习建模前的操作,其目地是确保模型能从数据中学到知识,包括去噪声、去冗余 (共线性)、降维以及样本数量处理
开始机器学习项目前,从哪些维度理解数据?
- 简单地查看数据
- 审查数据的维度
- 审查数据的类型和属性:数据属性的相关性是指数据的两个属性是否互相影响,以及这种影响是什么方式的等。非常通用的计算两个属性的相关性的方法是皮尔逊相关系数
- 总结查看数据分类的分布情况:在分类算法中,需要知道每个分类的数据大概有多少条记录,以及数据分布是否平衡。如果数据分布的平衡性很差,需要在数据加工阶段进行数据处理,来提高数据分布的平衡性
- 通过描述性统计分析数据
- 理解数据属性的相关性
- 审查数据的分布状况:通过分析数据的高斯分布情况来确认数据的偏离情况
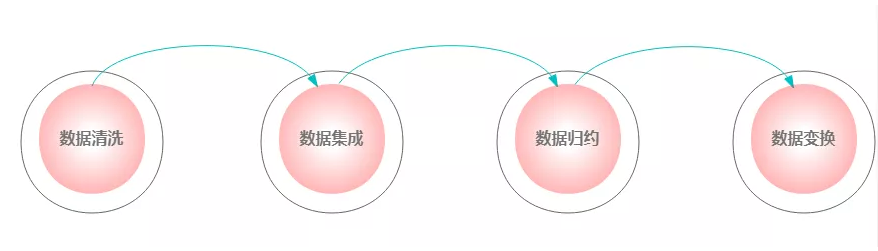
什么是数据预处理?
![]()
- 数据清洗:填写缺失值,处理噪声,检测离群点(异常值),处理离群点(异常值),处理重复值
- 数据集成:将多个数据源合并放到一个数据存储中
- 数据归约: 寻找依赖于发现目标的数据的有用特征,以缩减数据规模,从而在尽可能保持数据原貌的前提下,最大限度地精简数据量
- 数据变换:数据变换就是转化成适当的形式,来满足软件或分析理论的需要
为什么需要数据预处理?
- 数据处理相关的工作时间占据了整个项目的 70% 以上。数据的质量,直接决定了模型的预测和泛化能力的好坏,所以需要在挖掘前对数据进行预处理
- 原始数据通常存在以下问题
1
2
3
4
51.不一致:数据内含出现不一致情况
2.不完整 :感兴趣的属性没有
3.含噪声 : 数据中存在着错误、或异常(偏离期望值)的数据
4.重复
5.高维度 - 选择数据的原则
1
2
3
4
5
61.尽可能富余属性名和属性值明确的含义
2.统一多数据源的属性编码
3.去除唯一属性
4.去除重复属性
5.去除可忽略字段
6.合理选择关联字段
在数据清理过程中,如何处理重复值?
- 根据业务规则,判断重复值是否对问题求解有意义
- 如果没有意义,需要去重(删除)处理如果有意义,需要根据业务规则进行处理
在数据集成过程中,主要要解决的 3 个问题是?
- 同名异义,数据源 A 中某属性名字和数据源 B 中某属性名字相同,但所表示的实体不一样,不能作为关键字
- 异名同义,即两个数据源某个属性名字不一样但所代表的实体一样,可作为关键字
- 数据冗余,可能是同一属性多次出现,也可能是属性名字不一致导致的重复,对于重复属性一个先做相关分析检测,如果有再将其删除
数据规约的目的是什么,主要策略有哪些?
- 数据归约,也可称为维度规约,是指在对挖掘任务和数据本身内容理解的基础上、寻找依赖于发现目标的数据的有用特征,以缩减数据规模,从而在尽可能保持数据原貌的前提下,最大限度地精简数据量,进而降低无效错误的数据对建模的影响、缩减时间、降低存储数据的空间
- 维度规约主要包括属性规约 、数值规约
在数据规约中,如何进行属性规约?
- 去除低方差的特征
- 顺序特征选择 :包括前向特征选择和后向特征选择
- 主成份分析 (PCA) 算法
在数据规约中,如何进行数值规约?
- 相关系数、卡方检验:分析目标变量和单变量的相关性
- 回归系数:训练线性回归或逻辑回归,提取每个变量的表决系数,进行重要性排序
- 基尼系数 (Gini):训练决策树模型,提取每个变量的重要度,即 Gini 指数进行排序
- Lasso 回归正则化:训练回归模型时,加 L1 正则化参数,将特征向量稀疏化
- IV 指标:风控模型中,通常求解每个变量的 IV 值,来定义变量的重要度,一般将阀值设定在 0.02 以上
数据变换的主要内容有哪些?
- 归一化 (Normalization):又称为归一化,对属性数据按比例缩放,使之落入一个小的特定区间,剔除掉变量量纲上的影响
- 最大最小标准化:将数据映射 0,1] 区间,z-score 规范化(或零均值规范化):处理后的数据均值为 0,方差为 1,Log 函数的变换:在时间序列数据中,尤其是对于数据量级相差较大的变量
- 数据离散化:将连续的数据进行分段,使其变为一段段离散化的区间。分段的原则有基于等距离、等频率或优化的方法
什么是共线性问题?
- 解释变量之间由于存在相关关系而使模型估计失真或难以估计准确
为什么特征存在共线性导致模型参数波动大?
- 其实质是影响了参数 特征过多导致模型参数过多(参数越多)
- 特征存在共线性导致模型参数波动大(即参数不小): 可以证明,特征的方差与特征的相关性成正比,相关关系越大,其方差越大,即波动性越大
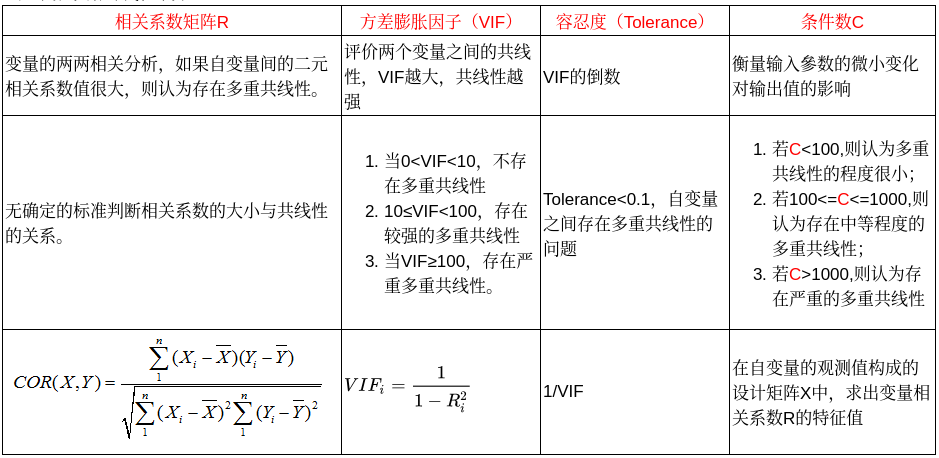
如何发现共线性问题?
如何解决共线性问题?
- 降维: 相当于将效果相同的特征属性合并,产生新的特征属性
- 正则化 (regularization): 相当于对于效果相同的特征属性,将部分特征属性的权重系数降低,通过这种方式来缓解多重共线性的问题,Ridge、Lasso 都可以解决共线性,尤其是 Lasso 回归
- 基顺序特征选择进行特征选择
什么独热编码(one-hot encoding)?
- 一种稀疏向量,其中: 一个元素设为 1,所有其他元素均设为 0。 独热编码常用于表示拥有有限个可能值的字符串或标识符。
- 例如,假设某个指定的植物学数据集记录了 15000 个不同的物种,其中每个物种都用独一无二的字符串标识符来表示。在特征工程过程中,您可能需要将这些字符串标识符编码为独热向量,向量的大小为 15000。
如何避免数据不平衡?
![]()
- 数据上的处理
- bootstrap (重采样):通过对训练集进行处理使其从不平衡的数据集变成平衡的数据集
- 上采样:把小种类复制多份
- 下采样:从大众类中剔除一些样本,或者说只从大众类中选取部分样本
- 数据合成 (数据增强): 利用已有样本生成更多样本,这类方法在小数据场景下有很多成功案例,比如医学图像分析等
- bootstrap (重采样):通过对训练集进行处理使其从不平衡的数据集变成平衡的数据集
- 模型上的处理
- 加权:设定惩罚因子,如 libsvm 等算法里设置的正负样本的权重项等。惩罚多样本类别,还可以加权少样本类别
- 装袋算法 (Bagging)、提升算法 (Boosting) 等方法
- 采用对不平衡数据集不敏感的算法
- 改变评价标准:AUC 值、ROC 曲线、F 值来进行评价
- 对于正负样本极不平衡的场景,看成一分类或者异常检测的问题
- 关于采样的认识
- 上采样和下采样都可以使数据集变得平衡,并且在数据足够多的情况下等价,但两者也是有区别的。实际应用中,如果计算资源足够且小众类样本足够多的情况下使用上采样,否则使用下采样,因为上采样会增加训练集的大小进而增加训练时间,同时小的训练集非常容易产过拟合 (overfitting)
- 对于下采样,如果计算资源相对较多且有良好的并行环境,应该选择 Ensemble 方法

在 sklearn 中,如何进行单标签任务的二值化?
- LabelBinarizer 是一个实用程序类,可帮助从多类标签列表创建标签指示矩阵
1
2
3
4
5
6
7
8
9>>> from sklearn import preprocessing
>>> lb = preprocessing.LabelBinarizer()
>>> lb.fit([1, 2, 6, 4, 2])
LabelBinarizer()
>>> lb.classes_
array([1, 2, 4, 6])
>>> lb.transform([1, 6])
array([[1, 0, 0, 0],
[0, 0, 0, 1]])
在 sklearn 中,如何进行多标签任务的二值化?
- 在多标签学习中,二进制分类任务的联合集用标签二进制指示符数组表示:每个样本是形状为 (n_samples, n_classes) 的二维数组中的一行,具有二进制值,其中一个(即非零元素)对应到该样本的标签子集。数组如表示第一个样本中的标签 0,第二个样本中的标签 1 和 2,第三个样本中没有标签
1
2
3
4
5
6
7
8>>> from sklearn.preprocessing import MultiLabelBinarizer
>>> y =[2, 3, 4],2],0, 1, 3],0, 1, 2, 3, 4],0, 1, 2]]
>>> MultiLabelBinarizer().fit_transform(y)
array([[0, 0, 1, 1, 1],
[0, 0, 1, 0, 0],
[1, 1, 0, 1, 0],
[1, 1, 1, 1, 1],
[1, 1, 1, 0, 0]])
在 sklearn 中,如何进行标签编码?
- LabelEncoder 是一个实用程序类,用于帮助规范化标签,使其仅包含 0 和 n_classes-1 之间的值
>>> le = preprocessing.LabelEncoder() >>> le.fit["paris", "paris", "tokyo", "amsterdam"]) LabelEncoder() >>> list(le.classes_) ['amsterdam', 'paris', 'tokyo'] >>> le.transform(["tokyo", "tokyo", "paris"]) [array2, 2, 1]) >>> list(le.inverse_transform([2, 2, 1])) ['tokyo', 'tokyo', 'paris']