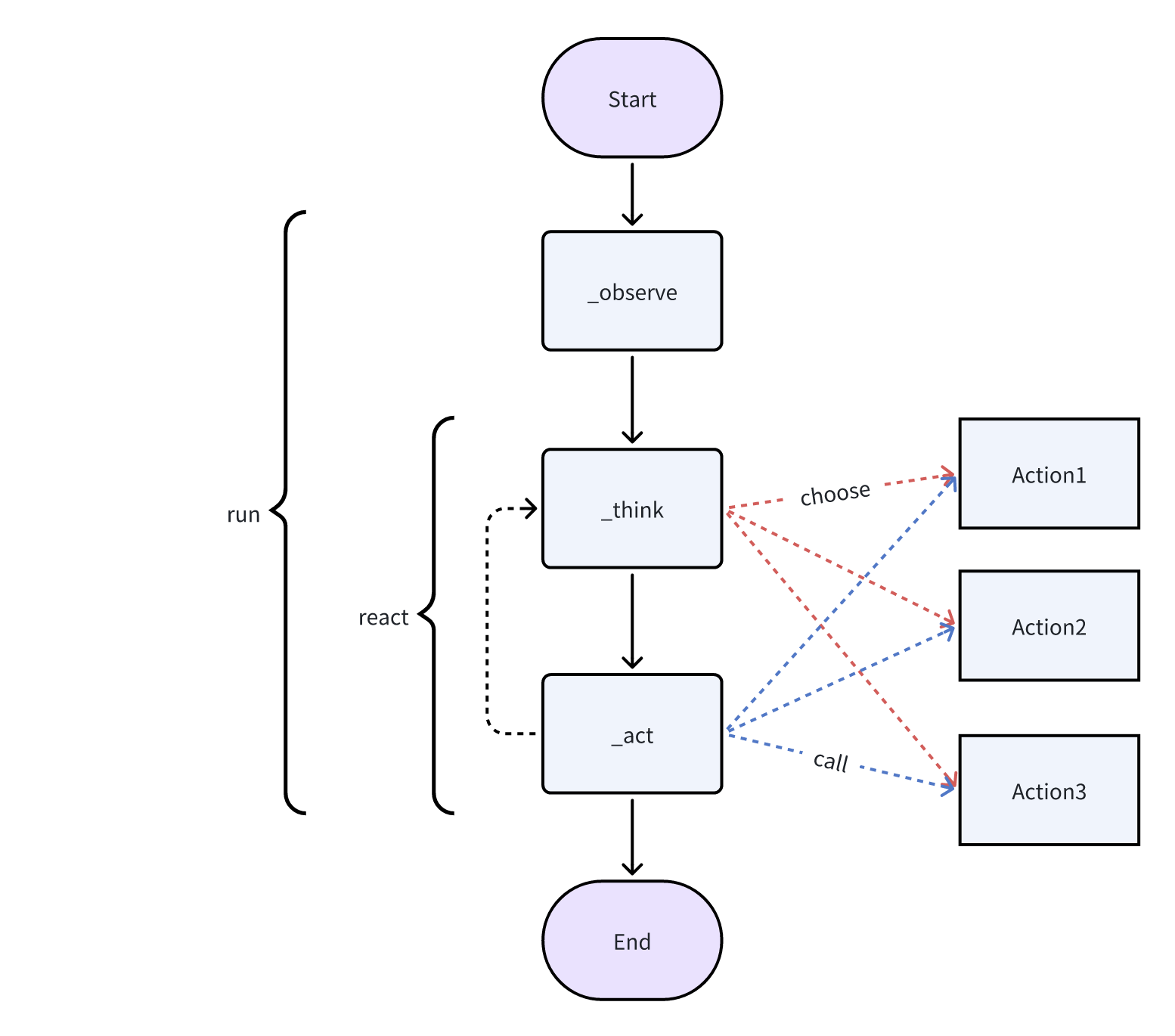
from metagpt.roles import Role from metagpt.schema import Message from metagpt.actions import UserRequirement classSimpleCoder(Role): name: str = "Alice" profile: str = "SimpleCoder" def__init__(self, **kwargs): super().__init__(**kwargs) self._watch([UserRequirement]) self.set_actions([SimpleWriteCode]) classSimpleTester(Role): name: str = "Bob" profile: str = "SimpleTester" def__init__(self, **kwargs): super().__init__(**kwargs) self.set_actions([SimpleWriteTest]) self._watch([SimpleWriteCode]) # self._watch([SimpleWriteCode, SimpleWriteReview]) # feel free to try this too asyncdef_act(self) -> Message: logger.info(f"{self._setting}: to do {self.rc.todo}({self.rc.todo.name})") todo = self.rc.todo # context = self.get_memories(k=1)[0].content # use the most recent memory as context context = self.get_memories() # use all memories as context code_text = await todo.run(context, k=5) # specify arguments msg = Message(content=code_text, role=self.profile, cause_by=type(todo)) return msg classSimpleReviewer(Role): name: str = "Charlie" profile: str = "SimpleReviewer" def__init__(self, **kwargs): super().__init__(**kwargs) self.set_actions([SimpleWriteReview]) self._watch([SimpleWriteTest])
import fire from metagpt.logs import logger from metagpt.team import Team asyncdefmain( idea: str = "write a function that calculates the product of a list", investment: float = 3.0, n_round: int = 5, ): logger.info(idea) team = Team() team.hire( [ SimpleCoder(), SimpleTester(), SimpleReviewer(), # SimpleReviewer(is_human=True), ] ) team.invest(investment=investment) team.run_project(idea) await team.run(n_round=n_round) if __name__ == "__main__": fire.Fire(main)
1 2 3 4 5 6 7 8 9 10 11 12 13
2024-12-13 11:18:07.884 | INFO | metagpt.const:get_metagpt_package_root:29 - Package root set to C:\CodeRepos\python\MyCode\Learnning_MetaGPT 2024-12-13 11:18:11.354 | INFO | __main__:main:127 - 写一个函数,能计算列表所有元素的乘积 2024-12-13 11:18:11.367 | INFO | metagpt.team:invest:90 - Investment: $3.0. 2024-12-13 11:18:11.375 | INFO | metagpt.roles.role:_act:391 - Alice(SimpleCoder): to do SimpleWriteCode(SimpleWriteCode) 2024-12-13 11:19:01.147 | WARNING | metagpt. Utils. Cost_manager:update_cost: 49 - Model qwen 2.5:14b not found in TOKEN_COSTS. 2024-12-13 11:19:01.156 | INFO | __main__:_act: 96 - Bob (SimpleTester): to do SimpleWriteTest (SimpleWriteTest) 2024-12-13 11:19:03.656 | WARNING | metagpt. Utils. Cost_manager:update_cost: 49 - Model qwen 2.5:14b not found in TOKEN_COSTS. 2024-12-13 11:19:03.662 | INFO | metagpt. Roles. Role:_act: 391 - Charlie (SimpleReviewer): to do SimpleWriteReview (SimpleWriteReview) 测试用例覆盖了多种情况,包括正数、负数、包含零的列表以及空列表和单元素列表。这有助于确保函数在各种输入下的正确性。 一个关键性的评论是:测试用例应该考虑到列表中可能存在的非整数值(如浮点数或复数),以验证函数是否能够处理这些情况并返回正确的 结果。例如,可以添加如下测试案例: 这将确保函数不仅限于整数列表,还能处理更广泛的数据类型。 2024-12-13 11:19:06.484 | WARNING | metagpt. Utils. Cost_manager:update_cost: 49 - Model qwen 2.5:14b not found in TOKEN_COSTS.